A lightweight framework for running functions concurrently across multiple threads while maintaining a defined execution order.

Project description


threaded-order
threaded-order is a lightweight Python framework for running functions in parallel while honoring explicit dependency order.
You declare dependencies; the scheduler handles sequencing, concurrency, and correctness.
Great for dependency-aware test runs, build steps, pipelines, and automation flows that need structure without giving up speed.
Why threaded-order?
Use it when you want:
- Parallel execution with strict upstream → downstream ordering
- A simple, declarative way to express dependencies (
after=['a', 'b']) - Deterministic behavior even under concurrency
- A DAG-driven execution model without heavyweight tooling
- A clean decorator-based API for organizing tasks
- A CLI (
tdrun) for running functions as parallel tests
Key Features
- Parallel execution using Python threads backed by a dependency DAG
- Deterministic ordering based on
after=[...]relationships - Decorator-based API (
@dmark,@dregister) for clean task definitions - Shared state (opt-in) with a thread-safe, built-in lock
- Thread-safe logging via
ThreadProxyLogger - Graceful interrupt handling and clear run summaries
- CLI:
tdrun— dependency-aware test runner with tag filtering - DAG visualization — inspect your dependency graph with --graph
- Simple, extensible design — no external dependencies
About the DAG
threaded-order schedules work using a Directed Acyclic Graph (DAG) — this structure defines which tasks must run before others.
If you’re new to DAGs or want a quick refresher, this short primer is helpful: https://en.wikipedia.org/wiki/Directed_acyclic_graph
Installation
pip install threaded-order
API Overview
class Scheduler(
workers=None, # max number of worker threads
state=None, # shared state dict passed to @dmark functions
store_results=True, # save return values into state["results"]
clear_results_on_start=True, # wipe previous results
setup_logging=False, # enable built-in logging config
add_stream_handler=True, # attach stream handler to logger
verbose=False # enable extra debug logging
)
Runs registered callables across multiple threads while respecting declared dependencies.
Core Methods
| Method | Description |
|---|---|
register(obj, name, after=None, with_state=False) |
Register a callable for execution. after defines dependencies by name, specify if function is to receive the shared state. |
dregister(after=None, with_state=False) |
Decorator variant of register() for inline task definitions. |
start() |
Start execution, respecting dependencies. Returns a summary dictionary. |
dmark(after=None, with_state=False, tags=None) |
Decorator that marks a function for deferred registration by the scheduler, allowing you to declare dependencies (after) and whether the function should receive the shared state (with_state), and optionally add tags to the function (tags) for execution filtering. |
Callbacks
All are optional and run on the scheduler thread (never worker threads).
| Callback | When Fired | Signature |
|---|---|---|
on_task_start(fn) |
Before a task starts | (name) |
on_task_run(fn) |
When tasks starts running on a thread | (name, thread) |
on_task_done(fn) |
After a task finishes | (name, ok) |
on_scheduler_start(fn) |
Before scheduler starts running tasks | (meta) |
on_scheduler_done(fn) |
After all tasks complete | (summary) |
Shared state and _state_lock
If with_state=True, tasks receive the shared state dict.
Threaded-order inserts a re-entrant lock at state['_state_lock'] you can use when modifying shared values.
For more information refer to Shared State Guidelines
Interrupt Handling
Press Ctrl-C during execution to gracefully cancel outstanding work:
- Running tasks finish naturally or are marked as cancelled
- Remaining queued tasks are discarded
- Final summary reflects all results
CLI Overview (tdrun)
tdrun is a DAG-aware, parallel test runner built on top of the threaded-order scheduler.
It discovers @dmark functions inside a module, builds a dependency graph, and executes everything in parallel while preserving deterministic order.
You get:
- Parallel execution based on the Scheduler
- Predictable, DAG-driven ordering
- Tag filtering (
--tags=tag1,tag2) - Arbitrary state injection via
--key=value - Mock upstream results for single-function runs
- Graph inspection (
--graph) to validate ordering and parallelism - Clean pass/fail summary
CLI usage
usage: tdrun [-h] [--workers WORKERS] [--tags TAGS] [--log] [--verbose] [--graph] target
A threaded-order CLI for dependency-aware, parallel function execution.
positional arguments:
target Python file containing @dmark functions
options:
-h, --help show this help message and exit
--workers WORKERS Number of worker threads (default: Scheduler default)
--tags TAGS Comma-separated list of tags to filter functions by
--log enable logging output
--verbose enable verbose logging output
--graph show dependency graph and exit
Run all marked functions in a module:
tdrun path/to/module.py
Run a single function:
tdrun module.py::test_b
This isolates the function and ignores its upstream dependencies.
