Format-agnostic parser for Illumina SampleSheet.csv files — supports IEM V1 and BCLConvert V2

Project description
samplesheet-parser
Format-agnostic parser for Illumina SampleSheet.csv files.
Supports both the classic IEM V1 format (bcl2fastq era) and the modern BCLConvert V2 format (NovaSeq X series) — with automatic format detection, bidirectional conversion, index validation, Hamming distance checking, diff comparison, and programmatic sheet creation.





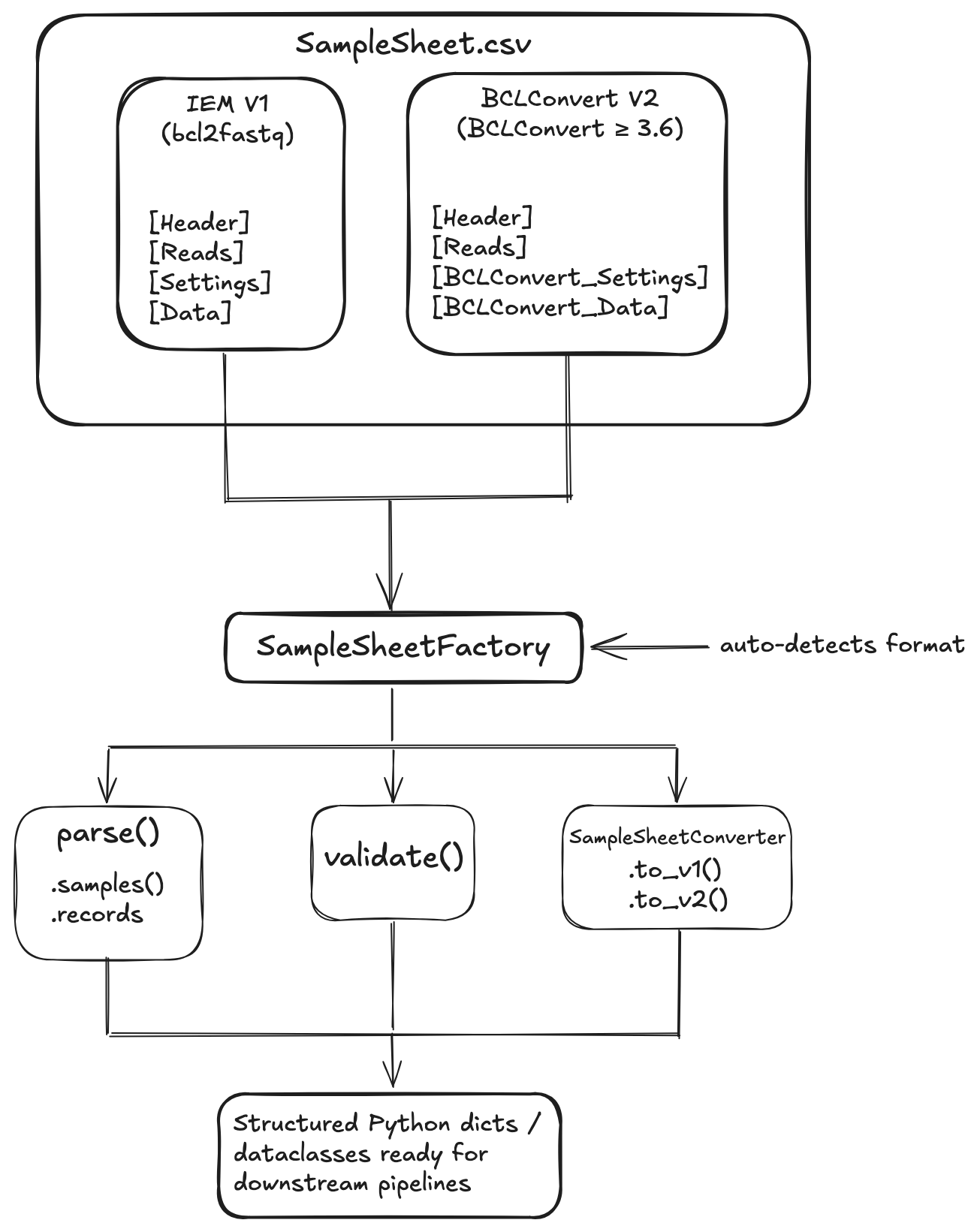
SampleSheetFactory auto-detects the format and routes to the correct parser. Both formats share a common interface — SampleSheetConverter handles bidirectional conversion, SampleSheetValidator catches index and adapter issues, SampleSheetDiff compares two sheets across any combination of V1/V2 formats, and SampleSheetWriter builds or edits sheets programmatically.
The problem this solves
Labs running mixed instrument fleets — older NovaSeq 6000 alongside newer NovaSeq X series — produce two incompatible SampleSheet formats. BCLConvert V2 sheets use [BCLConvert_Settings] / [BCLConvert_Data] sections, OverrideCycles for UMI encoding, and FileFormatVersion in the header. IEM V1 sheets use IEMFileVersion and a flat [Data] section.
Existing tools either hard-code one format or require the caller to know which format they have. samplesheet-parser auto-detects the format, exposes a consistent interface for both, converts between formats, validates index integrity (including Hamming distance), diffs sheets to catch accidental changes before a run starts, and writes new sheets programmatically — so you never have to hand-edit a CSV again.
Installation
pip install samplesheet-parser
Requires Python 3.10+. No mandatory dependencies beyond loguru.
Quickstart
Auto-detect format (recommended)
from samplesheet_parser import SampleSheetFactory
factory = SampleSheetFactory()
sheet = factory.create_parser("SampleSheet.csv", parse=True)
print(factory.version) # SampleSheetVersion.V1 or .V2
print(sheet.index_type()) # "dual", "single", or "none"
for sample in sheet.samples():
print(sample["sample_id"], sample["index"])
V1 parser directly
from samplesheet_parser import SampleSheetV1
sheet = SampleSheetV1("SampleSheet.csv")
sheet.parse()
print(sheet.experiment_name) # "MyRun_20240115"
print(sheet.read_lengths) # [151, 151]
print(sheet.adapters) # ["CTGTCTCTTATACACATCT"]
print(sheet.index_type()) # "dual"
for sample in sheet.samples():
print(sample["sample_id"], sample["index"], sample["index2"])
V2 parser + UMI extraction
from samplesheet_parser import SampleSheetV2
sheet = SampleSheetV2("SampleSheet.csv")
sheet.parse()
# OverrideCycles: Y151;I10U9;I10;Y151 → 9 bp UMI in Index1
print(sheet.get_umi_length()) # 9
rs = sheet.get_read_structure()
print(rs.umi_location) # "index2"
print(rs.read_structure) # {"read1_template": 151, "index2_length": 10, "index2_umi": 9, ...}
Format conversion
from samplesheet_parser import SampleSheetConverter
# V1 → V2
SampleSheetConverter("SampleSheet_v1.csv").to_v2("SampleSheet_v2.csv")
# V2 → V1 (lossy — V2-only fields are dropped with a warning)
SampleSheetConverter("SampleSheet_v2.csv").to_v1("SampleSheet_v1.csv")
Validation
from samplesheet_parser import SampleSheetFactory, SampleSheetValidator
sheet = SampleSheetFactory().create_parser("SampleSheet.csv", parse=True)
result = SampleSheetValidator().validate(sheet)
print(result.summary())
# PASS — 0 error(s), 2 warning(s)
for w in result.warnings:
print(w)
# [WARNING] INDEX_DISTANCE_TOO_LOW: Indexes for 'S1' and 'S2' in lane '1'
# have a Hamming distance of 1 (minimum recommended: 3).
# This may cause demultiplexing bleed-through.
for err in result.errors:
print(err)
# [ERROR] DUPLICATE_INDEX: Index 'ATTACTCG+TATAGCCT' appears more than once in lane 1
Diff two sheets
from samplesheet_parser import SampleSheetDiff
diff = SampleSheetDiff("old/SampleSheet.csv", "new/SampleSheet.csv")
result = diff.compare()
print(result.summary())
# Diff (V1 → V2):
# 2 header/settings change(s)
# 1 sample(s) added: SAMPLE_009
# 1 sample(s) with field changes
if result.has_changes:
for change in result.sample_changes:
print(change)
# Sample 'SAMPLE_002' (lane 1):
# Index: 'TCCGGAGA' → 'GGGGGGGG'
for s in result.samples_added:
print(f"Added: {s['Sample_ID']}")
Works across any combination of V1 and V2 — field names are normalised before
comparison so V1-only columns (I7_Index_ID, Sample_Name, etc.) do not
generate spurious diffs.
Build or edit a sheet
from samplesheet_parser import SampleSheetWriter
from samplesheet_parser.enums import SampleSheetVersion
# Build a V2 sheet from scratch
writer = SampleSheetWriter(version=SampleSheetVersion.V2)
writer.set_header(run_name="MyRun_20240115", platform="NovaSeqXSeries")
writer.set_reads(read1=151, read2=151, index1=10, index2=10)
writer.set_adapter("CTGTCTCTTATACACATCT")
writer.set_override_cycles("Y151;I10;I10;Y151")
writer.add_sample("SAMPLE_001", index="ATTACTCGAT", index2="TATAGCCTGT", project="Proj")
writer.add_sample("SAMPLE_002", index="TCCGGAGACC", index2="ATAGAGGCAC", project="Proj")
writer.write("SampleSheet.csv") # validates before writing by default
# Load an existing sheet, edit it, write back
from samplesheet_parser import SampleSheetFactory
sheet = SampleSheetFactory().create_parser("SampleSheet.csv", parse=True)
editor = SampleSheetWriter.from_sheet(sheet)
editor.remove_sample("SAMPLE_005")
editor.update_sample("SAMPLE_002", index="GGGGGGGGGG")
editor.write("SampleSheet_updated.csv")
write() runs SampleSheetValidator before writing by default — pass
validate=False to skip. from_sheet(sheet, version=SampleSheetVersion.V1)
converts format while editing.
