TableSleuth - a Textual TUI for Open Table Format forensics (Iceberg, Delta Lake) with data profiling.
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
TableSleuth






A powerful terminal-based tool for deep inspection of Parquet files, Apache Iceberg tables, and Delta Lake tables. Analyze file structure, metadata, row groups, column statistics, and table evolution with an intuitive TUI interface.
Key Features
Parquet Analysis
- Deep File Inspection - Comprehensive metadata extraction using PyArrow
- Row Group Analysis - Examine distribution, compression, and statistics
- Column Profiling - Profile data using GizmoSQL (DuckDB over Arrow Flight SQL)
- Data Sampling - Preview and filter data with column selection
- Directory Scanning - Recursively discover and inspect Parquet files
Iceberg Table Analysis
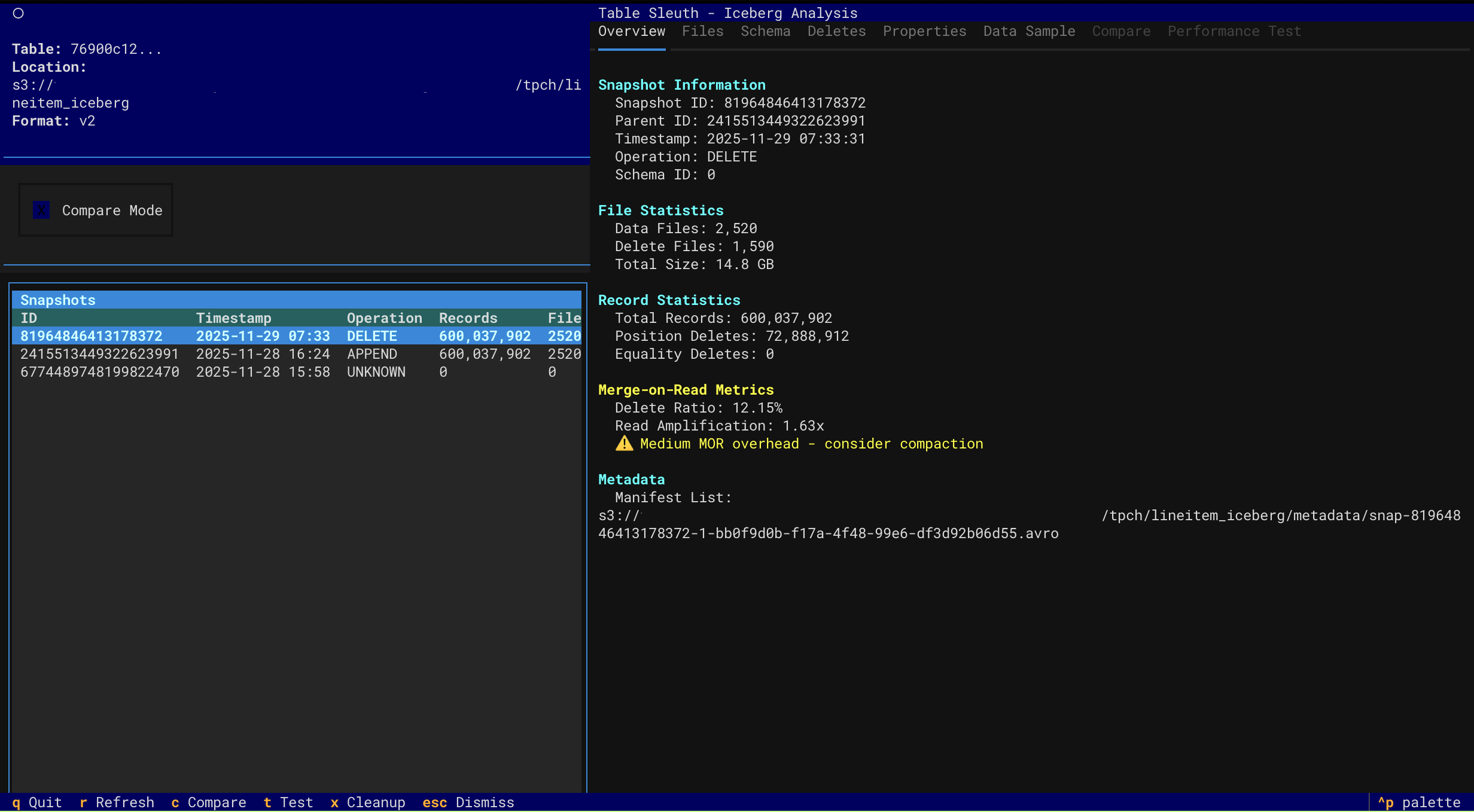
- Snapshot Navigation - Browse table history and metadata evolution
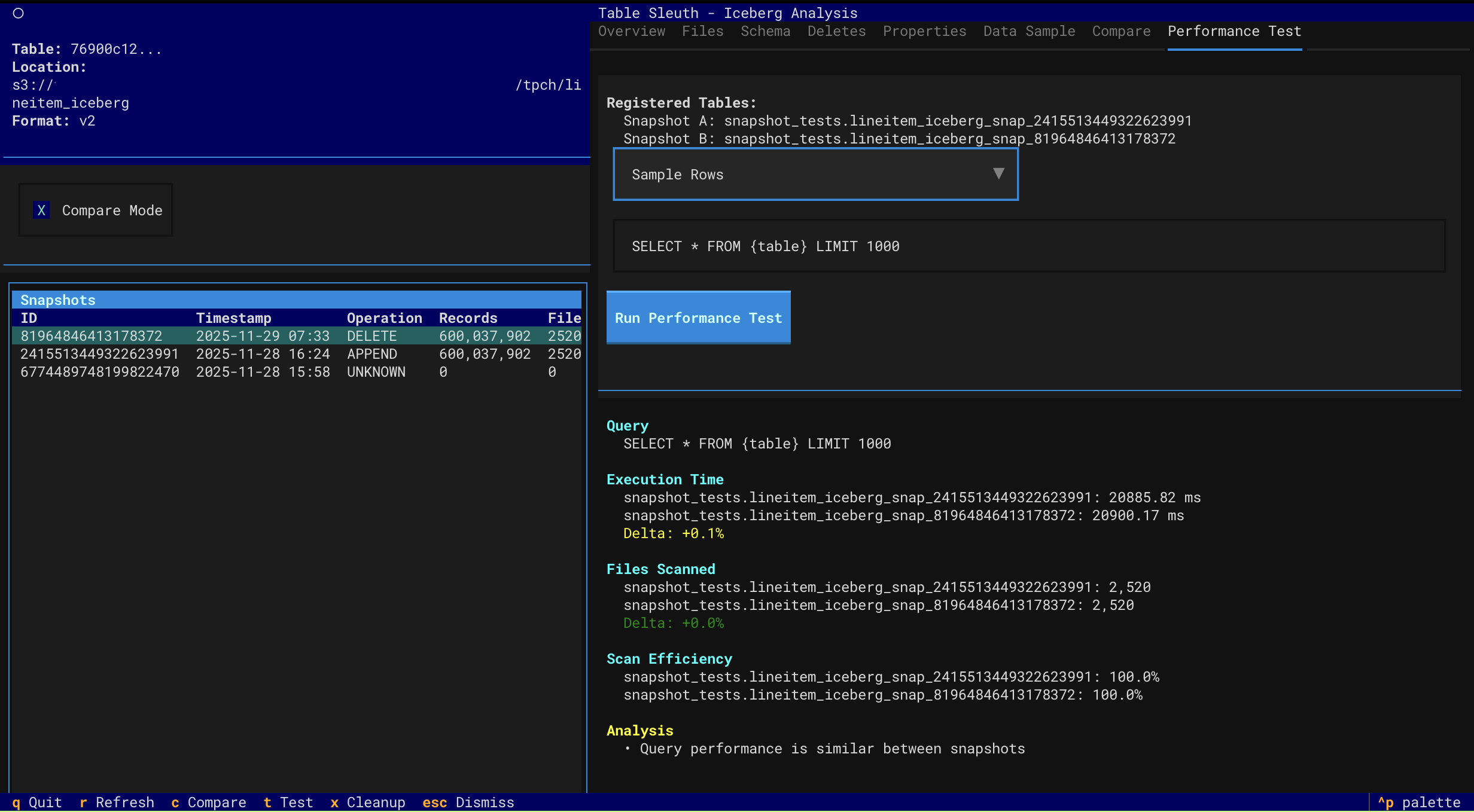
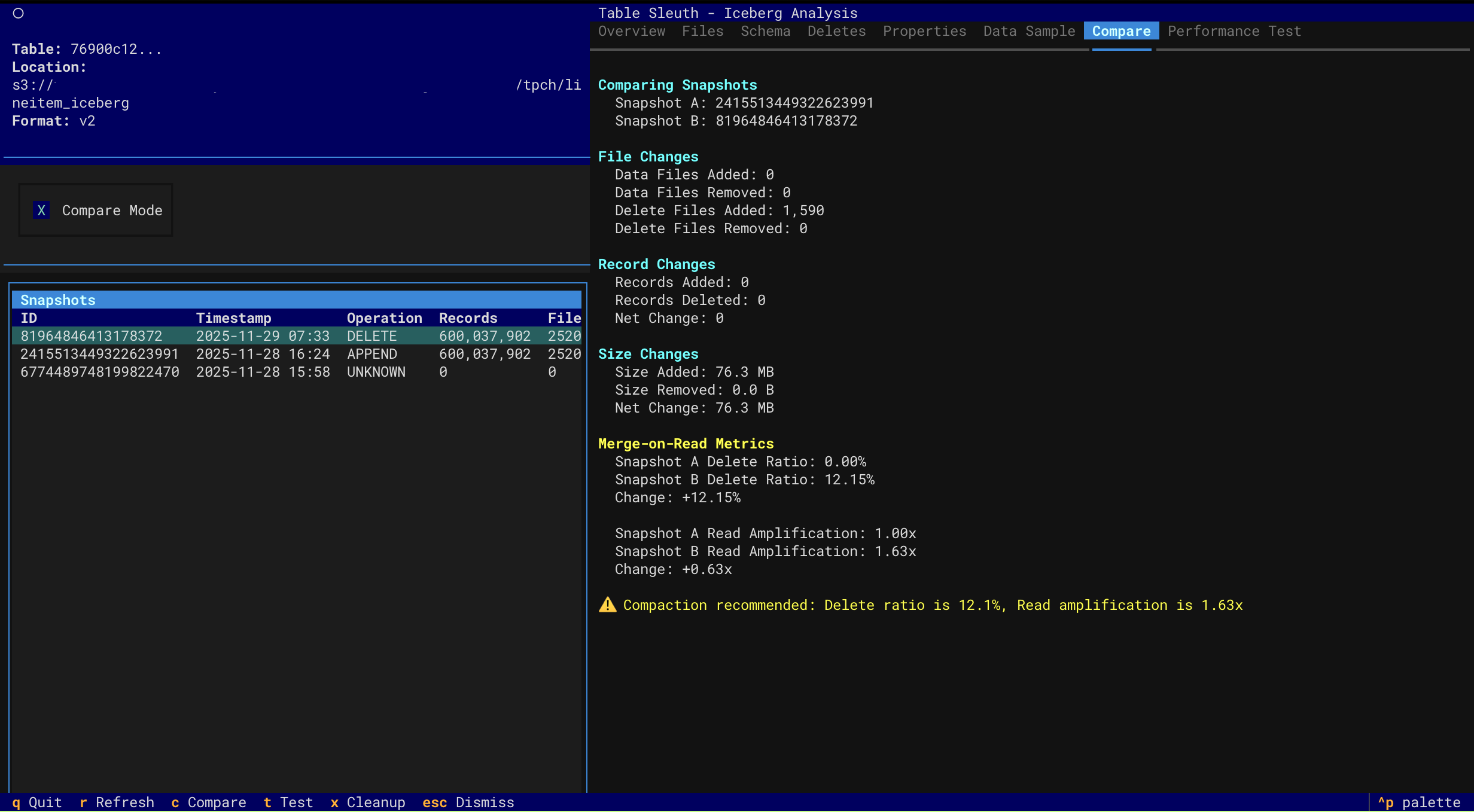
- Performance Testing - Compare query performance across snapshots with comprehensive analysis
