Neural building blocks for speaker diarization

Project description
Neural speaker diarization with pyannote.audio
pyannote.audio is an open-source toolkit written in Python for speaker diarization. Based on PyTorch machine learning framework, it provides a set of trainable end-to-end neural building blocks that can be combined and jointly optimized to build speaker diarization pipelines.
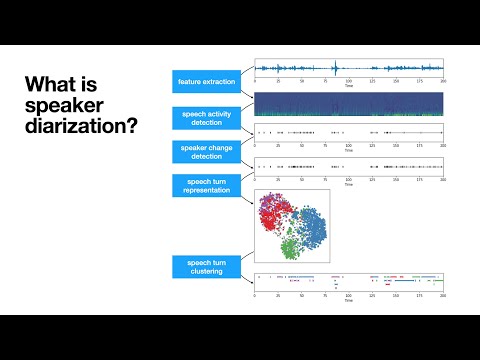
TL;DR 
# instantiate pretrained speaker diarization pipeline
from pyannote.audio import Pipeline
pipeline = Pipeline.from_pretrained("pyannote/speaker-diarization")
# apply pretrained pipeline
diarization = pipeline("audio.wav")
# print the result
for turn, _, speaker in diarization.itertracks(yield_label=True):
print(f"start={turn.start:.1f}s stop={turn.end:.1f}s speaker_{speaker}")
# start=0.2s stop=1.5s speaker_A
# start=1.8s stop=3.9s speaker_B
# start=4.2s stop=5.7s speaker_A
# ...
What's new in pyannote.audio 2.0
For version 2.x of pyannote.audio, I decided to rewrite almost everything from scratch.
Highlights of this release are:
- :exploding_head: much better performance (see Benchmark)
- :snake: Python-first API
- :hugs: pretrained pipelines (and models) on :hugs: model hub
- :zap: multi-GPU training with pytorch-lightning
- :control_knobs: data augmentation with torch-audiomentations
- :boom: Prodigy recipes for model-assisted audio annotation
Installation
Only Python 3.8+ is officially supported (though it might work with Python 3.7)
conda create -n pyannote python=3.8
conda activate pyannote
# pytorch 1.11 is required for speechbrain compatibility
# (see https://pytorch.org/get-started/previous-versions/#v1110)
conda install pytorch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0 -c pytorch
pip install pyannote.audio
Documentation
- Models
- Available tasks explained
- Applying a pretrained model
- Training, fine-tuning, and transfer learning
- Pipelines
- Available pipelines explained
- Applying a pretrained pipeline
- Training a pipeline
- Contributing
- Adding a new model
- Adding a new task
- Adding a new pipeline
- Sharing pretrained models and pipelines
- Miscellaneous
- Training with
pyannote-audio-traincommand line tool - Annotating your own data with Prodigy
- Speaker verification
- Visualization and debugging
- Training with
Frequently asked questions
How does one capitalize and pronounce the name of this awesome library?
📝 Written in lower case: pyannote.audio (or pyannote if you are lazy). Not PyAnnote nor PyAnnotate (sic).
📢 Pronounced like the french verb pianoter. pi like in piano, not py like in python.
🎹 pianoter means to play the piano (hence the logo 🤯).
Pretrained pipelines do not produce good results on my data. What can I do?
- Annotate dozens of conversations manually and separate them into development and test subsets in
pyannote.database. - Optimize the hyper-parameters of the pretained pipeline using the development set. If performance is still not good enough, go to step 3.
- Annotate hundreds of conversations manually and set them up as training subset in
pyannote.database. - Fine-tune the models (on which the pipeline relies) using the training set.
- Optimize the hyper-parameters of the pipeline using the fine-tuned models using the development set. If performance is still not good enough, go back to step 3.
Benchmark
Out of the box, pyannote.audio default speaker diarization pipeline is expected to be much better (and faster) in v2.0 than in v1.1.:
| Dataset | DER% with v1.1 | DER% with v2.0 | Relative improvement |
|---|---|---|---|
| AMI | 29.7% | 18.2% | 38% |
| DIHARD | 29.2% | 21.0% | 28% |
| VoxConverse | 21.5% | 12.8% | 40% |
A more detailed benchmark is available here.
Citations
If you use pyannote.audio please use the following citations:
@inproceedings{Bredin2020,
Title = {{pyannote.audio: neural building blocks for speaker diarization}},
Author = {{Bredin}, Herv{\'e} and {Yin}, Ruiqing and {Coria}, Juan Manuel and {Gelly}, Gregory and {Korshunov}, Pavel and {Lavechin}, Marvin and {Fustes}, Diego and {Titeux}, Hadrien and {Bouaziz}, Wassim and {Gill}, Marie-Philippe},
Booktitle = {ICASSP 2020, IEEE International Conference on Acoustics, Speech, and Signal Processing},
Year = {2020},
}
@inproceedings{Bredin2021,
Title = {{End-to-end speaker segmentation for overlap-aware resegmentation}},
Author = {{Bredin}, Herv{\'e} and {Laurent}, Antoine},
Booktitle = {Proc. Interspeech 2021},
Year = {2021},
}
Support
For commercial enquiries and scientific consulting, please contact me.
Development
The commands below will setup pre-commit hooks and packages needed for developing the pyannote.audio library.
pip install -e .[dev,testing]
pre-commit install
Tests rely on a set of debugging files available in test/data directory.
Set PYANNOTE_DATABASE_CONFIG environment variable to test/data/database.yml before running tests:
PYANNOTE_DATABASE_CONFIG=tests/data/database.yml pytest
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file pyannote.audio-2.0.1.tar.gz.
File metadata
- Download URL: pyannote.audio-2.0.1.tar.gz
- Upload date:
- Size: 14.2 MB
- Tags: Source
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.10.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
0db24fbc89f755e4ec7f4de61830e156d7e4ea2f1bbeb819a1d9c37b11a9a3c1
|
|
| MD5 |
13ac922976812e3b1ca19c4fe7e122c3
|
|
| BLAKE2b-256 |
cbad2b593bd90c8ec26c2e3e2f9dfe984eb4be9d07a9af6b724b74b2056c997c
|
File details
Details for the file pyannote.audio-2.0.1-py2.py3-none-any.whl.
File metadata
- Download URL: pyannote.audio-2.0.1-py2.py3-none-any.whl
- Upload date:
- Size: 385.9 kB
- Tags: Python 2, Python 3
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/4.0.1 CPython/3.10.5
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cb54bae97df9d205e7be2d4d8f3c986139acdcb2d64be7c5c95a1f391cb0f586
|
|
| MD5 |
0705e43c2b8f772b3afa5129116e3b5d
|
|
| BLAKE2b-256 |
9fc8da51d0102791bcd86fb4e50d247fb24f45da4824fdcc948fc7f67754c413
|