You can provide mocked results:
tdrun module.py::test_b --result-test_a=mock_value
Inject arbitrary state parameters
tdrun module.py --env=dev --region=us-west
These appear in initial_state and can be processed in your module’s setup_state(state).
This allows your module to compute initial state based on CLI parameters.
DAG Inspection
Use graph-only mode to inspect dependency structure:
tdrun examples/example4c.py --graph
Example output:
Graph: 6 nodes, 6 edges
Roots: [0]
Leaves: [4], [5]
Levels: 4
Nodes:
[0] test_a
[1] test_b
[2] test_c
[3] test_d
[4] test_e
[5] test_f
Edges:
[0] -> [1], [2]
[1] -> [5]
[2] -> [3], [4]
[3] -> [5]
[4] -> (none)
[5] -> (none)
Stats:
Longest chain length (edges): 3
Longest chains:
test_a -> test_c -> test_d -> test_f
High fan-in nodes (many dependencies):
test_f (indegree=2)
High fan-out nodes (many dependents):
test_a (children=2)
test_c (children=2)
Examples
See the examples/ folder for runnable demos.
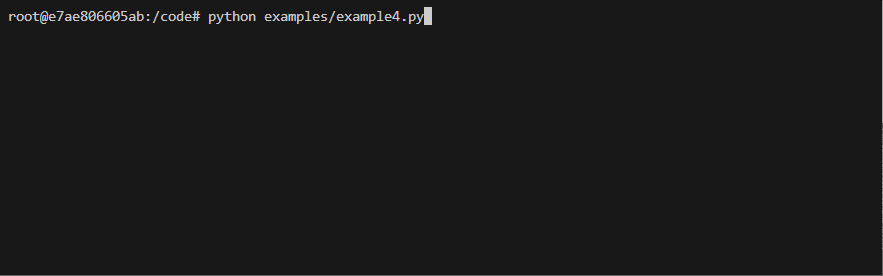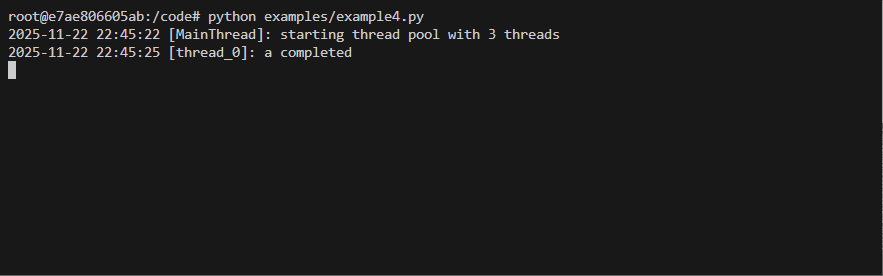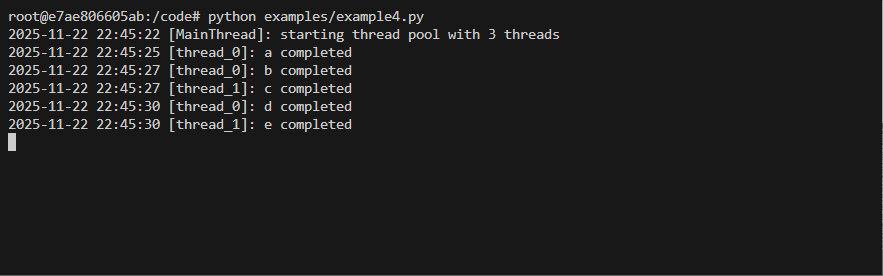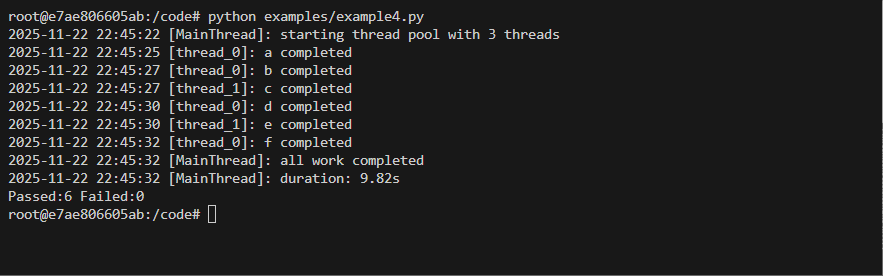
Basic usage Example
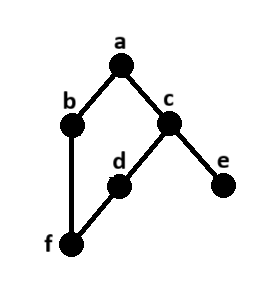
Code
from threaded_order import Scheduler, ThreadProxyLogger
import time
import random
s = Scheduler(workers=3, setup_logging=True)
logger = ThreadProxyLogger()
def run(name):
time.sleep(random.uniform(.5, 3.5))
logger.info(f'{name} completed')
