An async web scraping micro-framework based on asyncio.

Project description




Overview
An async web scraping micro-framework, written with asyncio and aiohttp, aims to make crawling url as convenient as possible.
Write less, run faster:
Documentation: 中文文档 |documentation
Organization: https://github.com/ruia-plugins
Features
Easy: Declarative programming
Fast: Powered by asyncio
Extensible: Middlewares and plugins
Powerful: JavaScript support
Installation
# For Linux & Mac
pip install -U ruia[uvloop]
# For Windows
pip install -U ruia
# New features
pip install git+https://github.com/howie6879/ruiaTutorials
Usage
Item
Item can be used standalone, for testing, and for tiny crawlers.
import asyncio
from ruia import AttrField, TextField, Item
class HackerNewsItem(Item):
target_item = TextField(css_select='tr.athing')
title = TextField(css_select='a.storylink')
url = AttrField(css_select='a.storylink', attr='href')
async def main():
async for item in HackerNewsItem.get_items(url="https://news.ycombinator.com/"):
print(item.title, item.url)
if __name__ == '__main__':
items = asyncio.run(main())Run: python demo.py
Notorious ‘Hijack Factory’ Shunned from Web https://krebsonsecurity.com/2018/07/notorious-hijack-factory-shunned-from-web/
......Spider Control
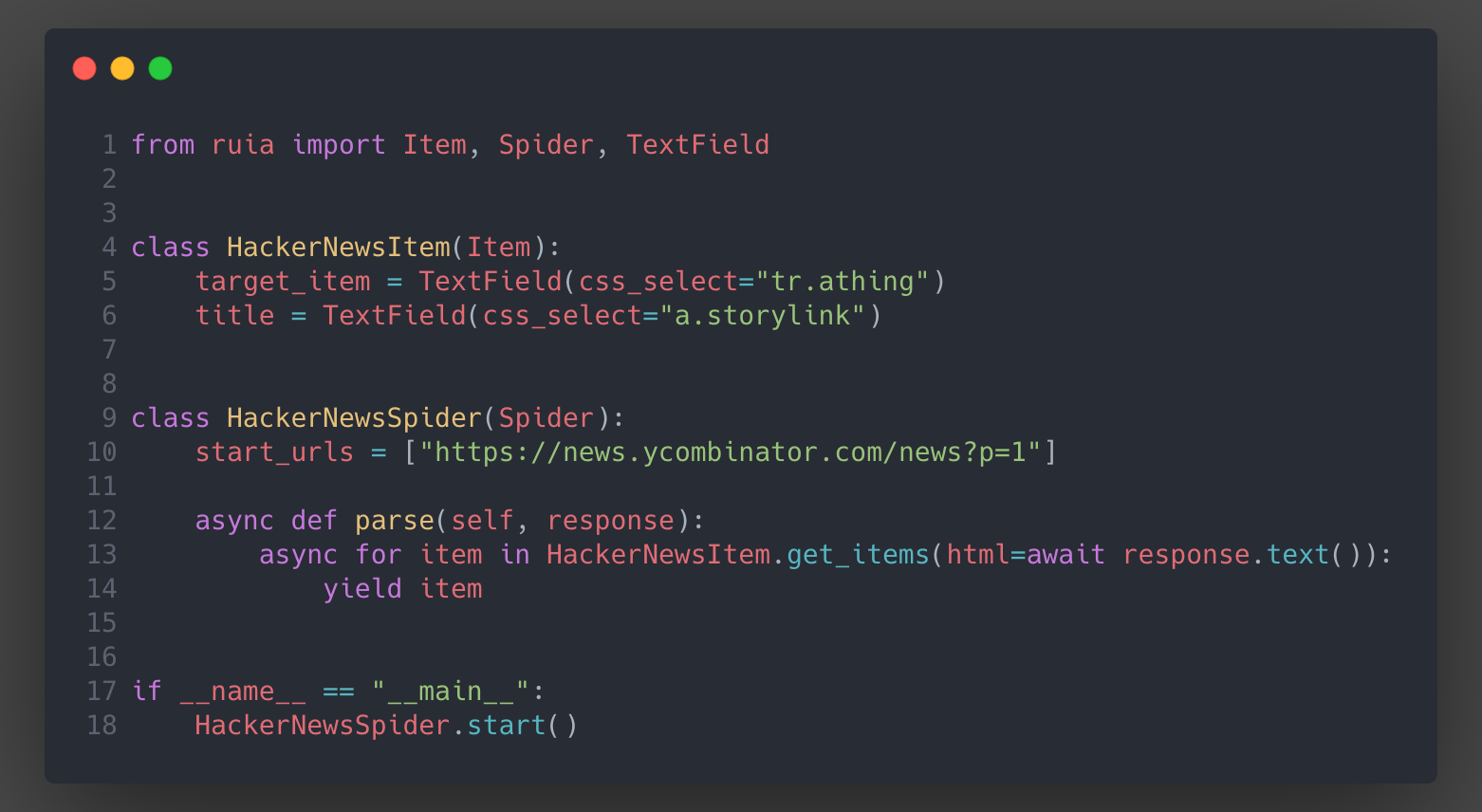
Spider is used for control requests better. Spider supports concurrency control, which is very important for spiders.
