Lightweight AI server.
Project description
Build custom inference servers in pure Python
Define exactly how inference works for models, agents, RAG, or pipelines.
Control batching, routing, streaming, and orchestration without MLOps glue or config files.

✅ Custom inference logic ✅ 2× faster than FastAPI ✅ Agents, RAG, pipelines, more ✅ Custom logic + control ✅ Any PyTorch model ✅ Self-host or managed ✅ Multi-GPU autoscaling ✅ Batching + streaming ✅ BYO model or vLLM ✅ No MLOps glue code ✅ Easy setup in Python ✅ Serverless support






Why LitServe?
Most serving tools (vLLM, etc..) are built for a single model type and enforce rigid abstractions. They work well until you need custom logic, multiple models, agents, or non standard pipelines. LitServe lets you write your own inference engine in Python. You define how requests are handled, how models are loaded, how batching and routing work, and how outputs are produced. LitServe handles performance, concurrency, scaling, and deployment. Use LitServe to build inference APIs, agents, chatbots, RAG systems, MCP servers, or multi model pipelines.
Run it locally, self host anywhere, or deploy with one click on Lightning AI.
Want the easiest way to host inference?
Over 380,000 developers use Lightning Cloud, the simplest way to run LitServe without managing infrastructure. Deploy with one command, get autoscaling GPUs, monitoring, and a free tier. No cloud setup required. Or self host anywhere.
Quick start
Install LitServe via pip (more options):
pip install litserve
Example 1: Toy inference pipeline with multiple models.
Example 2: Minimal agent to fetch the news (with OpenAI API).
(Advanced examples):
Inference engine example
import litserve as ls
# define the api to include any number of models, dbs, etc...
class InferenceEngine(ls.LitAPI):
def setup(self, device):
self.text_model = lambda x: x**2
self.vision_model = lambda x: x**3
def predict(self, request):
x = request["input"]
# perform calculations using both models
a = self.text_model(x)
b = self.vision_model(x)
c = a + b
return {"output": c}
if __name__ == "__main__":
# 12+ features like batching, streaming, etc...
server = ls.LitServer(InferenceEngine(max_batch_size=1), accelerator="auto")
server.run(port=8000)
Deploy for free to Lightning cloud (or self host anywhere):
# Deploy for free with autoscaling, monitoring, etc...
lightning deploy server.py --cloud
# Or run locally (self host anywhere)
lightning deploy server.py
# python server.py
Test the server: Simulate an http request (run this on any terminal):
curl -X POST http://127.0.0.1:8000/predict -H "Content-Type: application/json" -d '{"input": 4.0}'
Agent example
import re, requests, openai
import litserve as ls
class NewsAgent(ls.LitAPI):
def setup(self, device):
self.openai_client = openai.OpenAI(api_key="OPENAI_API_KEY")
def predict(self, request):
website_url = request.get("website_url", "https://text.npr.org/")
website_text = re.sub(r'<[^>]+>', ' ', requests.get(website_url).text)
# ask the LLM to tell you about the news
llm_response = self.openai_client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": f"Based on this, what is the latest: {website_text}"}],
)
output = llm_response.choices[0].message.content.strip()
return {"output": output}
if __name__ == "__main__":
server = ls.LitServer(NewsAgent())
server.run(port=8000)
Test it:
curl -X POST http://127.0.0.1:8000/predict -H "Content-Type: application/json" -d '{"website_url": "https://text.npr.org/"}'
Key benefits
A few key benefits:
- Deploy any pipeline or model: Agents, pipelines, RAG, chatbots, image models, video, speech, text, etc...
- No MLOps glue: LitAPI lets you build full AI systems (multi-model, agent, RAG) in one place (more).
- Instant setup: Connect models, DBs, and data in a few lines with
setup()(more). - Optimized: autoscaling, GPU support, and fast inference included (more).
- Deploy anywhere: self-host or one-click deploy with Lightning (more).
- FastAPI for AI: Built on FastAPI but optimized for AI - 2× faster with AI-specific multi-worker handling (more).
- Expert-friendly: Use vLLM, or build your own with full control over batching, caching, and logic (more).
⚠️ Not a vLLM or Ollama alternative out of the box. LitServe gives you lower-level flexibility to build what they do (and more) if you need it.
Featured examples
Here are examples of inference pipelines for common model types and use cases.
Toy model: Hello world LLMs: Llama 3.2, LLM Proxy server, Agent with tool use RAG: vLLM RAG (Llama 3.2), RAG API (LlamaIndex) NLP: Hugging face, BERT, Text embedding API Multimodal: OpenAI Clip, MiniCPM, Phi-3.5 Vision Instruct, Qwen2-VL, Pixtral Audio: Whisper, AudioCraft, StableAudio, Noise cancellation (DeepFilterNet) Vision: Stable diffusion 2, AuraFlow, Flux, Image Super Resolution (Aura SR), Background Removal, Control Stable Diffusion (ControlNet) Speech: Text-speech (XTTS V2), Parler-TTS Classical ML: Random forest, XGBoost Miscellaneous: Media conversion API (ffmpeg), PyTorch + TensorFlow in one API, LLM proxy server
Browse 100+ community-built templates
Host anywhere
Self-host with full control, or deploy with Lightning AI in seconds with autoscaling, security, and 99.995% uptime.
Free tier included. No setup required. Run on your cloud
lightning deploy server.py --cloud
https://github.com/user-attachments/assets/ff83dab9-0c9f-4453-8dcb-fb9526726344
Features
| Feature | Self Managed | Fully Managed on Lightning |
|---|---|---|
| Docker-first deployment | ✅ DIY | ✅ One-click deploy |
| Cost | ✅ Free (DIY) | ✅ Generous free tier with pay as you go |
| Full control | ✅ | ✅ |
| Use any engine (vLLM, etc.) | ✅ | ✅ vLLM, Ollama, LitServe, etc. |
| Own VPC | ✅ (manual setup) | ✅ Connect your own VPC |
| (2x)+ faster than plain FastAPI | ✅ | ✅ |
| Bring your own model | ✅ | ✅ |
| Build compound systems (1+ models) | ✅ | ✅ |
| GPU autoscaling | ✅ | ✅ |
| Batching | ✅ | ✅ |
| Streaming | ✅ | ✅ |
| Worker autoscaling | ✅ | ✅ |
| Serve all models: (LLMs, vision, etc.) | ✅ | ✅ |
| Supports PyTorch, JAX, TF, etc... | ✅ | ✅ |
| OpenAPI compliant | ✅ | ✅ |
| Open AI compatibility | ✅ | ✅ |
| MCP server support | ✅ | ✅ |
| Asynchronous | ✅ | ✅ |
| Authentication | ❌ DIY | ✅ Token, password, custom |
| GPUs | ❌ DIY | ✅ 8+ GPU types, H100s from $1.75 |
| Load balancing | ❌ | ✅ Built-in |
| Scale to zero (serverless) | ❌ | ✅ No machine runs when idle |
| Autoscale up on demand | ❌ | ✅ Auto scale up/down |
| Multi-node inference | ❌ | ✅ Distribute across nodes |
| Use AWS/GCP credits | ❌ | ✅ Use existing cloud commits |
| Versioning | ❌ | ✅ Make and roll back releases |
| Enterprise-grade uptime (99.95%) | ❌ | ✅ SLA-backed |
| SOC2 / HIPAA compliance | ❌ | ✅ Certified & secure |
| Observability | ❌ | ✅ Built-in, connect 3rd party tools |
| CI/CD ready | ❌ | ✅ Lightning SDK |
| 24/7 enterprise support | ❌ | ✅ Dedicated support |
| Cost controls & audit logs | ❌ | ✅ Budgets, breakdowns, logs |
| Debug on GPUs | ❌ | ✅ Studio integration |
| 20+ features | - | - |
Performance
LitServe is designed for AI workloads. Specialized multi-worker handling delivers a minimum 2x speedup over FastAPI.
Additional features like batching and GPU autoscaling can drive performance well beyond 2x, scaling efficiently to handle more simultaneous requests than FastAPI and TorchServe.
Reproduce the full benchmarks here (higher is better).
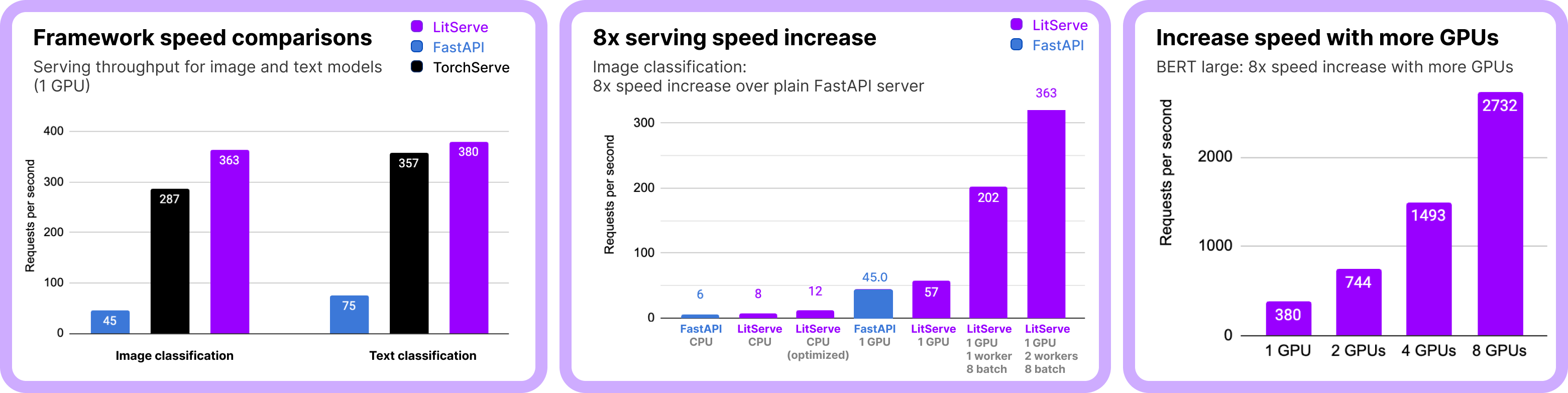
These results are for image and text classification ML tasks. The performance relationships hold for other ML tasks (embedding, LLM serving, audio, segmentation, object detection, summarization etc...).
💡 Note on LLM serving: For high-performance LLM serving (like Ollama/vLLM), integrate vLLM with LitServe, use LitGPT, or build your custom vLLM-like server with LitServe. Optimizations like kv-caching, which can be done with LitServe, are needed to maximize LLM performance.
Community
LitServe is a community project accepting contributions - Let's make the world's most advanced AI inference engine.
Project details
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file litserve-0.2.17.tar.gz.
File metadata
- Download URL: litserve-0.2.17.tar.gz
- Upload date:
- Size: 220.9 kB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
3280f13cfe7591e9f37f4862f4b3023928d5fab59b3bb0dfe5eadacceb9d202f
|
|
| MD5 |
23e3b80871ded11f3e3ebf355786668d
|
|
| BLAKE2b-256 |
54c47be1f90714f51bd4b50dc75333248b824c01143880c8a55c3df496b234e0
|
File details
Details for the file litserve-0.2.17-py3-none-any.whl.
File metadata
- Download URL: litserve-0.2.17-py3-none-any.whl
- Upload date:
- Size: 94.5 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
8ebe6dc4dcb1ade8be14738540df2d7349031741afeefb0f9398a4a64bc35d82
|
|
| MD5 |
7512d51342abb89c6601a1ae2db109cf
|
|
| BLAKE2b-256 |
6b68e6101f1b00e994cc9251d7caf055b0a1102e64296bee4f50acbd5f636ce2
|







