Stabilizing timestamps of OpenAI's Whisper outputs down to word-level.

Project description
Stabilizing Timestamps for Whisper
Description
This script modifies and adds more robust decoding logic on top of OpenAI's Whisper to produce more accurate segment-level timestamps and obtain to word-level timestamps with extra inference.
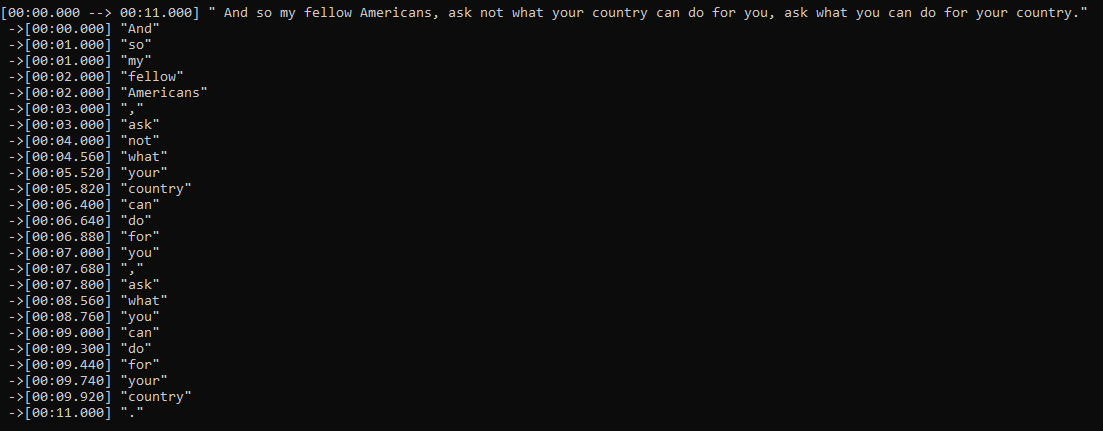
TODO
- Add function to stabilize with multiple inferences
- Add word timestamping (previously only token based)
Setup
Option 1: Install Whisper+stable-ts (one line)
pip install git+https://github.com/jianfch/stable-ts.git
Option 2: Install Whisper (repo) and stable-ts (PyPI) separately
- Install Whisper
- Check if Whisper is installed correctly by running a quick test
- Install stable-ts
import whisper
model = whisper.load_model('base')
assert model.transcribe('audio.mp3').get('segments')
pip install stable-ts
Command-line usage
Transcribe audio then save result as JSON file.
stable-ts audio.mp3 -o audio.json
Processing JSON file of the results into ASS.
stable-ts audio.json -o audio.ass
Transcribe multiple audio files then process the results directly into SRT files.
stable-ts audio1.mp3 audio2.mp3 audio3.mp3 -o audio1.srt audio2.srt audio3.srt
Show all available arguments and help.
stable-ts -h
Python usage
import stable_whisper
model = stable_whisper.load_model('base')
# modified model should run just like the regular model but accepts additional parameters
results = model.transcribe('audio.mp3')
# word-level
stable_whisper.results_to_word_srt(results, 'audio.srt')
# sentence/phrase-level
stable_whisper.results_to_sentence_srt(results, 'audio.srt')
# sentence/phrase-level & word-level
stable_whisper.results_to_sentence_word_ass(results, 'audio.ass')
Additional Info
- Although timestamps are chronological, they can still very inaccurate depending on the model, audio, and parameters.
- To produce production ready word-level results, the model needs to be fine-tuned with high quality dataset of audio with word-level timestamp.
License
This project is licensed under the MIT License - see the LICENSE file for details
Acknowledgments
Includes slight modification of the original work: Whisper
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
File details
Details for the file stable-ts-1.1.1b0.tar.gz.
File metadata
- Download URL: stable-ts-1.1.1b0.tar.gz
- Upload date:
- Size: 30.4 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.2 CPython/3.8.15
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d2c98f0ec6513a7f8be0b6b17dcc0ef4cc772f929d769ebea090cd52ff84d06c
|
|
| MD5 |
f4a5e101e6c99dd2b3b1d56b7a1f825e
|
|
| BLAKE2b-256 |
074c9f89c9a4661394dfe8de5cb1e6f87f3357fd3894d5fe2368a6c049a2897a
|