import aiofiles
from ruia import AttrField, TextField, Item, Spider
class HackerNewsItem(Item):
target_item = TextField(css_select='tr.athing')
title = TextField(css_select='a.storylink')
url = AttrField(css_select='a.storylink', attr='href')
async def clean_title(self, value):
"""Define clean_* functions for data cleaning"""
return value.strip()
class HackerNewsSpider(Spider):
start_urls = [f'https://news.ycombinator.com/news?p={index}' for index in range(1, 3)]
async def parse(self, response):
async for item in HackerNewsItem.get_items(html=response.html):
yield item
async def process_item(self, item: HackerNewsItem):
"""Ruia build-in method"""
async with aiofiles.open('./hacker_news.txt', 'a') as f:
await f.write(str(item.title) + '\n')
if __name__ == '__main__':
HackerNewsSpider.start()Run hacker_news_spider.py:
[2018-09-21 17:27:14,497]-ruia-INFO spider::l54: Spider started!
[2018-09-21 17:27:14,502]-Request-INFO request::l77: <GET: https://news.ycombinator.com/news?p=2>
[2018-09-21 17:27:14,527]-Request-INFO request::l77: <GET: https://news.ycombinator.com/news?p=1>
[2018-09-21 17:27:16,388]-ruia-INFO spider::l122: Stopping spider: ruia
[2018-09-21 17:27:16,389]-ruia-INFO spider::l68: Total requests: 2
[2018-09-21 17:27:16,389]-ruia-INFO spider::l71: Time usage: 0:00:01.891688
[2018-09-21 17:27:16,389]-ruia-INFO spider::l72: Spider finished!Custom middleware
ruia provides an easy way to customize requests.
The following middleware is based on the above example:
from ruia import Middleware
middleware = Middleware()
@middleware.request
async def print_on_request(request):
request.metadata = {
'index': request.url.split('=')[-1]
}
print(f"request: {request.metadata}")
# Just operate request object, and do not return anything.
@middleware.response
async def print_on_response(request, response):
print(f"response: {response.metadata}")
# Add HackerNewsSpider
if __name__ == '__main__':
HackerNewsSpider.start(middleware=middleware)JavaScript Support
You can load js by using ruia-pyppeteer.
For example:
import asyncio
from ruia_pyppeteer import PyppeteerRequest as Request
request = Request("https://www.jianshu.com/", load_js=True)
response = asyncio.run(request.fetch()) # Python 3.7
print(response.html)TODO
Cache for debug, to decreasing request limitation
Distributed crawling/scraping
Contribution
Ruia is still under developing, feel free to open issues and pull requests:
Report or fix bugs
Require or publish plugins
Write or fix documentation
Add test cases
Thanks
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file ruia-0.4.4.tar.gz.
File metadata
- Download URL: ruia-0.4.4.tar.gz
- Upload date:
- Size: 18.1 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.4.2 requests/2.21.0 setuptools/40.6.2 requests-toolbelt/0.8.0 tqdm/4.26.0 CPython/3.6.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3783c9fe0fd42a3afb89201d316e0f35520d7cdeb9853e270902cd6b1f3bdf4f
|
|
| MD5 |
2028edaf23548acafcfc852e9ce7d5e7
|
|
| BLAKE2b-256 |
2f3ca13d5b372cd33823f8fbc757dbcbd8c3bda04fa3cab598c8b15dd7b65a6e
|
File details
Details for the file ruia-0.4.4-py2.py3-none-any.whl.
File metadata
- Download URL: ruia-0.4.4-py2.py3-none-any.whl
- Upload date:
- Size: 21.4 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/1.12.1 pkginfo/1.4.2 requests/2.21.0 setuptools/40.6.2 requests-toolbelt/0.8.0 tqdm/4.26.0 CPython/3.6.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4d2dcdbb5e2aa0d1424b240d53a727e43cf49bce8e92f5f89d54a6f66fb42a26
|
|
| MD5 |
b72e87dd1a68d3a9c3be09d1ec0e4928
|
|
| BLAKE2b-256 |
e1958c9035cc200ded37234dbc10836b09a176f1bf9dec3dd0abbe25b3883002
|