- Multi-factor performance attribution (data volume, MOR overhead, scan efficiency)
- Accurate MOR overhead detection with read amplification metrics
- Order-agnostic comparison (works regardless of snapshot chronology)
- Actionable compaction recommendations with specific thresholds
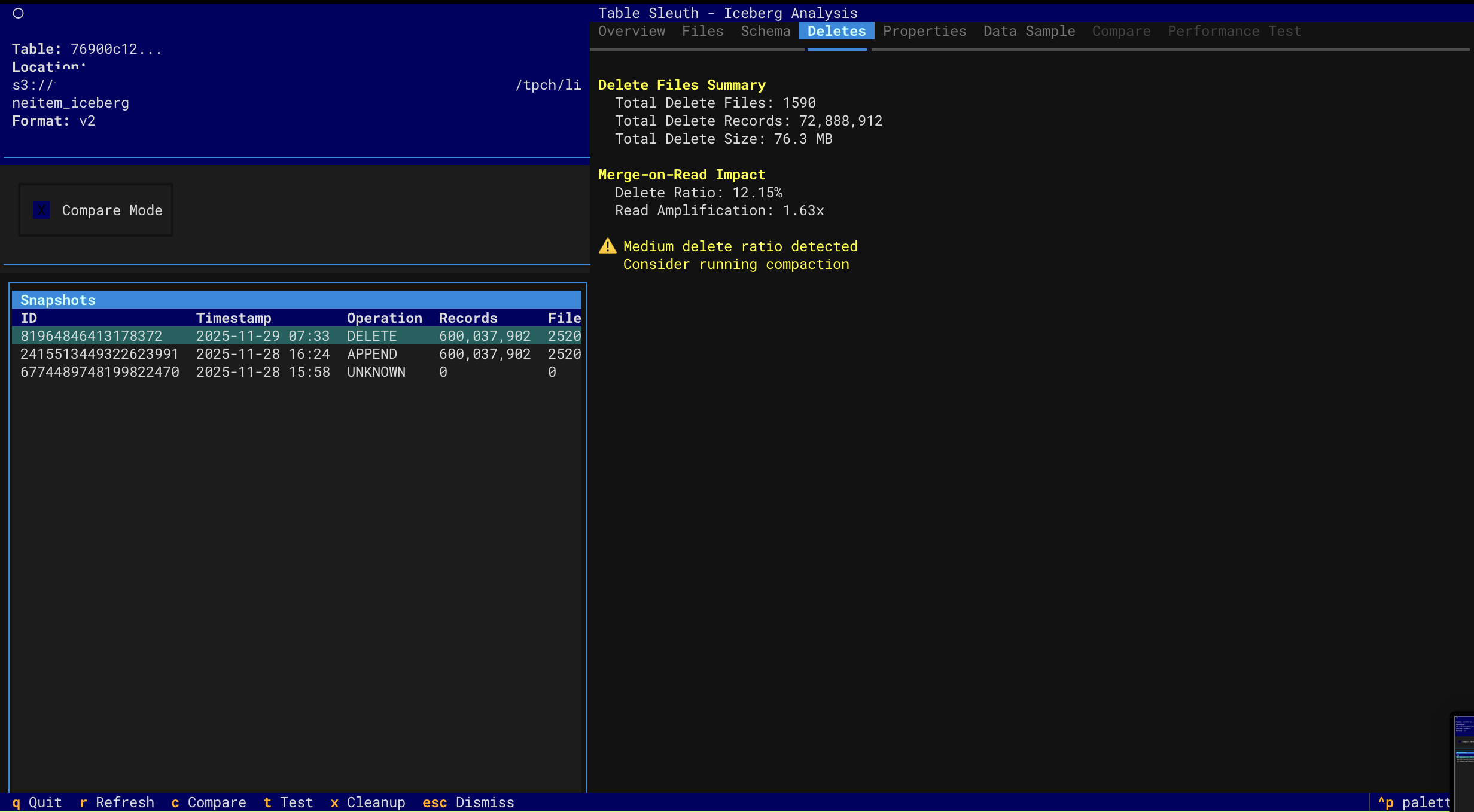
- Delete File Inspection - Analyze MOR (Merge-on-Read) delete files and read amplification
- Schema Evolution - Track schema changes over time
- Catalog Support - Local SQLite, AWS Glue, and AWS S3 Tables
Delta Lake Analysis
- Version History - Navigate through Delta table versions and time travel
- File Size Analysis - Identify small file problems and optimization opportunities
- Storage Waste - Track tombstoned files and reclaimable storage
- DML Forensics - Analyze MERGE, UPDATE, DELETE operations and rewrite amplification
- Z-Order Effectiveness - Monitor data skipping and clustering degradation
- Checkpoint Health - Assess transaction log health and maintenance needs
- Optimization Recommendations - Get prioritized suggestions for OPTIMIZE, VACUUM, and ZORDER
Interface