Format detection logic
The factory uses a three-step detection strategy — no format hints required from the caller:
- Header discriminator — scan
[Header]forFileFormatVersion(→ V2) orIEMFileVersion(→ V1) - Section name scan — if no header key found, look for
[BCLConvert_Settings]/[BCLConvert_Data]in the full file (→ V2) - Default — fall back to V1 (broadest compatibility with legacy files)
The detector reads only as much of the file as needed — stopping after [Header] in the common case.
Validation checks
| Code | Level | Description |
|---|---|---|
EMPTY_SAMPLES |
error | No samples in Data section |
INVALID_INDEX_CHARS |
error | Index contains non-ACGTN characters |
INDEX_TOO_LONG |
error | Index longer than 24 bp |
DUPLICATE_INDEX |
error | Two samples share an index in the same lane |
DUPLICATE_SAMPLE_ID |
error | Same Sample_ID appears twice in one lane |
INDEX_TOO_SHORT |
warning | Index shorter than 6 bp |
INDEX_DISTANCE_TOO_LOW |
warning | Two indexes in the same lane have Hamming distance < 3, risking demultiplexing bleed-through |
NO_ADAPTERS |
warning | No adapter sequences configured |
ADAPTER_MISMATCH |
warning | Adapter is non-standard |
Hamming distance checking
Indexes that are too similar cause read bleed-through between samples during demultiplexing — a common cause of low-quality runs that is not caught by a simple duplicate check. The validator computes the Hamming distance between every pair of indexes within each lane and warns when the distance falls below the recommended minimum of 3.
For dual-index sheets, the I7 and I5 sequences are combined before comparison, so a pair that is close on I7 but well-separated on I5 (as most dual-index kits are designed) is not incorrectly flagged.
# Custom threshold — stricter than the default of 3
from samplesheet_parser.validators import SampleSheetValidator, ValidationResult
samples = sheet.samples()
result = ValidationResult()
SampleSheetValidator()._check_index_distances(samples, result, min_distance=4)
Diff
SampleSheetDiff compares two sheets — any combination of V1 and V2 — and
returns a structured DiffResult across four dimensions:
| Dimension | What is compared |
|---|---|
| Header | Key/value changes in [Header] / [BCLConvert_Settings] |
| Reads | Read length or cycle count changes |
| Samples added / removed | Keyed on Sample_ID + Lane |
| Sample field changes | Per-sample field-level diffs (index, project, etc.) |
result = SampleSheetDiff("before.csv", "after.csv").compare()
result.has_changes # bool
result.summary() # one-paragraph human-readable summary
result.header_changes # list[HeaderChange]
result.samples_added # list[dict]
result.samples_removed # list[dict]
result.sample_changes # list[SampleChange]
# Inspect per-sample changes
for sc in result.sample_changes:
print(sc.sample_id, sc.lane)
for field, (old, new) in sc.changes.items():
print(f" {field}: {old!r} → {new!r}")
V1-only metadata columns (I7_Index_ID, I5_Index_ID, Sample_Name,
Description) are suppressed when comparing V1 against V2 so that format
differences do not generate noise.
UMI / OverrideCycles parsing
The V2 OverrideCycles field encodes read structure including UMI positions:
| OverrideCycles | UMI length | UMI location |
|---|---|---|
Y151;I10;I10;Y151 |
0 | — |
Y151;I10U9;I10;Y151 |
9 | index2 |
U5Y146;I8;I8;U5Y146 |
5 | read1 |
sheet.get_umi_length() # → int
sheet.get_read_structure() # → ReadStructure dataclass
API reference
SampleSheetFactory
| Method / attribute | Returns | Description |
|---|---|---|
create_parser(path, *, clean, experiment_id, parse) |
SampleSheetV1 | SampleSheetV2 |
Auto-detect format and return appropriate parser |
get_umi_length() |
int |
UMI length from the current parser |
.version |
SampleSheetVersion |
Detected format version |
SampleSheetV1 / SampleSheetV2 (shared interface)
| Method / attribute | Returns | Description |
|---|---|---|
parse(do_clean=True) |
None |
Parse all sections |
samples() |
list[dict] |
One record per unique sample |
index_type() |
str |
"dual", "single", or "none" |
.adapters |
list[str] |
Adapter sequences |
.experiment_name |
str | None |
Run/experiment name |
V2-only
| Method | Returns |
|---|---|
get_umi_length() |
int |
get_read_structure() |
ReadStructure |
SampleSheetConverter
| Method | Returns | Notes |
|---|---|---|
to_v2(output_path) |
Path |
Converts IEM V1 → BCLConvert V2 |
to_v1(output_path) |
Path |
Converts BCLConvert V2 → IEM V1 (lossy) |
.source_version |
SampleSheetVersion |
Auto-detected format of input |
SampleSheetValidator
| Method | Returns | Description |
|---|---|---|
validate(sheet) |
ValidationResult |
Run all checks; returns structured result |
_check_index_distances(samples, result, min_distance=3) |
None |
Hamming distance check (callable directly for custom thresholds) |
SampleSheetWriter
| Method / attribute | Returns | Description |
|---|---|---|
SampleSheetWriter(version=) |
— | Instantiate for SampleSheetVersion.V1 or .V2 |
from_sheet(sheet, version=) |
SampleSheetWriter |
Load a parsed sheet for editing; optionally change output format |
set_header(*, run_name, platform, ...) |
self |
Set header fields (fluent) |
set_reads(*, read1, read2, index1, index2) |
self |
Set read cycle counts (fluent) |
set_adapter(adapter_read1, adapter_read2) |
self |
Set adapter sequences (fluent) |
set_override_cycles(override) |
self |
Set OverrideCycles string — V2 only (fluent) |
set_software_version(version) |
self |
Set SoftwareVersion — V2 only (fluent) |
set_setting(key, value) |
self |
Set an arbitrary settings key/value (fluent) |
add_sample(sample_id, *, index, ...) |
self |
Append a sample row (fluent) |
remove_sample(sample_id, *, lane=) |
self |
Remove sample(s) by ID, optionally scoped to a lane (fluent) |
update_sample(sample_id, *, lane=, **fields) |
self |
Update fields on an existing sample in-place (fluent) |
write(path, *, validate=True) |
Path |
Serialise to disk; validates first by default |
to_string() |
str |
Serialise to string without writing to disk |
.sample_count |
int |
Number of samples currently in the writer |
.sample_ids |
list[str] |
Sample IDs currently in the writer |
SampleSheetDiff
| Method | Returns | Description |
|---|---|---|
compare() |
DiffResult |
Full comparison across header, reads, settings, and samples |
DiffResult
| Attribute / method | Type | Description |
|---|---|---|
has_changes |
bool |
True if any difference was detected |
summary() |
str |
Human-readable one-paragraph summary |
header_changes |
list[HeaderChange] |
Header, reads, and settings diffs |
samples_added |
list[dict] |
Records present in new sheet only |
samples_removed |
list[dict] |
Records present in old sheet only |
sample_changes |
list[SampleChange] |
Per-sample field-level diffs |
source_version |
SampleSheetVersion |
Format of the old sheet |
target_version |
SampleSheetVersion |
Format of the new sheet |
Contributing
git clone https://github.com/chaitanyakasaraneni/samplesheet-parser
cd samplesheet-parser
pip install -e ".[dev]"
# Run tests
pytest tests/ -v
# Run demo scripts
python scripts/demo_converter.py
python scripts/demo_diff.py
python scripts/demo_writer.py
See CONTRIBUTING.md for the full local testing guide and PR checklist.
Citation
@software{kasaraneni2026samplesheetparser,
author = {Kasaraneni, Chaitanya},
title = {samplesheet-parser: Format-agnostic parser for Illumina SampleSheet.csv},
year = {2026},
url = {https://github.com/chaitanyakasaraneni/samplesheet-parser},
version = {0.2.0}
}
License
Apache 2.0 — see LICENSE.
Related resources
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file samplesheet_parser-0.2.0.tar.gz.
File metadata
- Download URL: samplesheet_parser-0.2.0.tar.gz
- Upload date:
- Size: 346.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f0f98d7debf1edd6500f8d2e0486c330ca5449e136cbe65892030449978eecbc
|
|
| MD5 |
3de67a20fb0d1a331fef601d24f08047
|
|
| BLAKE2b-256 |
f85cc8a7303ee75ec52426c24bb6619d6619db185e77b6cfe761c0542f7dba71
|
File details
Details for the file samplesheet_parser-0.2.0-py3-none-any.whl.
File metadata
- Download URL: samplesheet_parser-0.2.0-py3-none-any.whl
- Upload date:
- Size: 43.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d59589b11b0edc366485e5b90d2df3f74bfb674f42b5b77e9288bb1cd7703a16
|
|
| MD5 |
1b6b245d79496bb71264755fd7733240
|
|
| BLAKE2b-256 |
153ba8122d21bf036260972300ab59df3252202d3321ffd84ad65df295e77aa5
|