@s.dregister()
def a(): run('a')
@s.dregister(after=['a'])
def b(): run('b')
@s.dregister(after=['a'])
def c(): run('c')
@s.dregister(after=['c'])
def d(): run('d')
@s.dregister(after=['c'])
def e(): run('e')
@s.dregister(after=['b', 'd'])
def f(): run('f')
if __name__ == '__main__':
s.on_scheduler_done(lambda s: print(f"Passed:{len(s['passed'])} Failed:{len(s['failed'])}"))
s.start()
Shared State Example
Code
import json
from time import sleep
from threaded_order import Scheduler
s = Scheduler(workers=3, state={})
@s.dregister(with_state=True)
def load(state):
with state['_state_lock']:
state['counter'] = state.get('counter', 0) + 1
state["x"] = 10; return "loaded"
@s.dregister(with_state=True)
def behave(state):
with state['_state_lock']:
state['counter'] = state.get('counter', 0) + 1
sleep(3); return "behaved"
@s.dregister(after=["load"], with_state=True)
def compute(state):
with state['_state_lock']:
state['counter'] = state.get('counter', 0) + 1
state["x"] += 5; return state["x"]
s.start()
print(json.dumps(s.state, indent=2, default=str))
{
"_state_lock": "<unlocked _thread.RLock object owner=0 count=0 at 0x7ac9632852c0>",
"results": {
"load": "loaded",
"compute": 15,
"behave": "behaved"
},
"counter": 3,
"x": 15
}
tdrun Example
Code
import time
import random
from faker import Faker
from threaded_order import dmark, ThreadProxyLogger
logger = ThreadProxyLogger()
def setup_state(state):
state.update({
'faker': Faker()
})
def run(name, state, deps=None, fail=False):
with state['_state_lock']:
last_name = state['faker'].last_name()
sleep = random.uniform(.5, 3.5)
logger.debug(f'{name} \"{last_name}\" running - sleeping {sleep:.2f}s')
time.sleep(sleep)
if fail:
assert False, 'Intentional Failure'
else:
results = []
for dep in (deps or []):
dep_result = state['results'].get(dep, '--no-result--')
results.append(f'{name}.{dep_result}')
if not results:
results.append(name)
logger.info(f'{name} passed')
return '|'.join(results)
@dmark(with_state=True)
def test_a(state): return run('test_a', state)
@dmark(with_state=True, after=['test_a'])
def test_b(state): return run('test_b', state, deps=['test_a'])
@dmark(with_state=True, after=['test_a'])
def test_c(state): return run('test_c', state, deps=['test_a'])
@dmark(with_state=True, after=['test_c'])
def test_d(state): return run('test_d', state, deps=['test_c'], fail=True)
@dmark(with_state=True, after=['test_c'])
def test_e(state): return run('test_e', state, deps=['test_c'])
@dmark(with_state=True, after=['test_b', 'test_d'])
def test_f(state): return run('test_f', state, deps=['test_b', 'test_d'])
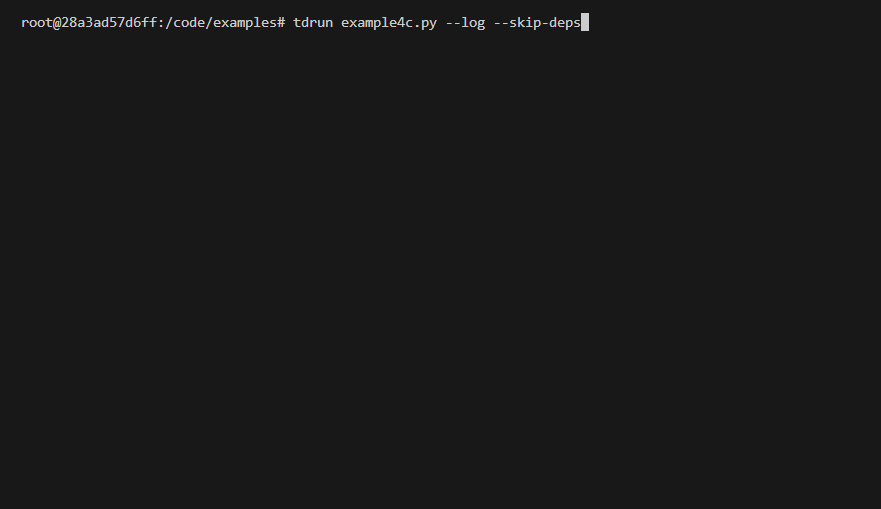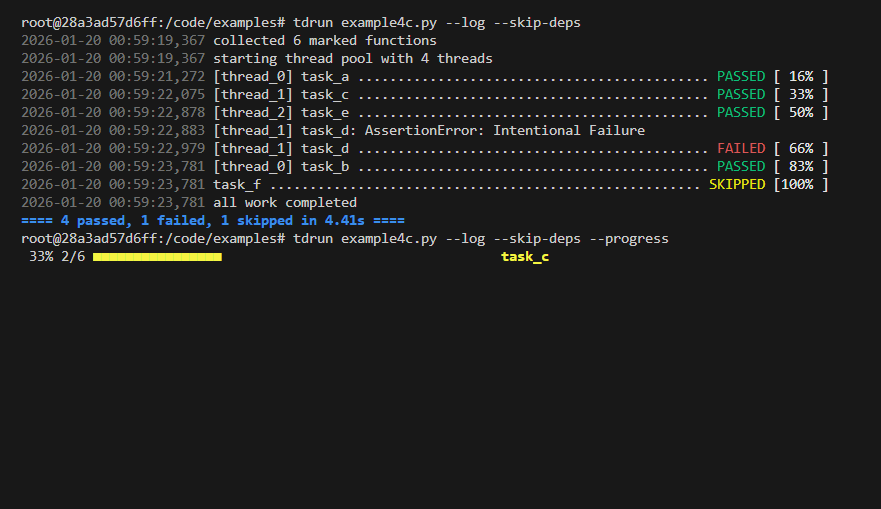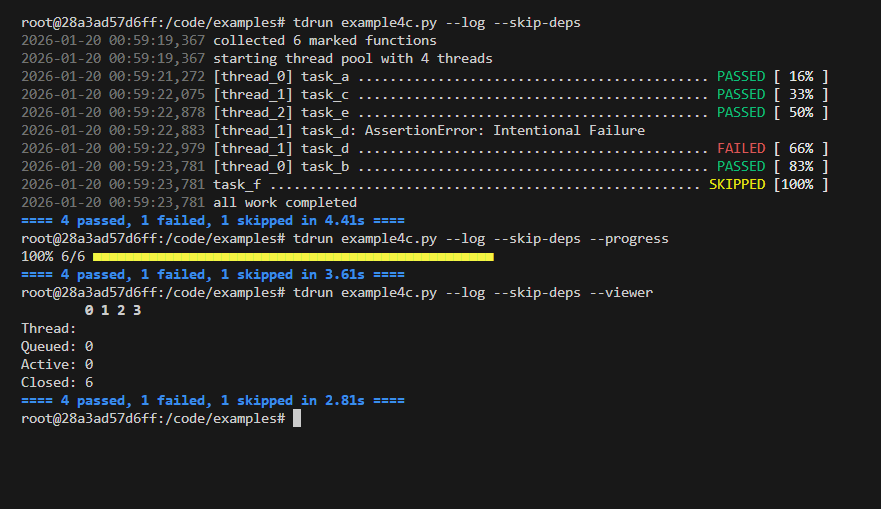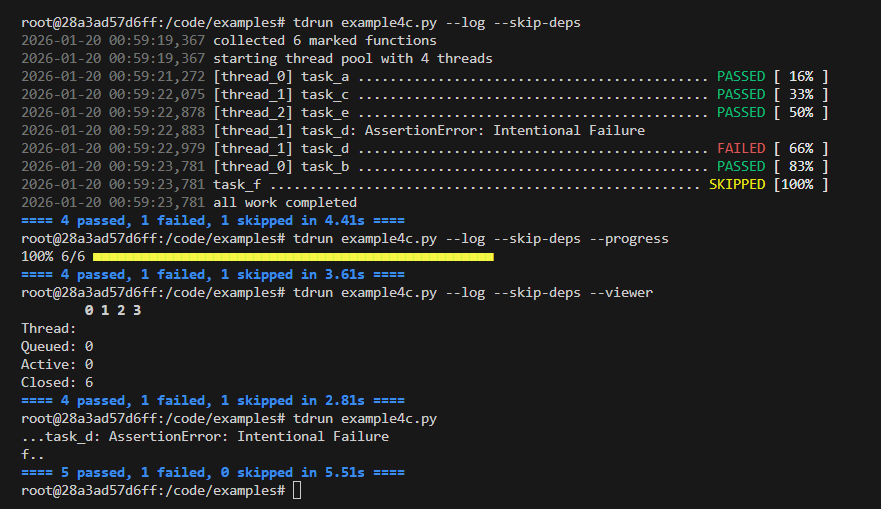
tdrun tag filtering Example
Code
import time
import random
from faker import Faker
from threaded_order import dmark, ThreadProxyLogger
logger = ThreadProxyLogger()
def setup_state(state):
state.update({
'faker': Faker()
})
def run(name, state, deps=None, fail=False):
with state['_state_lock']:
last_name = state['faker'].last_name()
sleep = random.uniform(.5, 3.5)
logger.debug(f'{name} \"{last_name}\" running - sleeping {sleep:.2f}s')
time.sleep(sleep)
if fail:
assert False, 'Intentional Failure'
else:
results = []
for dep in (deps or []):
dep_result = state.get(dep, '--no-result--')
results.append(f'{name}.{dep_result}')
if not results:
results.append(name)
logger.info(f'{name} passed')
state[name] = '|'.join(results)
@dmark(with_state=True, tags='layer1')
def test_a(state): return run('test_a', state)
@dmark(with_state=True, after=['test_a'], tags='layer2')
def test_b(state): return run('test_b', state, deps=['test_a'])
@dmark(with_state=True, after=['test_a'], tags='layer2')
def test_c(state): return run('test_c', state, deps=['test_a'])
@dmark(with_state=True, after=['test_c'], tags='layer3')
def test_d(state): return run('test_d', state, deps=['test_c'], fail=True)
@dmark(with_state=True, after=['test_c'], tags='layer3')
def test_e(state): return run('test_e', state, deps=['test_c'])
@dmark(with_state=True, after=['test_b', 'test_d'], tags='layer4')
def test_f(state): return run('test_f', state, deps=['test_b', 'test_d'])
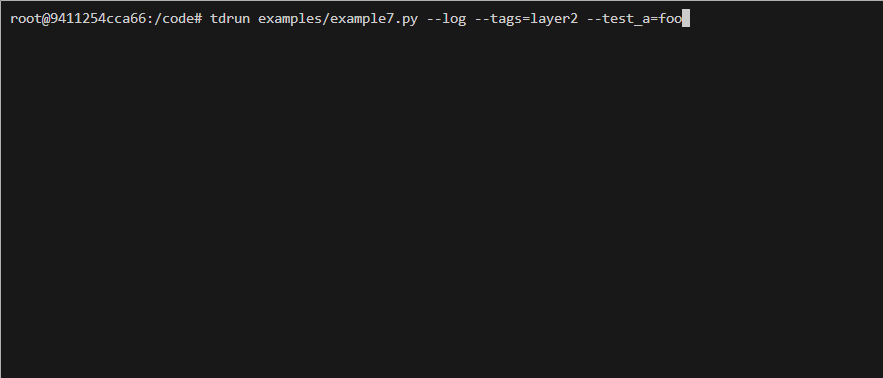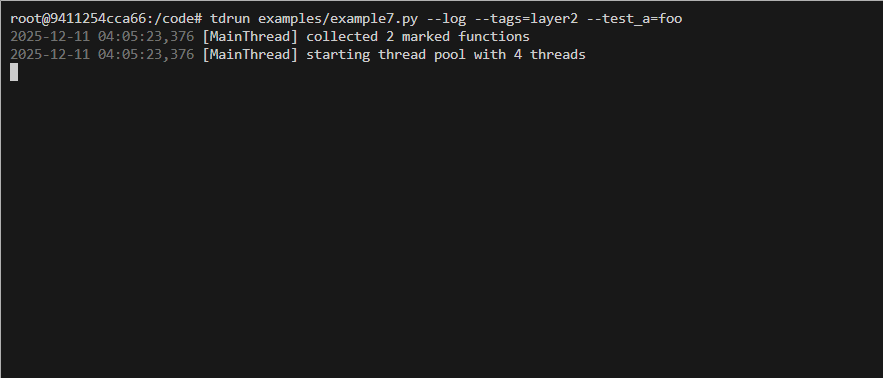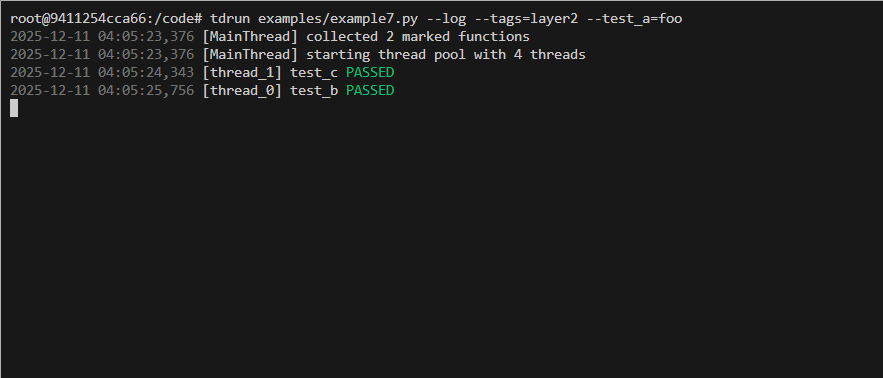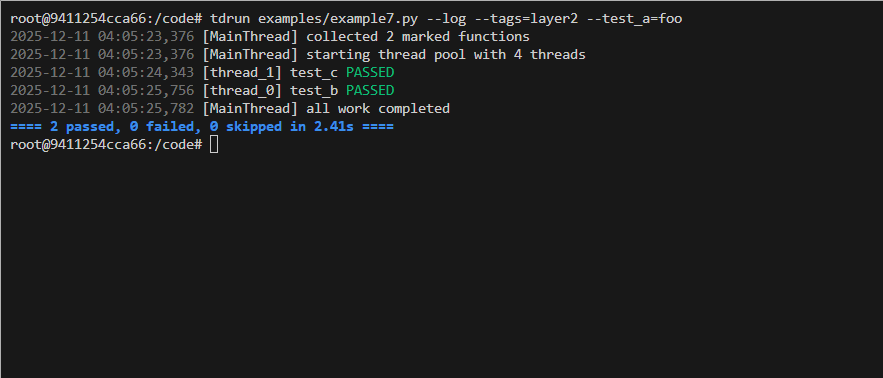
ProgressBar Integration Example
Can be done by using the on_task_done callback. See example5

Development
Clone the repository and ensure the latest version of Docker is installed on your development server.
Build the Docker image:
docker image build \
-t threaded-order:latest .
Run the Docker container:
docker container run \
--rm \
-it \
-v $PWD:/code \
threaded-order:latest \
bash
Execute the dev pipeline:
make dev
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file threaded_order-1.5.3.tar.gz.
File metadata
- Download URL: threaded_order-1.5.3.tar.gz
- Upload date:
- Size: 25.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
65dd29c457ef4d5244cb0ab03b83deaccfb13dc0f88e2f5f5049a9ac212a26f3
|
|
| MD5 |
51338ba6e01769fcddcb4b83e82f6c76
|
|
| BLAKE2b-256 |
94b3247f74be9d31f9d2b94277db1dc4cb90b47e9ef8bef65c663643d00a3d96
|
File details
Details for the file threaded_order-1.5.3-py3-none-any.whl.
File metadata
- Download URL: threaded_order-1.5.3-py3-none-any.whl
- Upload date:
- Size: 23.3 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.12.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c01bbc98971dc3890b23b302da45f032c8b9b4e62ed7751d0db96658274b85dd
|
|
| MD5 |
72527c382fabdfdd422c174fc877ffeb
|
|
| BLAKE2b-256 |
c69373dddf1ed75a141a3402f6a73545f2afad9777b36a87a0dc25b6ee91747e
|