- Interactive TUI - Keyboard-driven navigation with rich visualizations
- Multi-Source Support - Local files, S3, Iceberg catalogs, and Delta tables
- Performance Optimized - Async operations, caching, and lazy loading
Screenshots
Parquet File Inspection
|
File Structure & Schema
|
Row Group Analysis
|
|
Data Sample View
|
Column Profiling
|
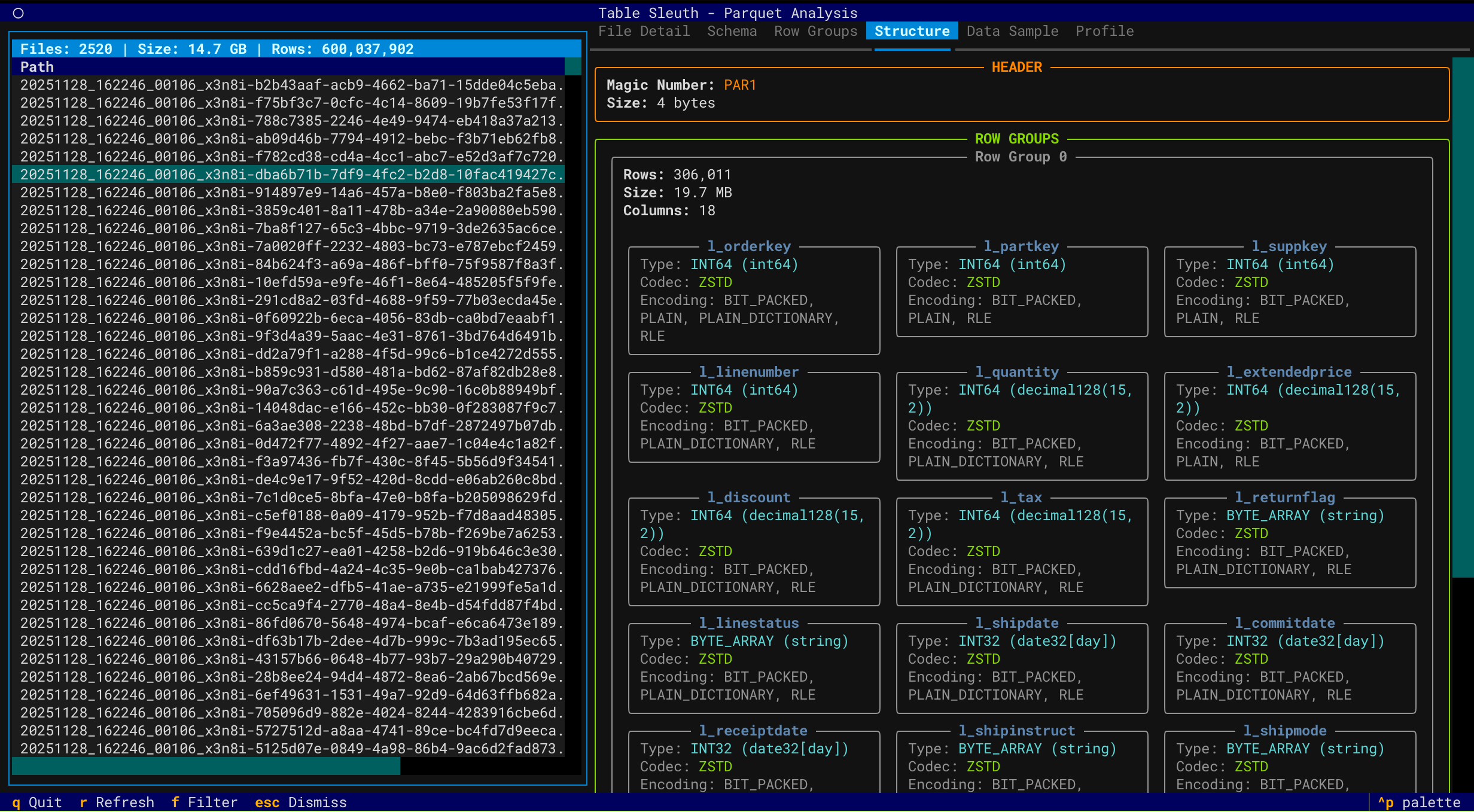
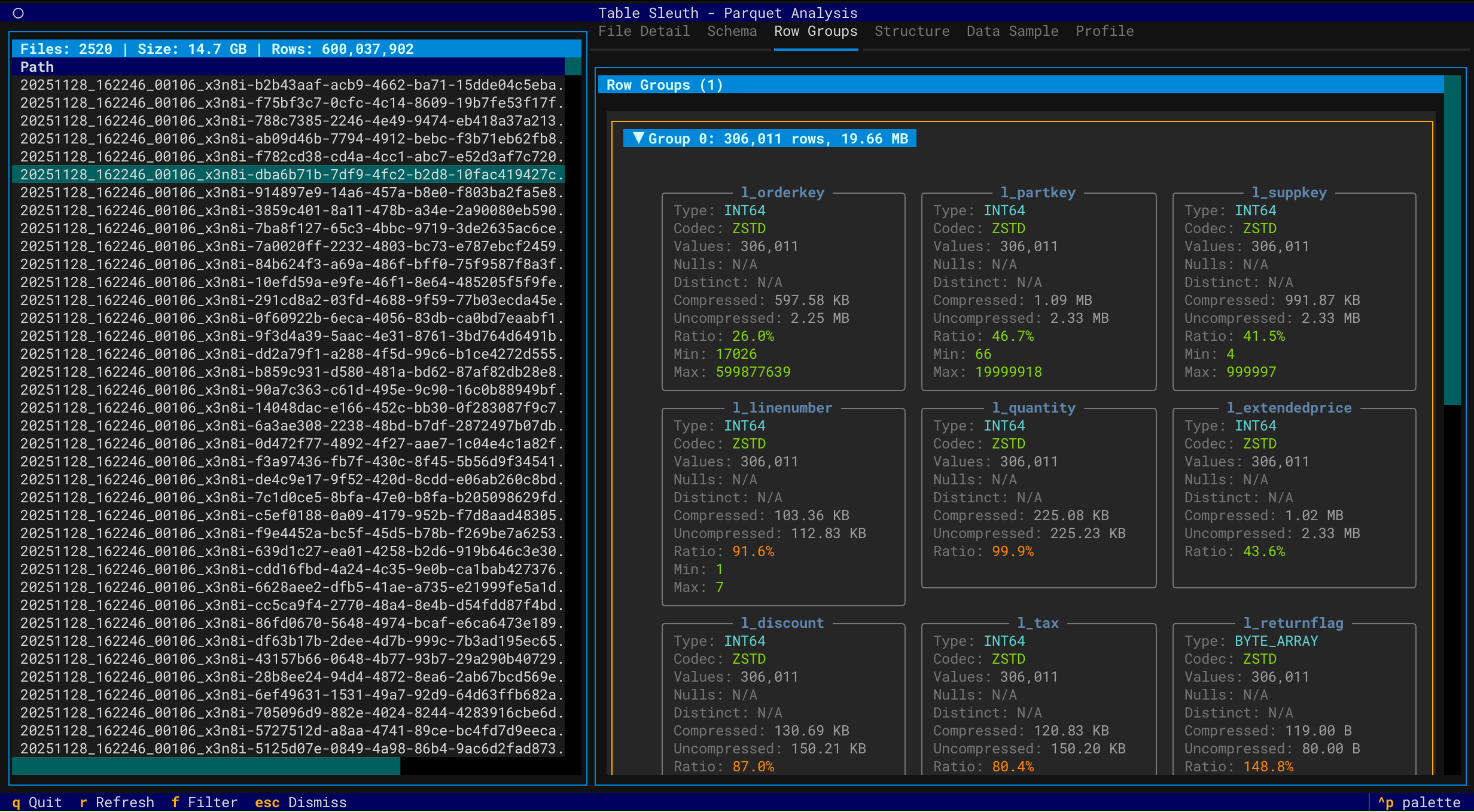
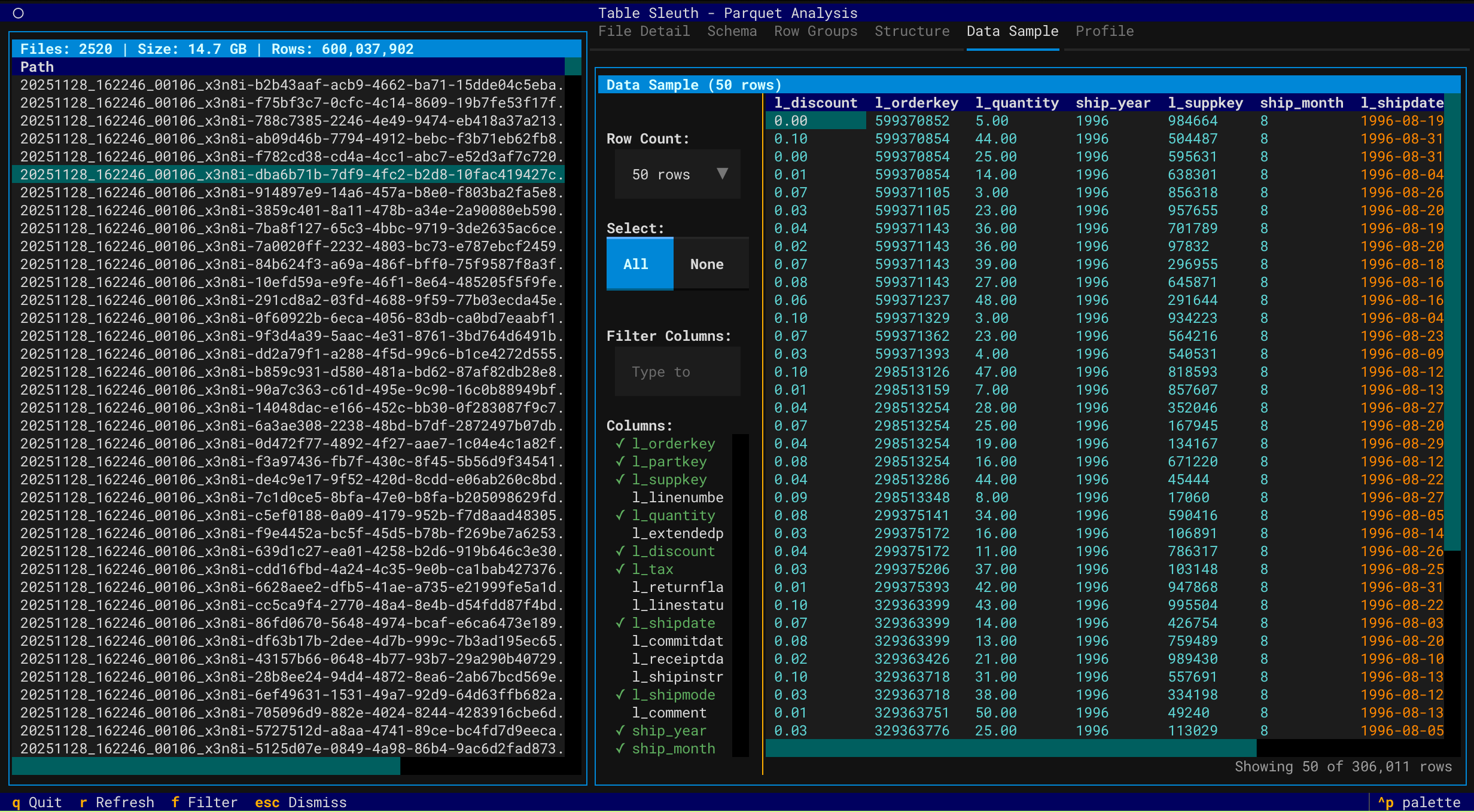
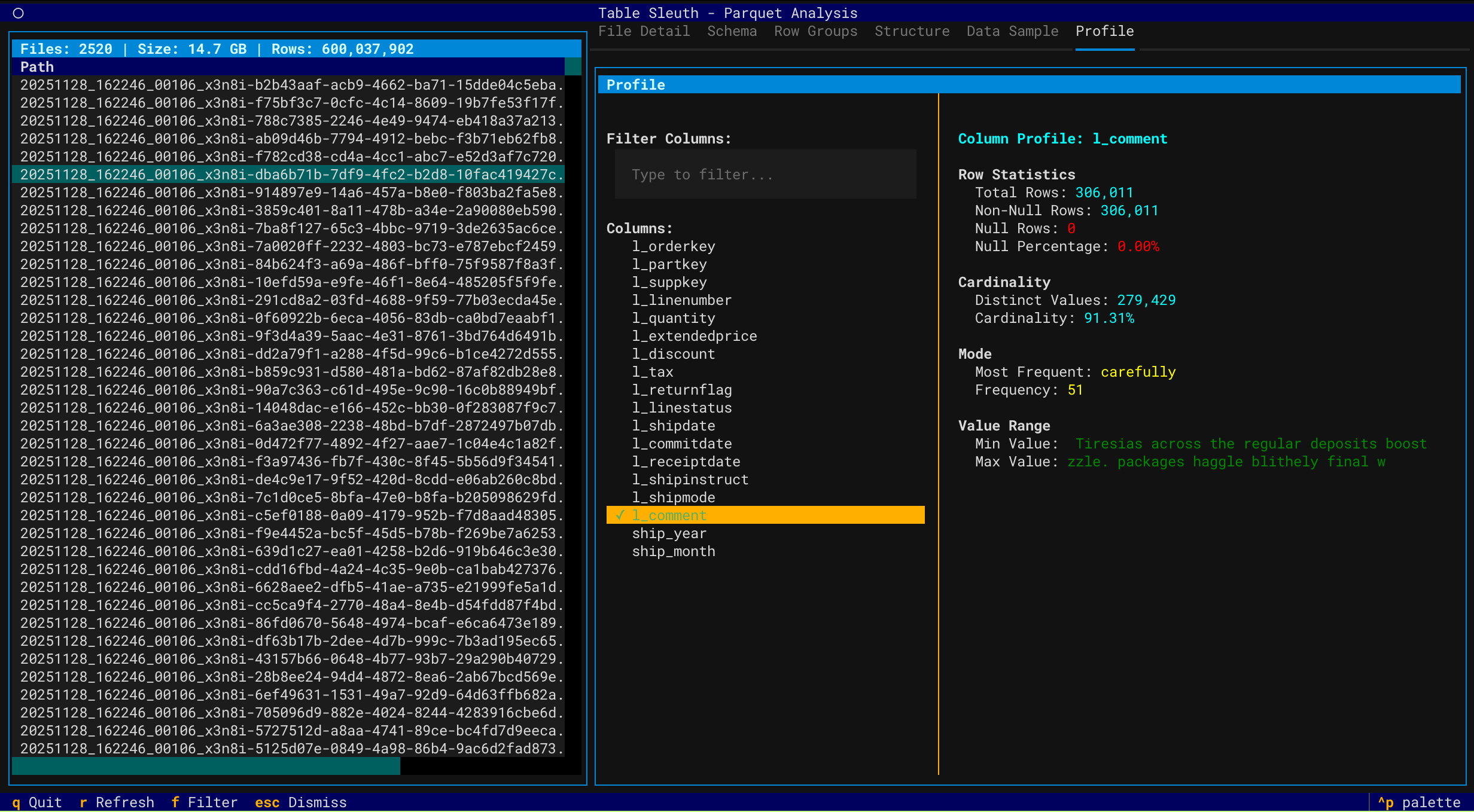
Iceberg Table Analysis
|
Snapshot Overview
|
Performance Testing
|
|
Delete Files (MOR)
|
Snapshot Comparison
|
Quick Start
# Install with uv (recommended)
uv sync
# Inspect a Parquet file
tablesleuth parquet data/file.parquet
# Inspect a directory (recursive)
tablesleuth parquet data/warehouse/
# Inspect an Iceberg table
tablesleuth iceberg --catalog local --table db.table
# Inspect AWS S3 Tables (using ARN with parquet command)
tablesleuth parquet "arn:aws:s3tables:us-east-2:123456789012:bucket/my-bucket/table/db.table"
📚 Documentation:
- Quick Start Guide - Get started with examples
- Setup Guide - Complete installation and configuration
- User Guide - Comprehensive usage documentation
Installation
Requirements: Python 3.13+ and uv
# Install from PyPI
pip install tablesleuth
# Or install from source
git clone https://github.com/jamesbconner/TableSleuth
cd TableSleuth
uv sync
# Verify installation
tablesleuth --version
# Initialize configuration files
tablesleuth init
See TABLESLEUTH_SETUP.md for detailed setup including AWS, GizmoSQL, and catalog configuration.
Quick Start
# 1. Initialize configuration (first time only)
tablesleuth init
# 2. Edit configuration files
# - tablesleuth.toml (main config)
# - .pyiceberg.yaml (catalog config)
# 3. Verify configuration
tablesleuth config-check
# 4. Start inspecting files
tablesleuth parquet data/file.parquet
Configuration
Quick Setup
# Initialize configuration files with interactive prompts
tablesleuth init
# Check configuration and test connections
tablesleuth config-check
tablesleuth config-check -v # Verbose output
Configuration Files
tablesleuth.toml - Main configuration:
[catalog]
default = "local" # Default Iceberg catalog
[gizmosql]
uri = "grpc+tls://localhost:31337"
username = "gizmosql_username"
password = "gizmosql_password"
tls_skip_verify = true
Configuration Priority:
- Environment variables (
TABLESLEUTH_*) - Local config files (
./tablesleuth.toml,./.pyiceberg.yaml) - Home config files (
~/tablesleuth.toml,~/.pyiceberg.yaml) - Built-in defaults
Iceberg Catalogs
Configure PyIceberg in .pyiceberg.yaml:
catalog:
local:
type: sql
uri: sqlite:////path/to/catalog.db
warehouse: file:///path/to/warehouse
For detailed configuration:
- Setup Guide - All catalog types and AWS configuration
- GizmoSQL Deployment - Profiling backend setup
Usage
CLI Commands
# Configuration management
tablesleuth init # Initialize config files
tablesleuth init --force # Overwrite existing config files
tablesleuth config-check # Validate configuration
tablesleuth config-check -v # Detailed validation
tablesleuth config-check --with-gizmosql # Include GizmoSQL connection test
# Inspect Parquet files
tablesleuth parquet file.parquet
tablesleuth parquet directory/
tablesleuth parquet s3://bucket/path/file.parquet
tablesleuth parquet file.parquet -v # Verbose mode
# Inspect Parquet files from Iceberg tables (discovers data files)
tablesleuth parquet --catalog local table.name
tablesleuth parquet --catalog glue --region us-east-2 db.table
# Inspect S3 Tables (use parquet command with ARN)
tablesleuth parquet "arn:aws:s3tables:region:account:bucket/name/table/db.table"
# Inspect Iceberg tables
tablesleuth iceberg --catalog local --table db.table
tablesleuth iceberg /path/to/metadata.json
tablesleuth iceberg s3://bucket/warehouse/table/metadata/metadata.json
tablesleuth iceberg --catalog local --table db.table -v # Verbose mode
# Inspect Delta Lake tables
tablesleuth delta path/to/delta/table
tablesleuth delta s3://bucket/path/to/delta/table
tablesleuth delta path/to/delta/table --version 5 # Time travel to version 5
tablesleuth delta s3://bucket/table/ --storage-option AWS_REGION=us-west-2
tablesleuth delta path/to/delta/table -v # Verbose mode
TUI Navigation
| Key | Action |
|---|---|
q |
Quit |
r |
Refresh |
f |
Filter columns |
Tab |
Switch tabs |
↑/↓ |
Navigate |
Enter |
Select |
See User Guide for complete keyboard shortcuts and features.
AWS Deployment
Deploy TableSleuth to AWS EC2 with production-ready infrastructure using AWS CDK (Cloud Development Kit):
cd resources/aws-cdk
# Set required environment variables
export SSH_ALLOWED_CIDR="$(curl -s ifconfig.me)/32" # Your IP for SSH access
export GIZMOSQL_USERNAME="admin"
export GIZMOSQL_PASSWORD="secure-password"
# Deploy to dev environment
cdk deploy -c environment=dev
Key Features:
- Infrastructure as Code - Version-controlled, reviewable infrastructure changes
- Security Best Practices - Least-privilege IAM, EBS encryption, VPC Flow Logs
- Multi-Environment - Separate dev/staging/prod configurations via CDK context
- Automated Setup - GizmoSQL service, PyIceberg Glue integration, and TableSleuth pre-installed
- Change Preview - Review infrastructure changes before deployment with
cdk diff
What's Included:
- EC2 instance with TableSleuth and GizmoSQL pre-configured
- IAM role with S3, Glue, and S3 Tables permissions
- Security group with SSH access from your IP
- Systemd service for GizmoSQL (auto-starts on boot)
- Complete PyIceberg configuration for AWS Glue catalog
Documentation:
- CDK README - Complete deployment guide
- CDK Quick Start - Deploy in 10 minutes
- Future Improvements - Planned enhancements
Optional: GizmoSQL Profiling
Enable column profiling and performance testing with GizmoSQL (DuckDB over Arrow Flight SQL).
Quick Setup:
# Install GizmoSQL (macOS ARM64 example)
curl -L https://github.com/gizmodata/gizmosql/releases/download/v1.12.10/gizmosql_cli_macos_arm64.zip \
| sudo unzip -o -d /usr/local/bin -
# Start server
gizmosql_server -U username -P password -Q \
-I "install aws; install httpfs; install iceberg; load aws; load httpfs; load iceberg; CREATE SECRET (TYPE s3, PROVIDER credential_chain);" \
-T ~/.certs/cert0.pem ~/.certs/cert0.key
Note: The -I initialization commands install DuckDB extensions for AWS/S3/Glue access. For alternative S3 authentication methods, see the DuckDB S3 API documentation.
See GizmoSQL Deployment Guide for complete setup and EC2 deployment.
Architecture
TableSleuth uses a layered architecture:
- TUI Layer - Textual-based terminal interface with rich visualizations
- Service Layer - Business logic for file inspection, profiling, and discovery
- Integration Layer - PyArrow for Parquet, PyIceberg for tables, GizmoSQL for profiling
See Architecture Guide for detailed technical documentation.
Development
# Install with dev dependencies
uv sync --all-extras
# Run tests
pytest
# Run quality checks
uv run pre-commit run --all-files
# Type checking
mypy src/
See Development Setup for complete development environment setup.
Documentation
Getting Started
- Quick Start - Examples and common workflows
- Setup Guide - Installation and configuration
- User Guide - Complete feature documentation
AWS Deployment
- CDK Deployment - Production-ready AWS infrastructure
- CDK Quick Start - Deploy in 10 minutes
Advanced Topics
- Performance Profiling - Query performance analysis
- GizmoSQL Deployment - Profiling backend setup
Development
- Development Setup - Dev environment and workflows
- Architecture - System design and technical details
- Developer Guide - API reference and contributing
What's New
v0.5.3 (Latest)
- 🏗️ CLI Architecture Refactored - Modular command structure with auto-loading
- Split monolithic CLI into focused command modules (80% code reduction per module)
- Dynamic command discovery - new commands auto-register by convention
- Significantly improved maintainability and extensibility
- 🔧 Service Layer Improvements - Enhanced abstractions and reduced coupling
- DeltaLogFileSystem - Unified filesystem interface eliminating ~250 lines of duplication
- SnapshotPerformanceAnalyzer - Explicit interface validation with fail-fast error handling
- Reduced complexity by 40-50% across refactored methods
- 📊 Code Quality: A (96/100) - Upgraded from A (94/100)
- Eliminated 11 developer-days of technical debt
- All 165+ tests passing
- Production-ready architecture
v0.5.2
- 🚀 AWS CDK Infrastructure - Production-ready CDK implementation for EC2 deployment
- Replaces legacy boto3 scripts with infrastructure-as-code approach
- Follows AWS CDK best practices (least-privilege IAM, EBS encryption, VPC Flow Logs)
- Multi-environment support (dev, staging, prod) with context-based configuration
- Type-safe configuration using dataclasses and environment variables
- Automated GizmoSQL service setup with systemd
- Complete PyIceberg Glue integration out-of-the-box
- See resources/aws-cdk/README.md for details
- 🔍 Enhanced Iceberg Performance Analysis - Better multi-factor performance comparison
- Order-agnostic analysis (works regardless of snapshot chronology)
- Multi-factor attribution: data volume, file counts, MOR overhead, delete ratios, scan efficiency
- Accurate MOR overhead detection (only when delete files actually exist)
- Read amplification metrics and compaction recommendations
- Detailed contributing factors with specific metrics and percentages
- 🔒 Enhanced Security - Improved IAM permissions and encryption
- 📚 Consolidated Documentation - Streamlined deployment guides and removed legacy content
v0.5.1
- 🚀 AWS CDK Infrastructure - Production-ready CDK implementation for EC2 deployment
- Replaces legacy boto3 scripts with infrastructure-as-code approach
- Follows AWS CDK best practices (least-privilege IAM, EBS encryption, VPC Flow Logs)
- Multi-environment support (dev, staging, prod) with context-based configuration
- Type-safe configuration using dataclasses and environment variables
- Automated GizmoSQL service setup with systemd
- Complete PyIceberg Glue integration out-of-the-box
- See resources/aws-cdk/README.md for details
- 🔍 Enhanced Iceberg Performance Analysis - Better multi-factor performance comparison
- Order-agnostic analysis (works regardless of snapshot chronology)
- Multi-factor attribution: data volume, file counts, MOR overhead, delete ratios, scan efficiency
- Accurate MOR overhead detection (only when delete files actually exist)
- Read amplification metrics and compaction recommendations
- Detailed contributing factors with specific metrics and percentages
- 🔒 Enhanced Security - Improved IAM permissions and encryption
- 📚 Consolidated Documentation - Streamlined deployment guides and removed legacy content
v0.5.0 (Current)
- 🎉 Delta Lake Support - Full Delta table inspection and forensics
- Version history navigation and time travel
- File size analysis and small file detection
- Storage waste tracking (tombstoned files)
- DML forensics (MERGE, UPDATE, DELETE operations)
- Z-Order effectiveness monitoring
- Checkpoint health assessment
- Optimization recommendations
v0.4.2
- 🎉 Available on PyPI! Install with
pip install tablesleuth - 🔄 Package renamed to
tablesleuthfor consistency - 🤖 Automated CI/CD with GitHub Actions
- 📦 Enhanced PyPI metadata and publishing workflow
- 🐛 Bug fixes and stability improvements
v0.4.0
- 🎉 PyPI release
- 🔄 Package renamed to
tablesleuth - 🤖 Automated CI/CD with GitHub Actions
- 📦 Enhanced PyPI metadata and publishing workflow
v0.3.0
- ✅ Parquet file inspection (local and S3)
- ✅ Iceberg snapshot navigation and analysis
- ✅ Delete file inspection and MOR forensics
- ✅ Snapshot comparison and performance testing
- ✅ Column profiling with GizmoSQL
- ✅ AWS Glue and S3 Tables catalog support
- ✅ Interactive TUI with rich visualizations
- ✅ Delta Lake version history and forensics
- ✅ Storage waste analysis and optimization recommendations
- ✅ DML operation forensics and rewrite amplification tracking
Roadmap
- Apache Hudi support
- Schema evolution visualization
- Export capabilities (JSON, CSV reports)
- REST catalog support
- Advanced partition analysis
Contributing
Contributions welcome! See Developer Guide and Development Setup.
License
MIT License - See LICENSE for details.
Support
- Issues & Features: GitHub Issues
- Documentation: See docs/ directory
- Changelog: CHANGELOG.md
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tablesleuth-0.5.3.tar.gz.
File metadata
- Download URL: tablesleuth-0.5.3.tar.gz
- Upload date:
- Size: 6.3 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c702ccbe8b85f8fce037c934fc228c9a926bfa7350024369af4941d103ecd3c5
|
|
| MD5 |
03ef9bccea77cf69feb5f8e0a18c158d
|
|
| BLAKE2b-256 |
1d647b0aba3278fef97cf31815406afc55af1fea74009e78fd686f322a064745
|
Provenance
The following attestation bundles were made for tablesleuth-0.5.3.tar.gz:
Publisher:
publish.yml on jamesbconner/TableSleuth
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
tablesleuth-0.5.3.tar.gz -
Subject digest:
c702ccbe8b85f8fce037c934fc228c9a926bfa7350024369af4941d103ecd3c5 - Sigstore transparency entry: 855143608
- Sigstore integration time:
-
Permalink:
jamesbconner/TableSleuth@0ba88c727a785c46c796197c860245fd31bbec11 -
Branch / Tag:
refs/tags/v0.5.3 - Owner: https://github.com/jamesbconner
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@0ba88c727a785c46c796197c860245fd31bbec11 -
Trigger Event:
release
-
Statement type:
File details
Details for the file tablesleuth-0.5.3-py3-none-any.whl.
File metadata
- Download URL: tablesleuth-0.5.3-py3-none-any.whl
- Upload date:
- Size: 145.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f2ba8825cad40ec684e6165beb97f5a81c4b4c984a20ccb6dddcc89bda574077
|
|
| MD5 |
554f28b1b93c1f9350d9406c029cdc60
|
|
| BLAKE2b-256 |
5da8b7d9c57a9a7a75fb16d4dfd9693e7214ee0058fe9b6342354c234e0164f0
|
Provenance
The following attestation bundles were made for tablesleuth-0.5.3-py3-none-any.whl:
Publisher:
publish.yml on jamesbconner/TableSleuth
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
tablesleuth-0.5.3-py3-none-any.whl -
Subject digest:
f2ba8825cad40ec684e6165beb97f5a81c4b4c984a20ccb6dddcc89bda574077 - Sigstore transparency entry: 855143609
- Sigstore integration time:
-
Permalink:
jamesbconner/TableSleuth@0ba88c727a785c46c796197c860245fd31bbec11 -
Branch / Tag:
refs/tags/v0.5.3 - Owner: https://github.com/jamesbconner
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@0ba88c727a785c46c796197c860245fd31bbec11 -
Trigger Event:
release
-
Statement type:







