PyTorch Sparse Linear Algebra - Differentiable sparse solvers with CUDA support


Project description

torch-sla
PyTorch Sparse Linear Algebra - A differentiable sparse linear equation solver library with multiple backends.






Introduction • Installation • API Reference • Examples • Benchmarks
Features
- Differentiable: gradients flow through solves, factorizations, and eigensolves via
torch.autograd - Six verified backends:
pytorchnative Krylov (CPU/CUDA/ROCm),scipy(CPU),cudss(NVIDIA CUDA),strumpackdirect (CPU/CUDA/ROCm),pyamg(CPU),amgx(NVIDIA CUDA) — each checked to ‖Ax−b‖/‖b‖ at or near machine precision - Batched operations: batched sparse tensors
[..., M, N, ...] - Property detection: auto-detect symmetry and positive definiteness
- Solver auto-selection: picks a backend and method from the device, dtype, and problem size
- Distributed: domain decomposition with halo exchange (CFD/FEM style)
- Two classes:
SparseTensor(single process) andDSparseTensor(distributed), exposing solve, norm, eigs, and more - Nonlinear solve: adjoint-based Newton/Anderson with implicit differentiation
Installation
# Basic installation (CPU solvers: scipy + pytorch-native)
pip install torch-sla
# NVIDIA GPU direct solver (CUDA 12+, Linux/Windows)
pip install torch-sla[cudss] # + cuDSS (fastest direct solver on NVIDIA)
# CPU AMG
pip install torch-sla[pyamg] # + PyAMG (CPU AMG setup + on-device V-cycle)
# NOTE: STRUMPACK (direct, CPU/CUDA/ROCm) and AmgX (NVIDIA GPU) are NOT pip
# extras — they are prebuilt wheels on GitHub Releases (see next section).
# Full installation with all PyPI-installable runtime backends (no dev/docs;
# does NOT include the native torch-amgx / torch-strumpack release wheels)
pip install torch-sla[all]
# From source (for development)
git clone https://github.com/walkerchi/torch-sla.git
cd torch-sla
pip install -e ".[dev]" # development tools (pytest, black, isort, mypy)
pip install -e ".[docs]" # documentation tools (sphinx, furo)
Native backends (torch-amgx / torch-strumpack): GitHub Releases, not PyPI
The two compiled backends are PyTorch C++/CUDA extensions and are not published on PyPI (PyPI upload is unavailable). Download a prebuilt wheel from GitHub Releases:
- torch-amgx — https://github.com/sparsexlab/torch-amgx/releases — Linux
- Windows, py3.10–3.13, CUDA 12.4 / 12.6 / 12.8 (cu12.8 includes Blackwell
sm_100/sm_120). Wheel filenames carry a per-CUDA build tag0_cu124/0_cu126/0_cu128.
- Windows, py3.10–3.13, CUDA 12.4 / 12.6 / 12.8 (cu12.8 includes Blackwell
- torch-strumpack — https://github.com/sparsexlab/torch-strumpack/releases
— Linux (cpu/cuda/rocm) + macOS arm64, py3.10–3.13. Windows (CPU) is
supported — STRUMPACK builds with
clang-cl(C/C++) +flang(Fortran) from conda-forge, linked against MSVC-built torch (clean-env solve ≈ 1.7e-16 relative residual); a prebuilt Windows wheel via CI is being added.
ABI caveat: each wheel is ABI-tied to both the CUDA version and
the specific PyTorch version it was built against. You must (a) pick the wheel
whose 0_cuXXX tag matches torch.version.cuda, and (b) have a matching
torch version. A mismatch fails at import with DLL load failed ... procedure not found (Windows) or an undefined-symbol error (Linux). Install
the exact asset URL with --no-deps:
# Example: torch-amgx for CUDA 12.6 + CPython 3.13 (use the real URL from the
# Releases page matching your torch / CUDA / Python)
pip install --no-deps \
https://github.com/sparsexlab/torch-amgx/releases/download/<tag>/torch_amgx-<ver>-0_cu126-cp313-cp313-linux_x86_64.whl
Note: The core install (
pip install torch-sla) pulls intorch,numpy,scipy, andninja— enough to run CPU solvers out of the box.torch-sla[all]additionally bundlespytestandnvmath-python, but does not include[dev],[docs], or the nativetorch-amgx/torch-strumpackrelease wheels — install those separately if needed.
After installation, you can inspect which backends are available on your machine:
import torch_sla
torch_sla.show_backends()
Quick Start
Basic Solve
import torch
from torch_sla import SparseTensor
# Create sparse matrix from dense (for small matrices)
dense = torch.tensor([[4.0, -1.0, 0.0],
[-1.0, 4.0, -1.0],
[ 0.0, -1.0, 4.0]], dtype=torch.float64)
A = SparseTensor.from_dense(dense)
# Solve Ax = b
b = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float64)
x = A.solve(b)
# Specify backend and method
x = A.solve(b, backend='scipy', method='lu')
CUDA Solve
# Move to CUDA
A_cuda = A.cuda()
b_cuda = b.cuda()
# Auto-selects cudss+cholesky (best for CUDA)
x = A_cuda.solve(b_cuda)
# Or explicitly specify
x = A_cuda.solve(b_cuda, backend='cudss', method='cholesky')
# For very large problems (DOF > 2M), use iterative
x = A_cuda.solve(b_cuda, backend='pytorch', method='cg')
Recommended Backends
Based on benchmarks on 2D Poisson equations (tested up to 400M DOF multi-GPU):
| Problem Size | CPU | CUDA |
|---|---|---|
| Small (< 100K DOF) | scipy+lu |
cudss+cholesky |
| Medium (100K - 2M DOF) | scipy+lu |
cudss+cholesky |
| Large (2M - 169M DOF) | pytorch+cg |
pytorch+cg |
| Very Large (> 169M DOF) | DSparseTensor multi-process |
DSparseTensor multi-GPU |
Key Insights
- PyTorch CG+Jacobi scales to 169M+ DOF on single GPU with near-linear O(n^1.1) complexity
- Multi-GPU scales to 400M+ DOF with DSparseTensor domain decomposition (3x H200)
- Direct solvers limited to ~2M DOF due to memory (O(n^1.5) fill-in)
- Use float64 for best convergence with iterative solvers
- Trade-off: Direct = machine precision (~1e-14), Iterative = ~1e-6 but 100x faster
Backends and Methods
Available Backends
All 6 backends are verified correct — each is checked against a reference
solution with relative residual ‖Ax−b‖/‖b‖ at/near machine precision
(measured strumpack ≈ 3e-13, amgx ≈ 5.6e-13).
| Backend | Device | Description | Recommended For |
|---|---|---|---|
scipy |
CPU | SciPy (LU/UMFPACK) | CPU default - fast + machine precision |
pytorch |
CPU/CUDA/ROCm | PyTorch-native Krylov (CG, BiCGStab, GMRES, MINRES, LSQR, LSMR) | Very large problems (> 2M DOF); device-agnostic incl. AMD ROCm |
cudss |
CUDA | NVIDIA cuDSS (LU, Cholesky, LDLT) | CUDA default - fastest direct (NVIDIA only) |
strumpack |
CPU/CUDA/ROCm | STRUMPACK multifrontal direct (LU) via torch-strumpack | Portable direct solver, incl. AMD ROCm |
pyamg |
CPU/CUDA/ROCm | PyAMG (Ruge-Stuben / smoothed-aggregation AMG) | CPU AMG setup + on-device V-cycle |
amgx |
CUDA | NVIDIA AmgX (AMG, PCG, PBiCGStab, FGMRES) via torch-amgx | NVIDIA GPU AMG/Krylov (incl. Blackwell sm_120) |
The two native compiled backends —
strumpack(torch-strumpack) andamgx(torch-amgx) — ship as prebuilt wheels on GitHub Releases, not PyPI. See Installation for the wheel-selection / ABI rules.
Solver Methods
| Method | Backends | Best For | Precision |
|---|---|---|---|
lu |
scipy, strumpack, cudss | General matrices (direct) | Machine precision |
cholesky |
cudss | SPD matrices (fastest) | Machine precision |
ldlt |
cudss | Symmetric matrices | Machine precision |
umfpack |
scipy | General matrices (requires scikit-umfpack) | Machine precision |
cg |
scipy, pytorch, amgx (PCG) | SPD matrices (iterative) | ~1e-6 to 1e-7 |
bicgstab |
scipy, pytorch, amgx (PBiCGStab) | General (iterative) | ~1e-6 to 1e-7 |
gmres |
scipy, pytorch, amgx (FGMRES) | General (iterative) | ~1e-6 to 1e-7 |
minres |
scipy, pytorch | Symmetric indefinite (iterative) | ~1e-6 to 1e-7 |
lsqr / lsmr |
pytorch | Least-squares / rectangular (iterative) | ~1e-6 to 1e-7 |
amg (V-cycle) |
pyamg, amgx | AMG solve/precond on PDE systems | configurable |
Batched Solve
Two batched solving modes are supported:
Batched matrices — same sparsity structure, different values per batch:
batch_size = 4
val_batch = val.unsqueeze(0).expand(batch_size, -1).clone()
# Create batched SparseTensor [B, M, N]
A = SparseTensor(val_batch, row, col, (batch_size, 3, 3))
b = torch.randn(batch_size, 3, dtype=torch.float64)
x = A.solve(b) # Shape: [batch_size, 3]
Multiple right-hand sides — single matrix, multiple RHS columns (factorized once for direct solvers):
A = SparseTensor(val, row, col, (3, 3))
b = torch.randn(3, 5, dtype=torch.float64) # 5 right-hand sides
x = A.solve(b) # Shape: [3, 5]
Distributed Computing (DSparseTensor)
For large-scale problems across multiple GPUs, use domain decomposition.
DSparseTensor mirrors torch.distributed.tensor.DTensor: each rank
holds its own SparseTensor chunk plus a Partition map (owned rows +
halo), and every operation stays in Shard(0) space.
import torch.distributed as dist
from torch.distributed.device_mesh import init_device_mesh
from torch_sla import SparseTensor, DSparseTensor, solve, SolverConfig
dist.init_process_group(backend="nccl") # or "gloo" for CPU
mesh = init_device_mesh("cuda", (dist.get_world_size(),))
A = SparseTensor(val, row, col, shape)
D = DSparseTensor.partition(A, mesh, partition_method="metis")
b_dt = D.scatter(b_global)
# Distributed Krylov solve via the unified API. SolverConfig flows in;
# x_dt is a DTensor[Shard(0)] composable with the rest of FSDP/TP.
with SolverConfig(method="cg", atol=1e-10, rtol=1e-10, maxiter=2000):
x_dt = solve(D, b_dt)
# Residual / global gather via public ops only.
r_dt = b_dt - D @ x_dt
x_full = x_dt.full_tensor()
# Run with 4 GPUs
torchrun --standalone --nproc_per_node=4 your_script.py
Distributed scaling
The canonical distributed linear-solve scaling benchmark measures weak
(fixed DOF/rank), strong (fixed total DOF), and throughput (DOF/s
vs ranks) scaling, reporting wall-clock solve time, the relative residual
||Ax-b||/||b|| (correctness gate), and parallel efficiency:
# run the p=1 baseline first, then larger world sizes (results accumulate)
for P in 1 2 4 8; do
torchrun --standalone --nproc_per_node=$P \
benchmarks/distributed/scaling/distributed_solve_scaling.py \
--mode weak --dof-per-rank 100000
done
# render the accumulated weak/strong/throughput plot
python benchmarks/distributed/scaling/distributed_solve_scaling.py --plot-only
Script: benchmarks/distributed/scaling/distributed_solve_scaling.py.
Full hand-off guide (launch commands, NCCL env vars, metric meanings, how
to extend): docs/source/distributed_scaling.rst.
Gradient Support
All operations support automatic differentiation:
val = val.requires_grad_(True)
b = b.requires_grad_(True)
x = A.solve(b)
loss = x.sum()
loss.backward()
print(val.grad) # Gradient w.r.t. matrix values
print(b.grad) # Gradient w.r.t. RHS
Gradient Support Summary
SparseTensor
| Operation | CPU | CUDA | Notes |
|---|---|---|---|
solve() |
✓ | ✓ | Adjoint method, O(1) graph nodes |
det() |
✓ | ✓ | Adjoint method, ∂det/∂A = det(A)·(A⁻¹)ᵀ |
eigsh() / eigs() |
✓ | ✓ | Adjoint method, O(1) graph nodes |
svd() |
✓ | ✓ | Power iteration, differentiable |
nonlinear_solve() |
✓ | ✓ | Adjoint, params only |
@ (A @ x, SpMV) |
✓ | ✓ | Standard autograd |
@ (A @ B, SpSpM) |
✓ | ✓ | Sparse gradients |
+, -, * |
✓ | ✓ | Element-wise ops |
T() (transpose) |
✓ | ✓ | View-like, gradients flow through |
norm(), sum(), mean() |
✓ | ✓ | Standard autograd |
to_dense() |
✓ | ✓ | Standard autograd |
DSparseTensor (Multi-GPU, VertexShard)
| Operation | CPU (Gloo) | CUDA (NCCL) | Notes |
|---|---|---|---|
D @ x_dt |
✓ | ✓ | Halo exchange + local SpMV → DTensor[Shard(0)] |
solve(D, b_dt) |
✓ | ✓ | CG / BiCGStab / GMRES / FGMRES / MINRES |
D.eigsh(k=) |
✓ | ✓ | Distributed LOBPCG (sharded matvec, global RR) |
D.sum / .mean / .max / .min / .prod |
✓ | ✓ | Cross-rank all_reduce over stored values |
D.norm('fro' / 1 / inf) |
✓ | ✓ | Single all_reduce; 2 falls back to gather |
D.is_symmetric / .is_hermitian / .is_positive_definite |
✓ | ✓ | Cached full_tensor + single-process check |
D.detect_matrix_type() |
✓ | ✓ | Same; for solve(..., matrix_type='auto') |
D.T() / .H() |
✓ | ✓ | Allgather → transpose → repartition on same mesh |
D + s, D * s, D.abs(), etc. |
✓ | ✓ | Local elementwise, same _spec |
D.save(dir) / DSparseTensor.load(dir, mesh) |
✓ | ✓ | Per-rank partition_<rank>.safetensors + metadata.json |
D.full_tensor() |
✓ | ✓ | All-gather to a global SparseTensor |
D.det() / .lu() / .svd() / .condition_number() |
✓ | ✓ | Falls back to full_tensor() + single-proc; emits ResourceWarning |
DSparseTensor (BatchShard, zero-comm matvec)
| Operation | CPU (Gloo) | CUDA (NCCL) | Notes |
|---|---|---|---|
D @ x |
✓ | ✓ | Embarrassingly parallel — each rank multiplies its own batch slice |
D.eigsh(k=) |
✓ | ✓ | Per-rank batched LOBPCG on the local slice (zero comm) |
D.solve_batch_shard(b) |
✓ | ✓ | Per-rank batched solve via SparseTensor.solve_batch (zero comm) |
D.sum / .mean / .max / .min / .norm('fro') |
✓ | ✓ | Single all_reduce across batch ranks |
D.full_tensor() |
✓ | ✓ | Allgather padded values along the sharded batch axis |
Communication per Krylov iteration (VertexShard): halo exchange + 1–2
all_reduce (method-dependent). All vectors stay sharded; no global
gather. BatchShard has zero inter-rank comm in the inner loop.
Persistence (I/O)
Save and load SparseTensor instances using safetensors:
from torch_sla import SparseTensor, save_sparse, load_sparse
A = SparseTensor(val, row, col, shape)
A.save("matrix.safetensors")
A = SparseTensor.load("matrix.safetensors", device="cuda")
# Matrix Market interop
from torch_sla import save_mtx, load_mtx
save_mtx(A, "matrix.mtx")
A = load_mtx("matrix.mtx")
Distributed (DSparseTensor) persistence: gather to a global
SparseTensor via D.full_tensor() and save that.
Nonlinear Solve (Adjoint Method)
Solve nonlinear equations F(u, A, θ) = 0 with automatic differentiation using the adjoint method:
from torch_sla import SparseTensor
# Create sparse matrix (e.g., FEM stiffness matrix)
A = SparseTensor(val, row, col, (n, n))
# Define nonlinear residual: A @ u + u² = f
def residual(u, A, f):
return A @ u + u**2 - f
# Parameters with gradients
f = torch.randn(n, requires_grad=True)
u0 = torch.zeros(n)
# Solve with Newton-Raphson
u = A.nonlinear_solve(residual, u0, f, method='newton')
# Gradients flow via adjoint method
loss = u.sum()
loss.backward()
print(f.grad) # ∂L/∂f via implicit differentiation
Methods:
newton: Newton-Raphson with line search (default, fast convergence)picard: Fixed-point iteration (simple, slow)anderson: Anderson acceleration (memory efficient)
Key Features:
- Memory-efficient adjoint method (no Jacobian storage)
- Jacobian-free Newton-Krylov via autograd
- Multiple parameters with mixed requires_grad
- Integrates with the
SparseTensorclass
Matrix Operations
# Create sparse matrix from dense (for small matrices)
dense = torch.tensor([[4.0, -1.0, 0.0],
[-1.0, 4.0, -1.0],
[ 0.0, -1.0, 4.0]], dtype=torch.float64)
A = SparseTensor.from_dense(dense)
# Norms
norm = A.norm('fro') # Frobenius norm
# Determinant (with gradient support)
det = A.det() # ∂det/∂A = det(A)·(A⁻¹)ᵀ
# Note: CPU is faster for sparse matrices (CUDA uses dense conversion)
# For CUDA tensors: A_cuda.cpu().det() is ~3x faster than A_cuda.det()
# Eigenvalues
eigenvalues, eigenvectors = A.eigsh(k=6)
# SVD
U, S, Vt = A.svd(k=10)
# Matrix-vector product
y = A @ x
# LU factorization for repeated solves
lu = A.lu()
x = lu.solve(b)
Benchmark Results
2D Poisson equation (5-point stencil), NVIDIA H200 (140GB), float64:
Performance Comparison
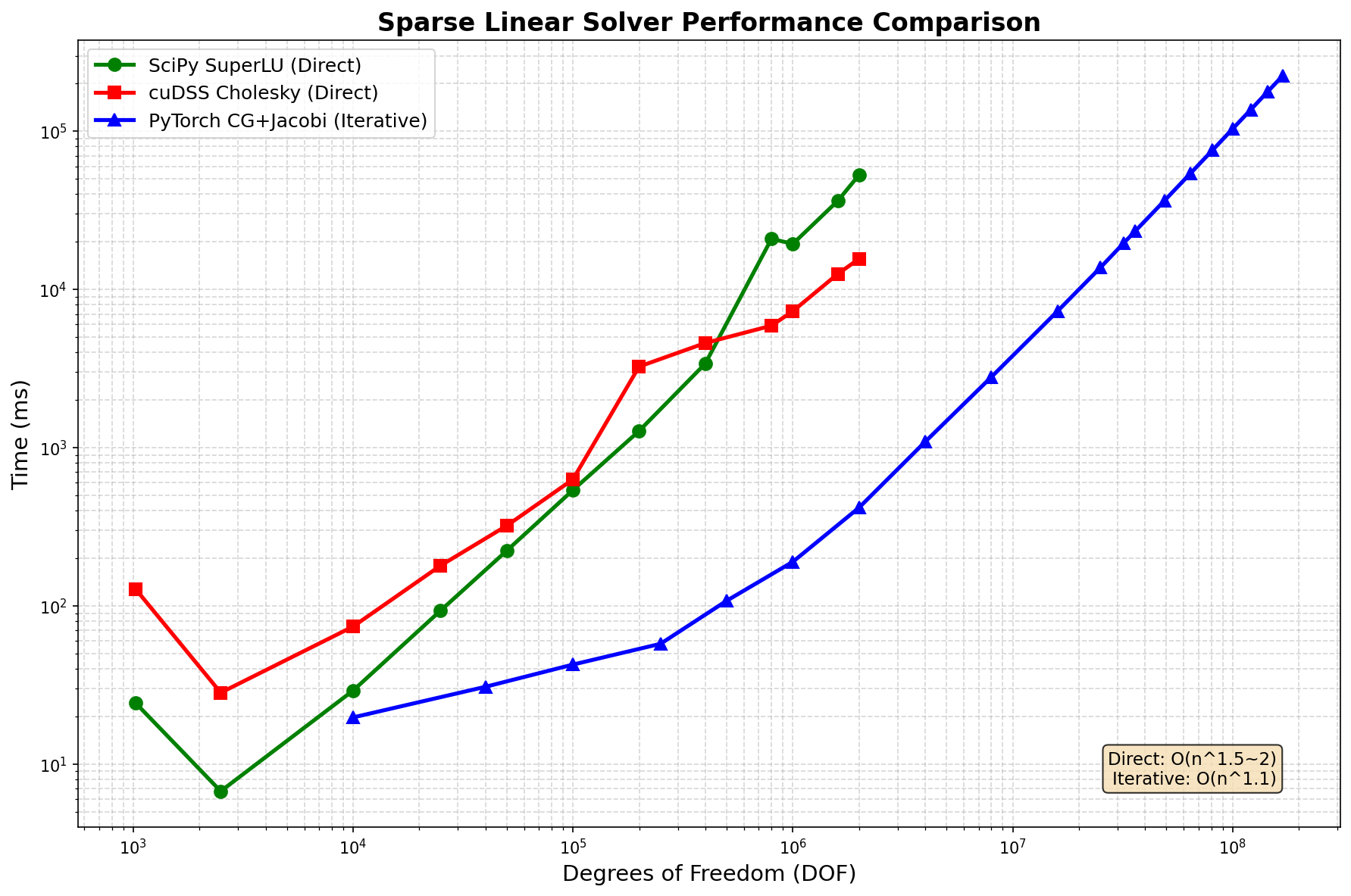
| DOF | SciPy LU | cuDSS Cholesky | PyTorch CG+Jacobi |
|---|---|---|---|
| 10K | 24ms | 128ms | 20ms |
| 100K | 29ms | 630ms | 43ms |
| 1M | 19.4s | 7.3s | 190ms |
| 2M | 52.9s | 15.6s | 418ms |
| 16M | - | - | 7.3s |
| 81M | - | - | 75.9s |
| 169M | - | - | 224s |
Memory Usage
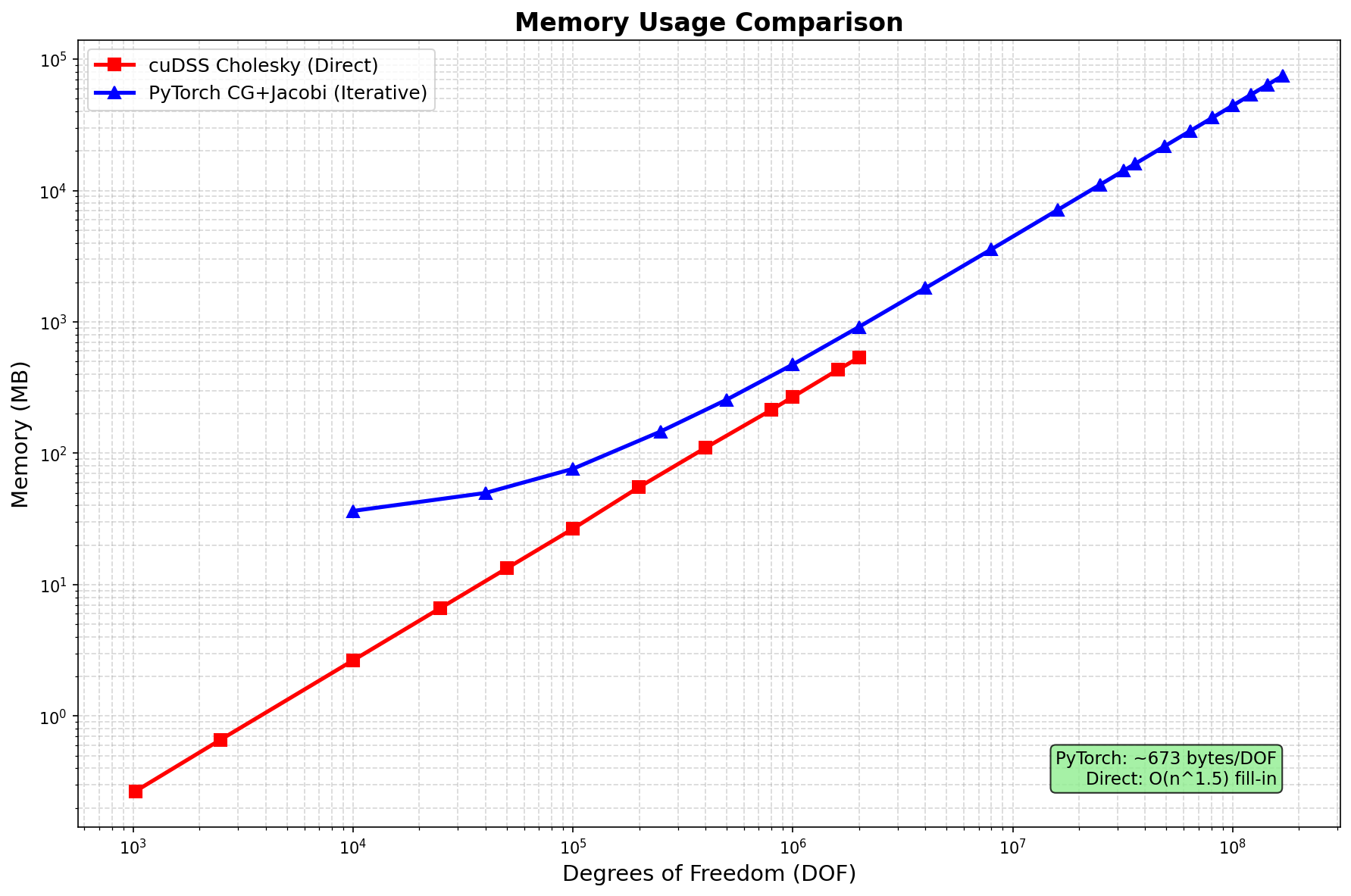
| Method | Memory Scaling | Notes |
|---|---|---|
| SciPy LU | O(n^1.5) fill-in | CPU only, limited to ~2M DOF |
| cuDSS Cholesky | O(n^1.5) fill-in | GPU, limited to ~2M DOF |
| PyTorch CG+Jacobi | O(n) ~443 bytes/DOF | Scales to 169M+ DOF |
Accuracy
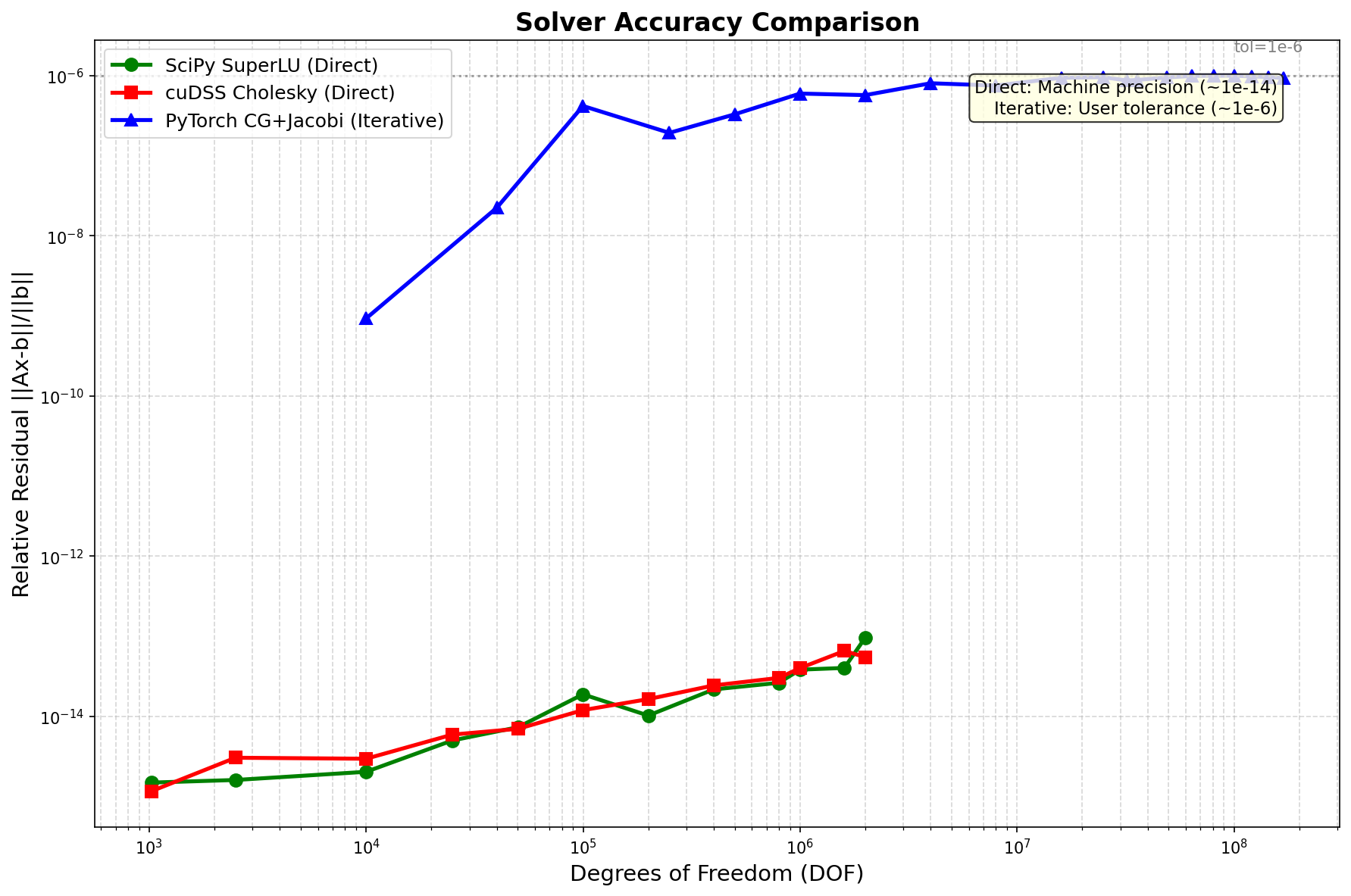
| Method | Precision | Notes |
|---|---|---|
| Direct solvers | ~1e-14 | Machine precision |
| Iterative (tol=1e-6) | ~1e-6 | User-configurable tolerance |
Key Findings
- Iterative solver scales to 169M DOF with O(n^1.1) time complexity
- Direct solvers limited to ~2M DOF due to O(n^1.5~2) memory fill-in
- PyTorch CG+Jacobi is 100x faster than direct solvers at 2M DOF
- Memory efficient: 443 bytes/DOF (vs theoretical minimum 144 bytes/DOF)
- Trade-off: Direct solvers achieve machine precision, iterative achieves ~1e-6
Distributed Solve (Multi-GPU)
3-4x NVIDIA H200 GPUs with NCCL backend:
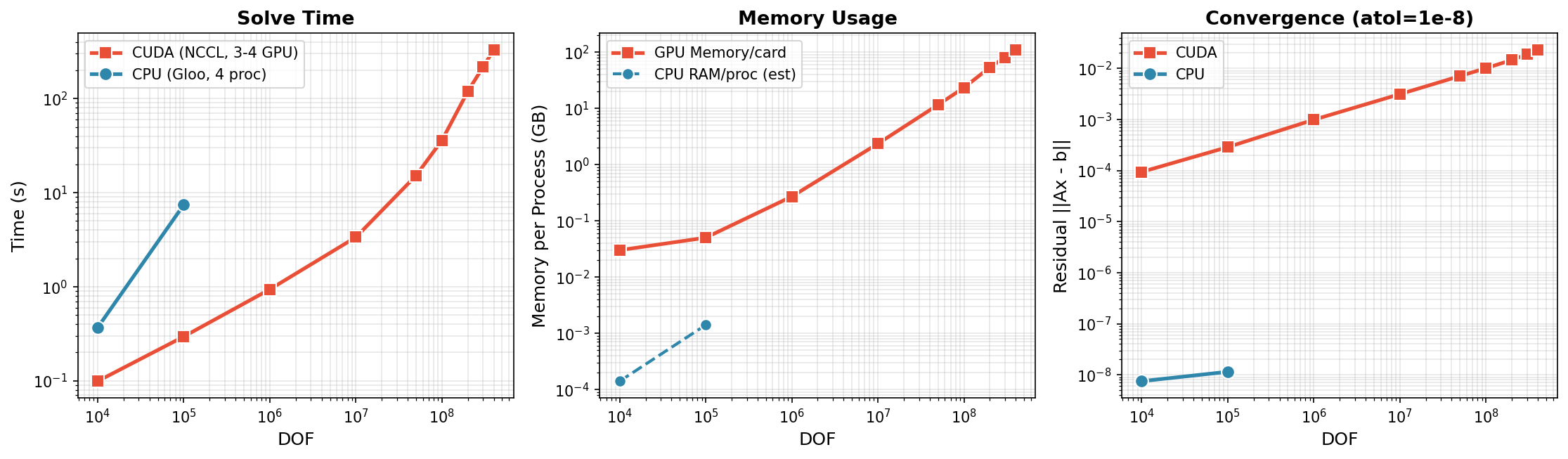
CUDA (3-4 GPU, NCCL) - Scales to 400M DOF:
| DOF | Time | Memory/GPU | Notes |
|---|---|---|---|
| 10K | 0.1s | 0.03 GB | 4 GPU |
| 100K | 0.3s | 0.05 GB | 4 GPU |
| 1M | 0.9s | 0.27 GB | 4 GPU |
| 10M | 3.4s | 2.35 GB | 4 GPU |
| 50M | 15.2s | 11.6 GB | 4 GPU |
| 100M | 36.1s | 23.3 GB | 4 GPU |
| 200M | 119.8s | 53.7 GB | 3 GPU |
| 300M | 217.4s | 80.5 GB | 3 GPU |
| 400M | 330.9s | 110.3 GB | 3 GPU |
Key Findings:
- Scales to 400M DOF on 3x H200 GPUs (110 GB/GPU)
- Near-linear scaling: 10M→400M is 40x DOF, ~100x time
- Memory efficient: ~275 bytes/DOF per GPU
- 500M DOF requires >140GB/GPU, exceeds H200 capacity
# Run distributed solve with 4 GPUs
torchrun --standalone --nproc_per_node=4 examples/distributed/distributed_solve.py
API Reference
Core Classes
SparseTensor- Wrapper with batched solve, norm, eigs, svd methodsSparseTensorList- List of SparseTensors with batched operations and isolated graph priorsDSparseTensor- Distributed sparse tensor with halo exchangeDSparseTensorList- Distributed list for batched graph operations across GPUsLUFactorization- LU factorization for repeated solves
Class Hierarchy

| Single Matrix | List (isolated graph priors) | |
|---|---|---|
| Local | SparseTensor |
SparseTensorList |
| Distributed | DSparseTensor |
DSparseTensorList |
Conversions:
- Horizontal:
to_block_diagonal()/to_connected_components()/to_list() - Vertical:
partition()/gather()
Main Functions
spsolve(val, row, col, shape, b, backend='auto', method='auto')- Solve Ax=bspsolve_coo(A_sparse, b, **kwargs)- Solve using PyTorch sparse tensornonlinear_solve(residual_fn, u0, *params, method='newton')- Solve F(u,θ)=0 with adjoint gradients
Backend Utilities
get_available_backends()- List available backendsget_backend_methods(backend)- List methods for a backendselect_backend(device, n, dtype)- Auto-select backendis_scipy_available(),is_cudss_available(), etc.
Performance Tips
- Use float64 for iterative solvers (better convergence)
- Use cholesky for SPD matrices (2x faster than LU)
- Use scipy+lu for CPU (all sizes)
- Use cudss+cholesky for CUDA (up to ~2M DOF)
- Use pytorch+cg for very large problems (> 2M DOF)
- Use strumpack for a portable GPU direct solve where cuDSS can't go (AMD ROCm), or
amgxfor NVIDIA GPU AMG/Krylov on very large systems - Use LU factorization for repeated solves with same matrix
- Determinant computation:
- Use CPU for sparse matrices - CUDA requires dense conversion (much slower)
- For CUDA tensors, use
.cpu().det().cuda()for better performance - Use float64 for numerical stability
- Avoid for very large matrices (det values can overflow)
- For distributed matrices, be aware of data gather overhead
- Singular matrices may cause LU decomposition to fail
Requirements
- Python >= 3.8
- PyTorch >= 1.10.0
- SciPy (recommended for CPU)
- CUDA Toolkit (for GPU backends)
- nvmath-python (optional, for cuDSS backend)
- torch-amgx (optional, NVIDIA AmgX backend — GitHub Releases wheel)
- torch-strumpack (optional, STRUMPACK direct backend — GitHub Releases wheel)
- pyamg (optional, for PyAMG backend)
Performance Tips
Determinant Computation
# ❌ Slow for sparse matrices
det = A_cuda.det() # 2.5 ms
# ✅ Fast - use CPU even for CUDA tensors
det = A_cuda.cpu().det() # 1.3 ms (1.9x faster!)
Why? cuDSS doesn't expose sparse determinant, requiring O(n²) dense conversion. CPU sparse LU is O(nnz^1.5), much faster for sparse matrices.
Linear Solve
- Small matrices (< 1000): Use CPU with SciPy backend
- Large matrices (> 1000): Use CUDA with cuDSS backend
- Iterative methods: Use
method='cg'ormethod='bicgstab'for large systems
See benchmarks/README.md for detailed performance analysis.
Per-op scaling & capacity
benchmarks/benchmark_all_ops_scaling.py sweeps DOF for every op (spmv, matmat,
solve cg/lu/strumpack, det, logdet, eigsh, norm, transpose, connected_components)
and records latency / throughput / peak memory / CPU util, plus --max-probe for
the largest problem each op sustains. Problems come from torch_sla.datasets; the
backend each op uses is shown in every plot legend (solve_cg → pytorch/cg,
solve_lu → scipy/lu, graph/spmv/norm/transpose → torch-native).
python benchmarks/benchmark_all_ops_scaling.py --quick --max-probe # CPU
python benchmarks/benchmark_all_ops_scaling.py --device cuda # GPU box
On CPU (16-core / 44 GB) to ~10⁶ DOF: transpose is O(1), norm/spmv linear,
connected_components runs in O(log N) FastSV rounds (~4–5× scipy.csgraph),
solve_lu is direct/super-linear (caps capacity first). Latency (ms) is the primary
metric. Plots in benchmarks/results/.
On GPU (--device cuda, RTX 4070 Ti SUPER) the device-agnostic ops run unchanged:
connected_components is ~20× faster than CPU at 10⁶ DOF (FastSV rounds
parallelise; slope 0.16 vs 0.76), solve_cg ~10×, transpose unchanged (view op);
and peak_MB becomes real device memory (cuda.max_memory_allocated). GPU plots are
prefixed cuda_.
benchmarks/benchmark_distributed_scaling.py adds strong/weak scaling for the
distributed ops (matvec, cg, eigsh) across ranks. On a single CPU box over gloo
scaling is communication-bound (no real interconnect), but results are rank-invariant
(same eigenvalue / residual at every world size, incl. non-monotone partitions) —
real speedup needs multi-GPU + NCCL.
Contributing
We welcome contributions! Please see CONTRIBUTING.md for:
- Development workflow
- Code conventions
- Testing guidelines
- Benchmark standards
- Release process (push a
vX.Y.Ztag → auto-publish to PyPI)
Quick conventions:
- Benchmarks:
benchmarks/benchmark_<feature>.py→results/benchmark_<feature>/ - Examples:
examples/<feature>.py - Tests:
tests/test_<module>.py
See TODO.md for the development roadmap.
License
Apache License 2.0 - Copyright 2024-2026 Mingyuan Chi and Shizheng Wen. See LICENSE.
Citation
If you find this library useful, please cite our paper:
@article{chi2026torchsla,
title={torch-sla: Differentiable Sparse Linear Algebra with Adjoint Solvers and Sparse Tensor Parallelism for PyTorch},
author={Chi, Mingyuan and Wen, Shizheng},
journal={arXiv preprint arXiv:2601.13994},
year={2026},
url={https://arxiv.org/abs/2601.13994}
}
Project details


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file torch_sla-0.3.2.tar.gz.
File metadata
- Download URL: torch_sla-0.3.2.tar.gz
- Upload date:
- Size: 220.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7cd0cedb87535483e616fd019c6ffcc7ca33809fad7ac769cfba65cc3c7c7491
|
|
| MD5 |
c7ca9e0b08797a72569ffcd805db1da9
|
|
| BLAKE2b-256 |
5596dbc0765d9b716e0c854b6a4a5e33d16abf7f6a40b265ccd5ca81dfb78e0e
|
Provenance
The following attestation bundles were made for torch_sla-0.3.2.tar.gz:
Publisher:
publish.yml on sparsexlab/torch-sla
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
torch_sla-0.3.2.tar.gz -
Subject digest:
7cd0cedb87535483e616fd019c6ffcc7ca33809fad7ac769cfba65cc3c7c7491 - Sigstore transparency entry: 1965598059
- Sigstore integration time:
-
Permalink:
sparsexlab/torch-sla@8f96715b38b96b4ac5b8742ff527f42b3c217274 -
Branch / Tag:
refs/tags/v0.3.2 - Owner: https://github.com/sparsexlab
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@8f96715b38b96b4ac5b8742ff527f42b3c217274 -
Trigger Event:
push
-
Statement type:
File details
Details for the file torch_sla-0.3.2-py3-none-any.whl.
File metadata
- Download URL: torch_sla-0.3.2-py3-none-any.whl
- Upload date:
- Size: 239.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
72ce1dd6499d238883ccb6d7f9f22ebe20dc39aeff6e59cf0f81dc1772ac97b7
|
|
| MD5 |
426bc1c2e27e02e4e311e43f20660a29
|
|
| BLAKE2b-256 |
40b292cab5c85f9b751802f83bdd00348bbb90b7402d42447ce5fe0597889d32
|
Provenance
The following attestation bundles were made for torch_sla-0.3.2-py3-none-any.whl:
Publisher:
publish.yml on sparsexlab/torch-sla
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
torch_sla-0.3.2-py3-none-any.whl -
Subject digest:
72ce1dd6499d238883ccb6d7f9f22ebe20dc39aeff6e59cf0f81dc1772ac97b7 - Sigstore transparency entry: 1965598111
- Sigstore integration time:
-
Permalink:
sparsexlab/torch-sla@8f96715b38b96b4ac5b8742ff527f42b3c217274 -
Branch / Tag:
refs/tags/v0.3.2 - Owner: https://github.com/sparsexlab
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@8f96715b38b96b4ac5b8742ff527f42b3c217274 -
Trigger Event:
push
-
Statement type:







