A unified library for creating, representing, and storing speculative decoding algorithms for LLM serving such as in vLLM.

Project description






Overview
Speculators is a library for training speculative decoding draft models that deploy directly to LLM inference engines like vLLM. Speculative decoding is a lossless technique that speeds up LLM inference by using a smaller, faster draft model (i.e. "the speculator") to propose tokens, which are then verified by the larger base model, reducing latency without compromising output quality. The speculator intelligently drafts multiple tokens ahead of time, and the base model verifies them in a single forward pass. This approach boosts performance without sacrificing output quality, as every accepted token is guaranteed to match what the main model would have generated on its own.
Speculators standardizes this process by providing a productionized end-to-end framework to train draft models with reusable formats and tools. Trained models can seamlessly run in vLLM, enabling the deployment of speculative decoding in production-grade inference servers.

💬 Join us on the vLLM Community Slack and share your questions, thoughts, or ideas in:
#speculators#feat-spec-decode
🎥 Watch our Office Hours presentation: Video | Slides
🚀 What's New!
Big updates have landed in Speculators! To get a more in-depth look, check out the Speculators documentation.
Some of the exciting new features include:
- Qwen3-8B DFlash Speculator: The RedHat team published a DFlash speculator for Qwen3-8B, achieving average speculative token acceptance lengths of up to 3.74 on
math_reasoning. - Gemma 4 Speculators: The RedHat team published speculators for Gemma 4 31B-it, including both DFlash and EAGLE-3 checkpoints, enabling production-grade speculative decoding for Gemma 4 models.
- DFlash Training Algorithm: Added support for the DFlash training algorithm with anchored-block drafting, using auxiliary hidden states from multiple verifier layers. Includes CLI options for block size and max anchors, plus DFlash metrics, utilities, and draft model. DFlash models trained through Speculators can now run seamlessly in vLLM as of vLLM PR #38300.
- Online Training Support: Added support for online training using the new vLLM hidden extraction system, enabling real-time hidden state generation during training without requiring separate offline data generation steps.
Key Features
- Offline Training Data Generation using vLLM: Enable the generation of hidden states using vLLM. Data samples are saved to disk and can be used for draft model training.
- Draft Model Training Support: E2E training support of single and multi-layer draft models. Training is supported for MoE, non-MoE, and Vision Language models.
- Standardized, Extensible Format: Provides a Hugging Face-compatible format for defining speculative models, with tools to convert from external research repositories into a standard speculators format for easy adoption.
- Seamless vLLM Integration: Built for direct deployment into vLLM, enabling low-latency, production-grade inference with minimal overhead.
[!TIP] Read more about Speculators features in this vLLM blog post.
Supported Models
The following table summarizes the models that have been trained end-to-end by our team as well as others in the roadmap:
| Verifier Architecture | Verifier Size | Training Support | vLLM Deployment Support |
|---|---|---|---|
| Llama | 8B-Instruct | EAGLE-3 ✅ | ✅ |
| 70B-Instruct | EAGLE-3 ✅ | ✅ | |
| Qwen3 | 8B | EAGLE-3 ✅ DFlash ✅ |
✅ |
| 14B | EAGLE-3 ✅ | ✅ | |
| 32B | EAGLE-3 ✅ | ✅ | |
| gpt-oss | 20b | EAGLE-3 ✅ | ✅ |
| 120b | EAGLE-3 ✅ | ✅ | |
| Qwen3 MoE | 30B-Instruct | EAGLE-3 ✅ | ✅ |
| 235B-Instruct | EAGLE-3 ✅ | ✅ | |
| 235B | EAGLE-3 ✅ | ✅ | |
| Qwen3-VL | 235B-A22B | EAGLE-3 ✅ | ✅ |
| Mistral 3 Large | 675B-Instruct | EAGLE-3 ⏳ | ⏳ |
| Gemma 4 | 31B-it | EAGLE-3 ✅ DFlash ✅ |
✅ |
| Gemma 4 MoE | 26B-A4B-it | EAGLE-3 ✅ | ✅ |
✅ = Supported, ⏳ = In Progress, ❌ = Not Yet Supported
vLLM Inference
Models trained through Speculators can run seamlessly in vLLM using a simple vllm serve <speculator_model> command. This will run the model in vLLM using default arguments, defined in the speculator_config of the model's config.json.
vllm serve RedHatAI/Qwen3-8B-speculator.eagle3
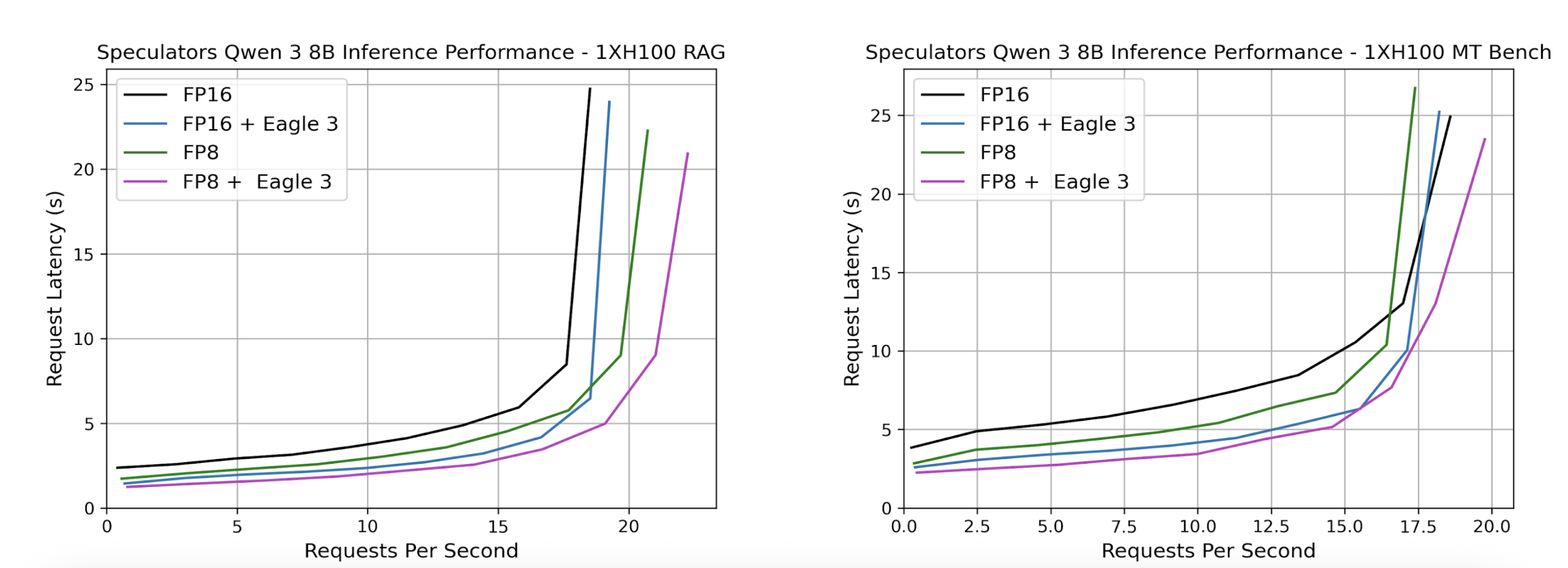
Served models can then be benchmarked using GuideLLM. Below, we show sample benchmark results where we compare our speculator with its dense counterpart. We also additionally compare quantization to explore additional performance improvements by swapping the dense verifier, Qwen/Qwen3-8B with the quantized FP8 model, RedHatAI/Qwen3-8B-FP8-dynamic in the speculator_config.
Additional Utility Scripts
Getting Started
Installation
Prerequisites
Before installing, ensure you have the following:
- Operating System: Linux or macOS
- Python: 3.10 or higher
- Package Manager: pip (recommended) or conda
Install from PyPI (Recommended)
Install the latest stable release from PyPI:
pip install speculators
Install from Source
For the latest development version or to contribute to the project:
git clone https://github.com/vllm-project/speculators.git
cd speculators
pip install -e .
For development with additional tools:
pip install -e ".[dev]"
Verify Installation
You can verify your installation by checking the version:
speculators --version
Or by importing the package in Python:
import speculators
print(speculators.__version__)
License
Speculators is licensed under the Apache License 2.0.
Cite
If you find Speculators helpful in your research or projects, please consider citing it:
@misc{speculators2025,
title={Speculators: A Unified Library for Speculative Decoding Algorithms in LLM Serving},
author={Red Hat},
year={2025},
howpublished={\url{https://github.com/vllm-project/speculators}},
}
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file speculators-0.6.0.tar.gz.
File metadata
- Download URL: speculators-0.6.0.tar.gz
- Upload date:
- Size: 125.5 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
6f8babb769bc1719883f2020f745fdc44c481d33d94114695f219011dc3fee03
|
|
| MD5 |
a647839acbc563ad7fc9e23013f954f7
|
|
| BLAKE2b-256 |
f32fa21297bc36aeee0d8942a4fa52a330a9acd29c93d26345c5d5bfe7e8a3cd
|
Provenance
The following attestation bundles were made for speculators-0.6.0.tar.gz:
Publisher:
speculators-upload.yml on neuralmagic/llm-compressor-testing
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
speculators-0.6.0.tar.gz -
Subject digest:
6f8babb769bc1719883f2020f745fdc44c481d33d94114695f219011dc3fee03 - Sigstore transparency entry: 1839823022
- Sigstore integration time:
-
Permalink:
neuralmagic/llm-compressor-testing@833cc3d17d2b388514d9652bdefed5f6217e8f6a -
Branch / Tag:
refs/heads/main - Owner: https://github.com/neuralmagic
-
Access:
private
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
speculators-upload.yml@833cc3d17d2b388514d9652bdefed5f6217e8f6a -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file speculators-0.6.0-py3-none-any.whl.
File metadata
- Download URL: speculators-0.6.0-py3-none-any.whl
- Upload date:
- Size: 145.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e2541c33d10d48b4f9641fc00650e52d99c2a66276a89a3a853a79b25ce868f1
|
|
| MD5 |
29e7713df2e14b6201270d5c1aedd564
|
|
| BLAKE2b-256 |
f2719bf353a849d90705e4a4dd50b638664d83de385c27978672fd8f00857720
|
Provenance
The following attestation bundles were made for speculators-0.6.0-py3-none-any.whl:
Publisher:
speculators-upload.yml on neuralmagic/llm-compressor-testing
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
speculators-0.6.0-py3-none-any.whl -
Subject digest:
e2541c33d10d48b4f9641fc00650e52d99c2a66276a89a3a853a79b25ce868f1 - Sigstore transparency entry: 1839823089
- Sigstore integration time:
-
Permalink:
neuralmagic/llm-compressor-testing@833cc3d17d2b388514d9652bdefed5f6217e8f6a -
Branch / Tag:
refs/heads/main - Owner: https://github.com/neuralmagic
-
Access:
private
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
speculators-upload.yml@833cc3d17d2b388514d9652bdefed5f6217e8f6a -
Trigger Event:
workflow_dispatch
-
Statement type:







