PyTorch Sparse Linear Algebra - Differentiable sparse solvers with CUDA support
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Project description

torch-sla
PyTorch Sparse Linear Algebra - A differentiable sparse linear equation solver library with multiple backends.





📖 Introduction • 🔧 Installation • 📚 API Reference • 💡 Examples • 📊 Benchmarks
Features
- 🔥 Differentiable: Full gradient support through
torch.autograd - 🚀 Multiple Backends: SciPy, Eigen (CPU), cuSOLVER, cuDSS, PyTorch-native (CUDA)
- 📦 Batched Operations: Support for batched sparse tensors
[..., M, N, ...] - 🎯 Property Detection: Auto-detect symmetry and positive definiteness
- ⚡ High Performance: Auto-selects best solver based on device, dtype, and problem size
- 🌐 Distributed: Domain decomposition with halo exchange (CFD/FEM style)
- 🔧 Easy to Use:
SparseTensorclass with solve, norm, eigs methods - 🧮 Nonlinear Solve: Adjoint-based Newton/Anderson solvers with implicit differentiation
Installation
# Basic installation
pip install torch-sla
# With cuDSS support (CUDA 12+, recommended for GPU)
pip install torch-sla[cuda]
# Full installation with all dependencies
pip install torch-sla[all]
# From source (for development)
git clone https://github.com/walkerchi/torch-sla.git
cd torch-sla
pip install -e ".[dev]"
Note: cuDSS (
nvidia-cudss-cu12) is now available on PyPI! Installingtorch-sla[cuda]will automatically include it.
Quick Start
Basic Solve
import torch
from torch_sla import SparseTensor
# Create sparse matrix in COO format
val = torch.tensor([4.0, -1.0, -1.0, 4.0, -1.0, -1.0, 4.0], dtype=torch.float64)
row = torch.tensor([0, 0, 1, 1, 1, 2, 2])
col = torch.tensor([0, 1, 0, 1, 2, 1, 2])
# Create SparseTensor
A = SparseTensor(val, row, col, (3, 3))
# Solve Ax = b
b = torch.tensor([1.0, 2.0, 3.0], dtype=torch.float64)
x = A.solve(b)
# Specify backend and method
x = A.solve(b, backend='scipy', method='superlu')
CUDA Solve
# Move to CUDA
A_cuda = A.cuda()
b_cuda = b.cuda()
# Auto-selects cudss+cholesky (best for CUDA)
x = A_cuda.solve(b_cuda)
# Or explicitly specify
x = A_cuda.solve(b_cuda, backend='cudss', method='cholesky')
# For very large problems (DOF > 2M), use iterative
x = A_cuda.solve(b_cuda, backend='pytorch', method='cg')
Recommended Backends
Based on benchmarks on 2D Poisson equations (tested up to 169M DOF):
| Problem Size | CPU | CUDA | Notes |
|---|---|---|---|
| Small (< 100K DOF) | scipy+superlu |
cudss+cholesky |
Direct solvers, machine precision |
| Medium (100K - 2M DOF) | scipy+superlu |
cudss+cholesky |
cuDSS is fastest on GPU |
| Large (2M - 169M DOF) | N/A | pytorch+cg |
Iterative only, ~1e-6 precision |
Key Insights
- PyTorch CG+Jacobi scales to 169M+ DOF with near-linear O(n^1.1) complexity
- Direct solvers limited to ~2M DOF due to memory (O(n^1.5) fill-in)
- Use float64 for best convergence with iterative solvers
- Trade-off: Direct = machine precision, Iterative = ~1e-6 but 100x faster
Backends and Methods
Available Backends
| Backend | Device | Description | Recommended For |
|---|---|---|---|
scipy |
CPU | SciPy (SuperLU/UMFPACK) | CPU default - fast + machine precision |
eigen |
CPU | Eigen C++ (CG, BiCGStab) | Alternative CPU iterative |
cudss |
CUDA | NVIDIA cuDSS (LU, Cholesky, LDLT) | CUDA default - fastest direct |
cusolver |
CUDA | NVIDIA cuSOLVER | Not recommended (slower, no float32) |
pytorch |
CUDA | PyTorch-native (CG, BiCGStab) | Very large problems (> 2M DOF) |
Solver Methods
| Method | Backends | Best For | Precision |
|---|---|---|---|
superlu |
scipy | General matrices | Machine precision |
cholesky |
cudss, cusolver | SPD matrices (fastest) | Machine precision |
ldlt |
cudss | Symmetric matrices | Machine precision |
lu |
cudss, cusolver | General matrices | Machine precision |
cg |
scipy, eigen, pytorch | SPD matrices (iterative) | ~1e-6 to 1e-7 |
bicgstab |
scipy, eigen, pytorch | General (iterative) | ~1e-6 to 1e-7 |
Batched Solve
# Batched matrices: same structure, different values
batch_size = 4
val_batch = val.unsqueeze(0).expand(batch_size, -1).clone()
# Create batched SparseTensor [B, M, N]
A = SparseTensor(val_batch, row, col, (batch_size, 3, 3))
# Batched solve
b = torch.randn(batch_size, 3, dtype=torch.float64)
x = A.solve(b) # Shape: [batch_size, 3]
Distributed Computing (DSparseMatrix)
For large-scale problems across multiple GPUs, use domain decomposition:
import torch.distributed as dist
from torch_sla.distributed import DSparseMatrix, partition_simple
# Initialize distributed (each process runs this)
dist.init_process_group(backend='nccl') # or 'gloo' for CPU
rank = dist.get_rank()
world_size = dist.get_world_size()
# Each rank creates its local partition
A = DSparseMatrix.from_global(
val, row, col, shape,
num_partitions=world_size,
my_partition=rank,
partition_ids=partition_simple(n, world_size),
device=f'cuda:{rank}'
)
# Distributed CG solve (default: distributed=True)
x_owned = A.solve(b_owned, atol=1e-10)
# Distributed LOBPCG eigenvalues
eigenvalues, eigenvectors_owned = A.eigsh(k=5)
# Local subdomain solve (no global communication)
x_local = A.solve(b_owned, distributed=False)
# Run with 4 GPUs
torchrun --standalone --nproc_per_node=4 your_script.py
Gradient Support
All operations support automatic differentiation:
val = val.requires_grad_(True)
b = b.requires_grad_(True)
x = A.solve(b)
loss = x.sum()
loss.backward()
print(val.grad) # Gradient w.r.t. matrix values
print(b.grad) # Gradient w.r.t. RHS
Gradient Support Summary
SparseTensor
| Operation | CPU | CUDA | Notes |
|---|---|---|---|
solve() |
✓ | ✓ | Adjoint method, O(1) graph nodes |
eigsh() / eigs() |
✓ | ✓ | Adjoint method, O(1) graph nodes |
svd() |
✓ | ✓ | Power iteration, differentiable |
nonlinear_solve() |
✓ | ✓ | Adjoint, params only |
@ (A @ x, SpMV) |
✓ | ✓ | Standard autograd |
@ (A @ B, SpSpM) |
✓ | ✓ | Sparse gradients |
+, -, * |
✓ | ✓ | Element-wise ops |
T() (transpose) |
✓ | ✓ | View-like, gradients flow through |
norm(), sum(), mean() |
✓ | ✓ | Standard autograd |
to_dense() |
✓ | ✓ | Standard autograd |
DSparseMatrix (Multi-GPU)
| Operation | CPU (Gloo) | CUDA (NCCL) | Notes |
|---|---|---|---|
matvec() |
✓ | ✓ | Halo exchange + local SpMV |
solve() |
✓ | ✓ | Distributed CG (default distributed=True) |
eigsh() |
✓ | ✓ | Distributed LOBPCG |
halo_exchange() |
✓ | ✓ | P2P communication with neighbors |
Communication per iteration:
solve(): Halo exchange + 2 all_reduceeigsh(): Halo exchange + O(k²) all_reduce
Note: DSparseMatrix uses true distributed algorithms that only require distributed matvec + global reductions. No data gather is needed for core operations.
Persistence (I/O)
Save and load sparse tensors using safetensors format:
from torch_sla import SparseTensor, DSparseTensor, DSparseMatrix
from torch_sla import load_sparse_as_partition, load_distributed_as_sparse
# Save SparseTensor
A = SparseTensor(val, row, col, shape)
A.save("matrix.safetensors")
# Load SparseTensor
A = SparseTensor.load("matrix.safetensors", device="cuda")
# Save as partitioned (for distributed loading)
A.save_distributed("matrix_dist", num_partitions=4)
# Each rank loads only its partition
rank = dist.get_rank()
partition = DSparseMatrix.load("matrix_dist", rank, world_size)
# Load partitioned data as single SparseTensor
A = load_distributed_as_sparse("matrix_dist")
# Load single file as partition (each rank reads full file, keeps its part)
partition = load_sparse_as_partition("matrix.safetensors", rank, world_size)
Cross-Format Conversion
| Save Format | Load as SparseTensor | Load as DSparseMatrix |
|---|---|---|
A.save("file.safetensors") |
SparseTensor.load("file") |
load_sparse_as_partition("file", rank, world_size) |
A.save_distributed("dir", n) |
load_distributed_as_sparse("dir") |
DSparseMatrix.load("dir", rank, world_size) |
D.save("dir") |
load_distributed_as_sparse("dir") |
DSparseTensor.load("dir") |
Nonlinear Solve (Adjoint Method)
Solve nonlinear equations F(u, A, θ) = 0 with automatic differentiation using the adjoint method:
from torch_sla import SparseTensor
# Create sparse matrix (e.g., FEM stiffness matrix)
A = SparseTensor(val, row, col, (n, n))
# Define nonlinear residual: A @ u + u² = f
def residual(u, A, f):
return A @ u + u**2 - f
# Parameters with gradients
f = torch.randn(n, requires_grad=True)
u0 = torch.zeros(n)
# Solve with Newton-Raphson
u = A.nonlinear_solve(residual, u0, f, method='newton')
# Gradients flow via adjoint method
loss = u.sum()
loss.backward()
print(f.grad) # ∂L/∂f via implicit differentiation
Methods:
newton: Newton-Raphson with line search (default, fast convergence)picard: Fixed-point iteration (simple, slow)anderson: Anderson acceleration (memory efficient)
Key Features:
- Memory-efficient adjoint method (no Jacobian storage)
- Jacobian-free Newton-Krylov via autograd
- Multiple parameters with mixed requires_grad
- Seamless integration with
SparseTensorclass
Matrix Operations
A = SparseTensor(val, row, col, shape)
# Norms
norm = A.norm('fro') # Frobenius norm
# Eigenvalues
eigenvalues, eigenvectors = A.eigsh(k=6)
# SVD
U, S, Vt = A.svd(k=10)
# Matrix-vector product
y = A @ x
# LU factorization for repeated solves
lu = A.lu()
x = lu.solve(b)
Benchmark Results
2D Poisson equation (5-point stencil), NVIDIA H200 (140GB), float64:
Performance Comparison
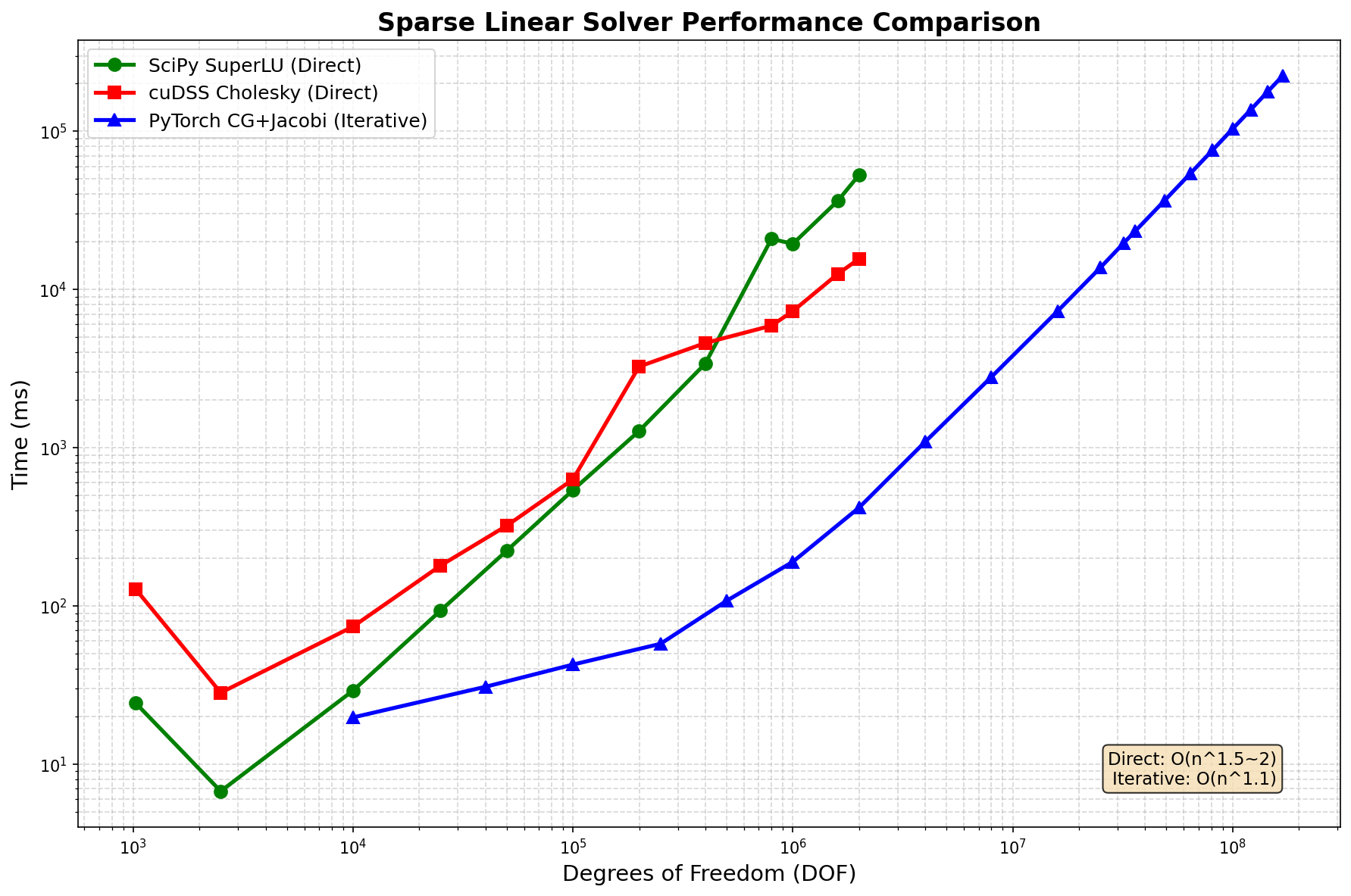
| DOF | SciPy SuperLU | cuDSS Cholesky | PyTorch CG+Jacobi |
|---|---|---|---|
| 10K | 24ms | 128ms | 20ms |
| 100K | 29ms | 630ms | 43ms |
| 1M | 19.4s | 7.3s | 190ms |
| 2M | 52.9s | 15.6s | 418ms |
| 16M | - | - | 7.3s |
| 81M | - | - | 75.9s |
| 169M | - | - | 224s |
Memory Usage
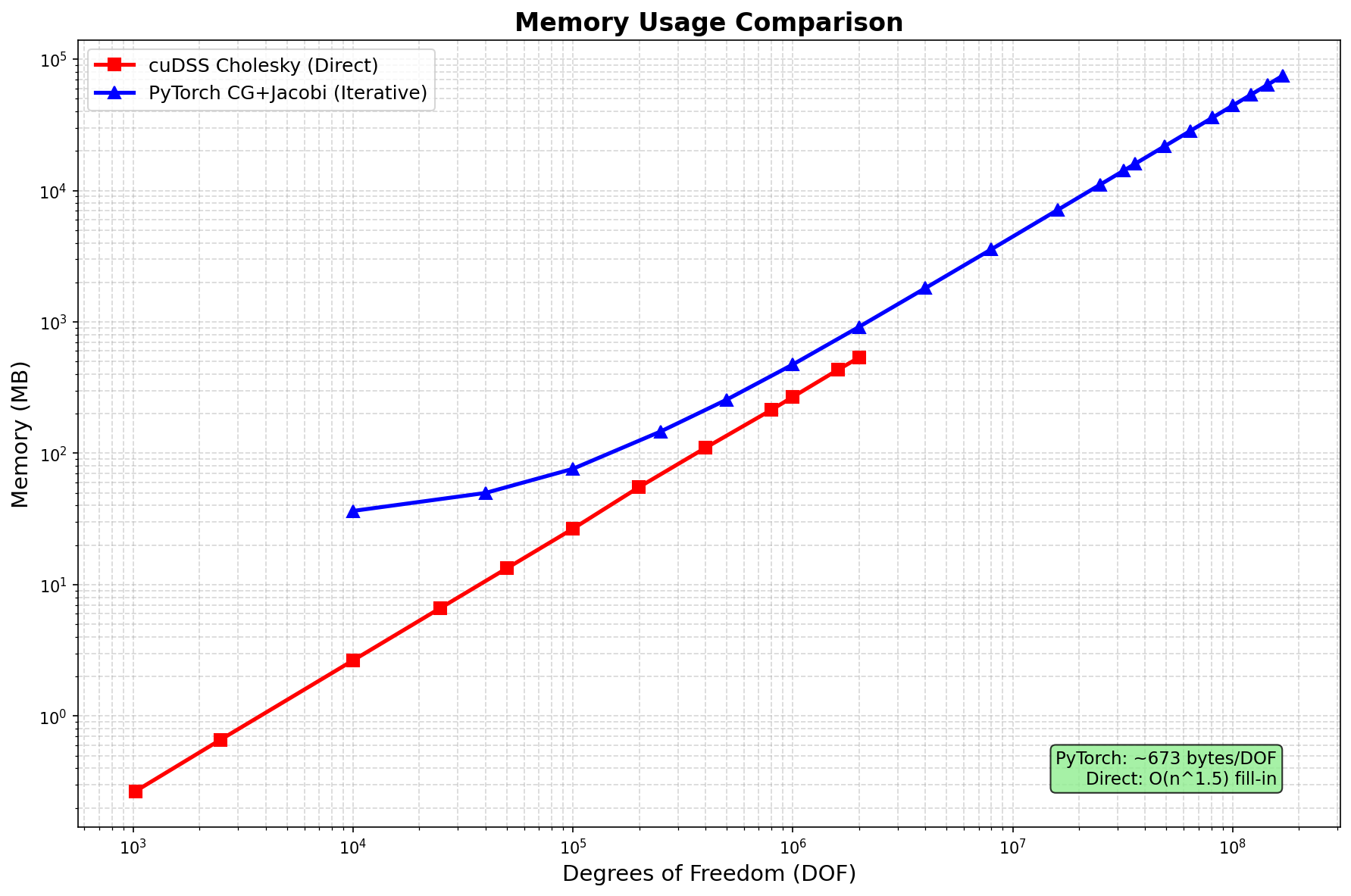
| Method | Memory Scaling | Notes |
|---|---|---|
| SciPy SuperLU | O(n^1.5) fill-in | CPU only, limited to ~2M DOF |
| cuDSS Cholesky | O(n^1.5) fill-in | GPU, limited to ~2M DOF |
| PyTorch CG+Jacobi | O(n) ~443 bytes/DOF | Scales to 169M+ DOF |
Accuracy
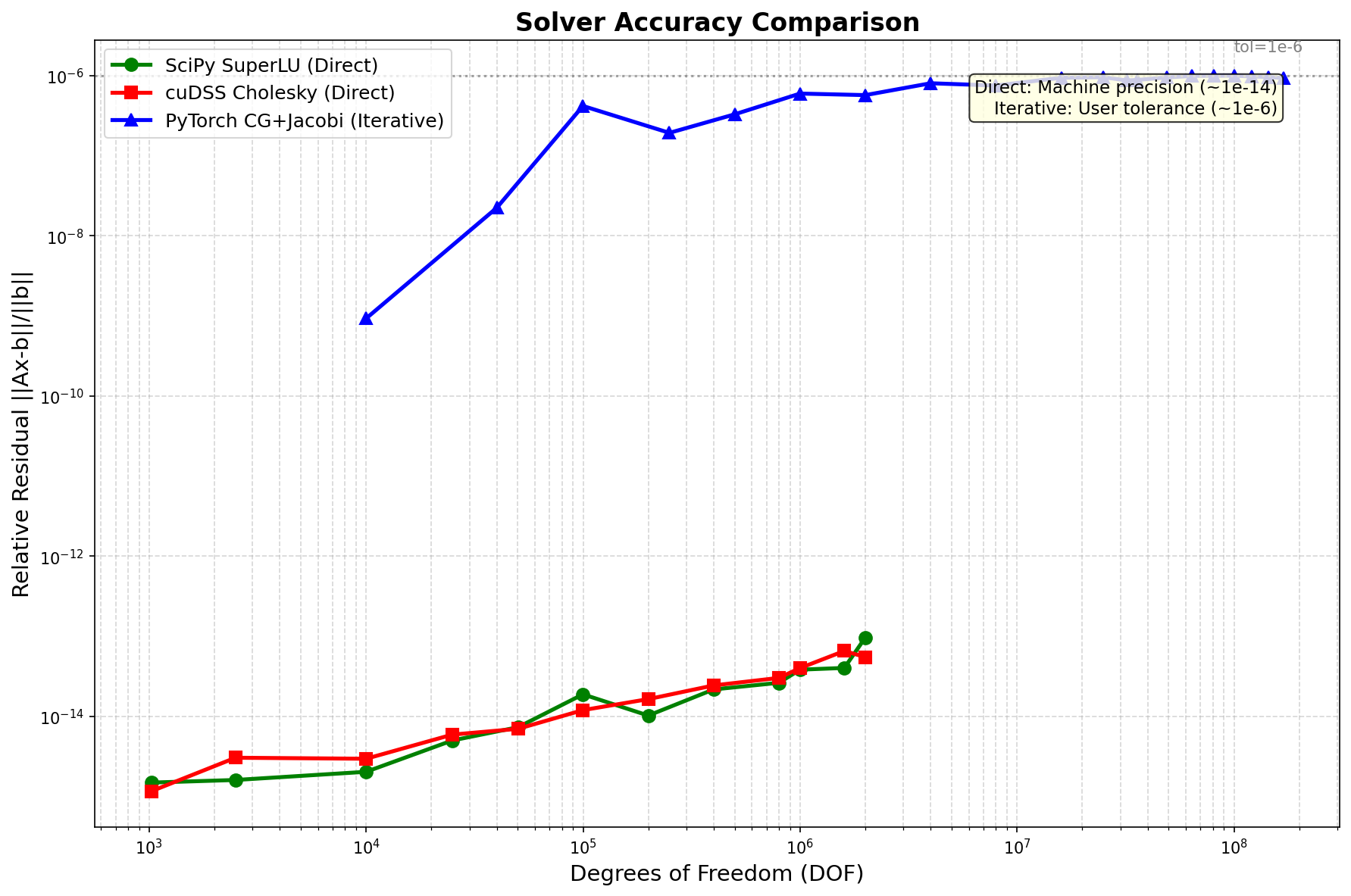
| Method | Precision | Notes |
|---|---|---|
| Direct solvers | ~1e-14 | Machine precision |
| Iterative (tol=1e-6) | ~1e-6 | User-configurable tolerance |
Key Findings
- Iterative solver scales to 169M DOF with O(n^1.1) time complexity
- Direct solvers limited to ~2M DOF due to O(n^1.5~2) memory fill-in
- PyTorch CG+Jacobi is 100x faster than direct solvers at 2M DOF
- Memory efficient: 443 bytes/DOF (vs theoretical minimum 144 bytes/DOF)
- Trade-off: Direct solvers achieve machine precision, iterative achieves ~1e-6
Distributed Solve (Multi-GPU)
4x NVIDIA H200 GPUs with NCCL backend, 4x CPU processes with Gloo:
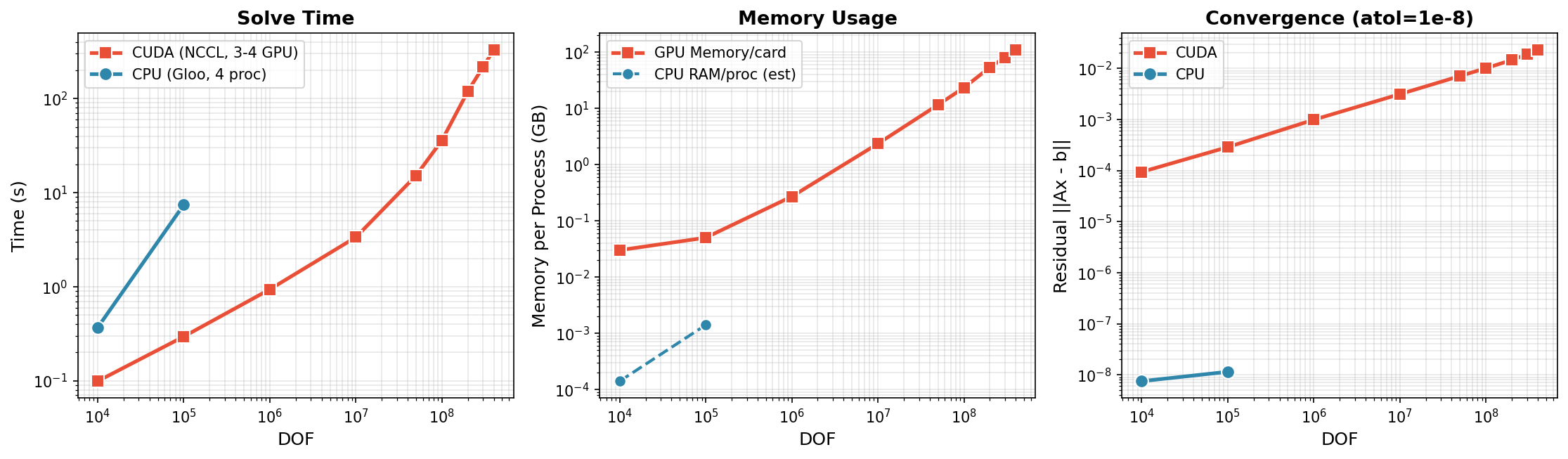
CUDA (4 GPU, NCCL):
| DOF | Time | Residual | Memory/GPU |
|---|---|---|---|
| 10K | 0.18s | 7.5e-9 | 0.03 GB |
| 100K | 0.61s | 1.2e-8 | 0.05 GB |
| 500K | 1.64s | 1.2e-7 | 0.15 GB |
| 1M | 2.82s | 4.0e-7 | 0.27 GB |
| 2M | 6.02s | 1.3e-6 | 0.50 GB |
CPU (4 proc, Gloo):
| DOF | Time | Residual |
|---|---|---|
| 10K | 0.37s | 7.5e-9 |
| 100K | 7.42s | 1.1e-8 |
Key Findings:
- CUDA 12x faster than CPU: 0.6s vs 7.4s for 100K DOF
- Memory evenly distributed: Each GPU uses only 0.5GB for 2M DOF
- Theoretically scales to 500M+ DOF: H200 has 140GB per GPU
# Run distributed solve with 4 GPUs
torchrun --standalone --nproc_per_node=4 examples/distributed/distributed_solve.py
API Reference
Core Classes
SparseTensor- Wrapper with batched solve, norm, eigs, svd methodsSparseTensorList- List of SparseTensors with different structuresDSparseTensor- Distributed sparse tensor with halo exchangeLUFactorization- LU factorization for repeated solves
Main Functions
spsolve(val, row, col, shape, b, backend='auto', method='auto')- Solve Ax=bspsolve_coo(A_sparse, b, **kwargs)- Solve using PyTorch sparse tensornonlinear_solve(residual_fn, u0, *params, method='newton')- Solve F(u,θ)=0 with adjoint gradients
Backend Utilities
get_available_backends()- List available backendsget_backend_methods(backend)- List methods for a backendselect_backend(device, n, dtype)- Auto-select backendis_scipy_available(),is_cudss_available(), etc.
Performance Tips
- Use float64 for iterative solvers (better convergence)
- Use cholesky for SPD matrices (2x faster than LU)
- Use scipy+superlu for CPU (all sizes)
- Use cudss+cholesky for CUDA (up to ~2M DOF)
- Use pytorch+cg for very large problems (> 2M DOF)
- Avoid cuSOLVER - slower than cudss, no float32 support
- Use LU factorization for repeated solves with same matrix
Requirements
- Python >= 3.8
- PyTorch >= 1.10.0
- SciPy (recommended for CPU)
- CUDA Toolkit (for GPU backends)
- nvidia-cudss-cu12 (optional, for cuDSS backend)
License
MIT License - see LICENSE
Citation
@software{torch_sla,
title = {torch-sla: PyTorch Sparse Linear Algebra},
author = {walkerchi},
year = {2024},
url = {https://github.com/walkerchi/torch-sla}
}
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file torch_sla-0.1.2.tar.gz.
File metadata
- Download URL: torch_sla-0.1.2.tar.gz
- Upload date:
- Size: 115.3 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5b54be64f2203b92aedf238f4a419117ddcfe53fb5d57d38e43bdd9f68f67a96
|
|
| MD5 |
3c62f486b939a89872630bee987aef95
|
|
| BLAKE2b-256 |
a85828e580119e99496bf68f7f8e0a13d5a057fcb2ec1bc3fae9b893efcabb3f
|
Provenance
The following attestation bundles were made for torch_sla-0.1.2.tar.gz:
Publisher:
publish.yml on walkerchi/torch-sla
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
torch_sla-0.1.2.tar.gz -
Subject digest:
5b54be64f2203b92aedf238f4a419117ddcfe53fb5d57d38e43bdd9f68f67a96 - Sigstore transparency entry: 822462524
- Sigstore integration time:
-
Permalink:
walkerchi/torch-sla@bd1a0dca665ae345d816f58349b05f7f760cc375 -
Branch / Tag:
refs/tags/v0.1.2 - Owner: https://github.com/walkerchi
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@bd1a0dca665ae345d816f58349b05f7f760cc375 -
Trigger Event:
release
-
Statement type:
File details
Details for the file torch_sla-0.1.2-py3-none-any.whl.
File metadata
- Download URL: torch_sla-0.1.2-py3-none-any.whl
- Upload date:
- Size: 95.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
222441b11c750a01f8429def4f41464fc6018a4319e54b41080840c793c77ee1
|
|
| MD5 |
43ade9ff7b999477a9f7ee413e73ae36
|
|
| BLAKE2b-256 |
b54553ff37ac97fb926818209bb9342622bac022130999b6d5188376f388fbc3
|
Provenance
The following attestation bundles were made for torch_sla-0.1.2-py3-none-any.whl:
Publisher:
publish.yml on walkerchi/torch-sla
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
torch_sla-0.1.2-py3-none-any.whl -
Subject digest:
222441b11c750a01f8429def4f41464fc6018a4319e54b41080840c793c77ee1 - Sigstore transparency entry: 822462557
- Sigstore integration time:
-
Permalink:
walkerchi/torch-sla@bd1a0dca665ae345d816f58349b05f7f760cc375 -
Branch / Tag:
refs/tags/v0.1.2 - Owner: https://github.com/walkerchi
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@bd1a0dca665ae345d816f58349b05f7f760cc375 -
Trigger Event:
release
-
Statement type:







