Embedded vector database using the TurboQuant algorithm (arXiv:2504.19874) — zero training, 2-4 bit compression, fast inner-product search
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
 TurboQuantDB
TurboQuantDB




An embedded vector database with a Python API. Built around the TurboQuant algorithm (arXiv:2504.19874) — two-stage quantization with zero training time and 5–10× compression at near-paper recall.
100k vectors at d=1536 fit in ~84 MB on disk (b=4) or ~47 MB (b=2) and run queries with ~200 MB RAM. No daemon, no
train()step, no eval set required to start.
Why TurboQuantDB?
- 🪶 Lightweight —
pip install tqdbis a 10 MB install with no Python dependencies beyond numpy. Runs in your process; no server, no sidecar. - 🧠 No training — codebooks are derived from a closed-form Beta(d/2) marginal at construction; vectors are quantized on the very first insert.
- 💾 5–10× disk compression with strong recall — benchmarked across d=65–3072 with recall / storage / latency trade-offs documented in
docs/BENCHMARKS.md. At d=1536, TQDB reaches near-paper recall under the benchmark configuration while cutting disk ~5×. - ⚡ Low query-time RAM — n=100k at d=200 needs ~17 MB for active search structures; d=1536 needs ~200 MB. Fits comfortably on a laptop.
- 🛡️ Crash-safe by default — writes go through a CRC-protected WAL with truncation guards; reopen replays automatically after crash or power loss. No manual
flush()for normal use. (WAL writes are batched for throughput; an explicitdb.checkpoint()forces durable persistence to a segment.) - 🌍 Cross-platform pre-built wheels — Linux (x86_64 + aarch64), macOS Apple Silicon, Windows. One
pip installeverywhere.
Use TQDB if you're building RAG / search on a laptop, edge device, or single VM and want compression without a training pipeline.
Look elsewhere if you need managed cloud, multi-node replication, SQL joins, or a full enterprise search platform. If your corpus is tiny (<10k vectors), raw-vector stores may be simpler and the compression benefit may not matter yet.
Install
pip install tqdb
Optional integration extras: tqdb[langchain], tqdb[llamaindex], tqdb[migrate] (Chroma + LanceDB import). Build from source: see DEVELOPMENT.md. Upgrading from v0.7: see docs/WHAT_S_NEW_0_8.md.
Quick Start
import numpy as np
from sentence_transformers import SentenceTransformer
from tqdb import Database
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
dim = model.get_sentence_embedding_dimension() # 384
db = Database.open("./my_db", dimension=dim, bits=4, metric="ip", rerank=True)
docs = [
("rust", "Rust uses ownership and borrowing for memory safety."),
("python", "Python prioritizes readability and rapid prototyping."),
("vector", "A vector database stores embeddings for nearest-neighbour search."),
]
ids = [d[0] for d in docs]
texts = [d[1] for d in docs]
db.insert_batch(ids, model.encode(texts, normalize_embeddings=True).astype("f4"), documents=texts)
q = model.encode("How do I avoid memory bugs?", normalize_embeddings=True).astype("f4")
for r in db.search(q, top_k=2):
print(f" [{r['score']:.3f}] {r['id']} — {r['document']}")
Output:
[0.687] rust — Rust uses ownership and borrowing for memory safety.
[0.298] vector — A vector database stores embeddings for nearest-neighbour search.
➡️ Runnable end-to-end demo: examples/quickstart.py. RAG retriever loop: examples/rag.py. Migrate from Chroma: examples/migrate_from_chroma.py.
What makes TurboQuantDB different?
TurboQuantDB is built around a few deliberate design choices:
- Compression-first storage — embeddings are quantized on insert, so large corpora can fit on laptops, edge devices, and small VMs.
- Zero-training quantization — no PQ/IVF training phase, no sample corpus, no eval set required to start.
- Embedded-first deployment — the default path is
pip install tqdband in-process Python usage, not operating a separate service. - RAG-ready retrieval — document storage, MongoDB-style metadata filters, hybrid BM25+dense search, and LangChain/LlamaIndex integrations are built in.
- Durability without ceremony — writes go through a CRC-protected WAL, and crash recovery replays automatically on reopen.
- Server-capable when needed — an optional Axum HTTP server adds API keys, RBAC, quotas, async jobs, snapshots, restore, and Prometheus metrics.
Where TurboQuantDB fits
TurboQuantDB is not a managed vector database and not a distributed search cluster. It is built for developers who want compressed local vector search inside a Python or Rust application.
Use it for
- local / private RAG
- laptop-scale document search
- edge deployments
- compressed embedding stores
- bring-your-own-embedding workflows
- migration experiments from existing local vector stores
Use something else when you need
- multi-node clustering or replication
- managed cloud operations
- SQL joins and relational transactions
- enterprise search pipelines
- hosted embedding / reranking services
Benchmarks
All numbers below come from runs on a single Windows laptop; absolute values will differ on your hardware. Reproduction commands are in docs/BENCHMARKS.md. The three sub-tables below are distinct runs with different configs — read the "Config" line under each header carefully.
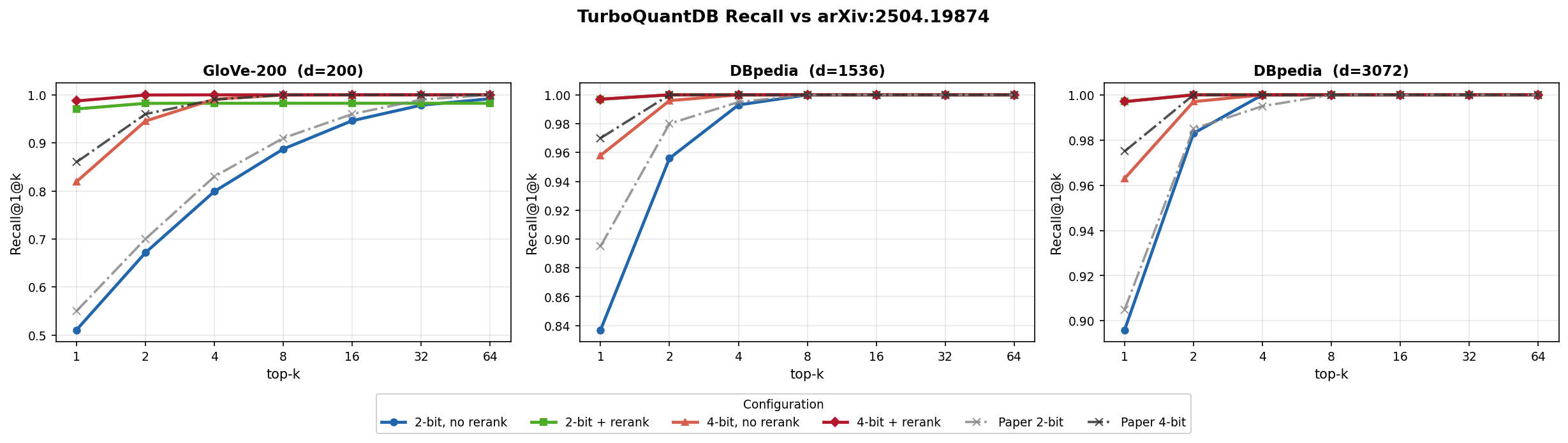
A. Paper-validation (n=100k, brute-force, fast_mode=True)
Config: dbpedia-1536, b=4, rerank=True, brute-force, quantizer_type=None (dense). Matches arXiv:2504.19874 Figure 5b's bit allocation.
| Metric | Value |
|---|---|
| Recall@1 | 99.7% |
| Recall@4 | 100.0% |
| Disk (incl. INT8 rerank vectors) | 230.4 MB |
Disk (codes only, rerank=False) |
83.6 MB |
| p50 latency (3-iter median) | 12.8 ms |
B. Rerank unlocks recall at low bit-rate (n=10k, brute-force, fast_mode=True)
Config: quantizer_type=None, brute-force, fast_mode=True. bits=2 + rerank=True matches bits=4 + rerank=True recall at ~10% less disk.
| Dataset | b=2, no rerank | b=4, no rerank | b=2 + rerank | b=4 + rerank |
|---|---|---|---|---|
| GloVe-200 (d=200) | 0.528 (1.8 MB) | 0.822 (2.3 MB) | 0.992 (3.8 MB) | 0.992 (4.2 MB) |
| arXiv-768 (d=768) | 0.426 (7.4 MB) | 0.696 (9.2 MB) | 0.978 (14.7 MB) | 0.978 (16.6 MB) |
| GIST-960 (d=960) | 0.294 (10.4 MB) | 0.566 (12.7 MB) | 0.974 (19.6 MB) | 0.974 (21.9 MB) |
C. Coverage across dimensions (n=10k, b=4, rerank=True, brute-force, fast_mode=True)
R@1 ≥ 0.87 across 9 benchmark datasets spanning d=65 to d=3072.
| Dataset | d | R@1 | Disk | p50 |
|---|---|---|---|---|
| lastfm-64 | 65 | 0.874 | 2.0 MB | 1.1 ms |
| deep-96 | 96 | 0.980 | 2.5 MB | 1.2 ms |
| glove-100 | 100 | 0.990 | 2.6 MB | 1.4 ms |
| glove-200 | 200 | 0.992 | 4.2 MB | 1.7 ms |
| nytimes-256 | 256 | 0.992 | 5.2 MB | 2.0 ms |
| arXiv-768 | 768 | 0.978 | 16.6 MB | 7.6 ms |
| GIST-960 | 960 | 0.974 | 21.9 MB | 7.3 ms |
| DBpedia-1536 | 1536 | 0.998 | 41.1 MB | 10.3 ms |
| DBpedia-3072 | 3072 | 1.000 | 117.0 MB | 46.8 ms |
Full tables (all 8 configs × 3 datasets) including ANN runs: docs/BENCHMARKS.md.
Config Advisor
Not sure whether to use b=2 or b=4, rerank, ANN, or fast mode? The interactive Config Advisor recommends settings from benchmark data for your embedding dimension and retrieval priorities, with adjustable weights for recall, compression, and speed.
👉 jyunming.github.io/TurboQuantDB/advisor.html

Migrate from Chroma or LanceDB
Already have a local vector store? TQDB can import an existing collection into a compressed TurboQuantDB database in one command — IDs, vectors, metadata, and document text are preserved.
pip install 'tqdb[migrate]'
python -m tqdb.migrate chroma ./chroma_db ./tqdb_db
python -m tqdb.migrate lancedb ./lancedb ./tqdb_db --table docs
Programmatic API + verification example: examples/migrate_from_chroma.py. Full migration guide: docs/MIGRATION.md.
Hybrid retrieval
Dense vectors are good at semantic similarity, but RAG queries often include exact terms: paper IDs, product names, function names, error messages, or code symbols. TQDB maintains a BM25 keyword index from the document field and can fuse sparse + dense results with Reciprocal Rank Fusion.
results = db.search(
query_vec,
top_k=10,
hybrid={"text": "error message WAL replay", "weight": 0.3, "rrf_k": 60},
)
Omit hybrid= for pure dense search — behaviour is unchanged. The BM25 index builds incrementally as documents are inserted; no separate train() or build_text_index() call required.
Framework integrations
pip install 'tqdb[langchain]'
pip install 'tqdb[llamaindex]'
TQDB ships native vector-store classes for LangChain v2 and LlamaIndex; both expose the same TurboQuantVectorStore class name in their respective namespaces. Use these for new RAG applications.
# LangChain v2
from tqdb.vectorstore import TurboQuantVectorStore as LCStore
store = LCStore.from_texts(texts, embedding=my_embedder, path="./db", dimension=384)
# LlamaIndex
from tqdb.llama_index import TurboQuantVectorStore as LIStore
vstore = LIStore.open("./db", dimension=1536)
For simple scripts and backward compatibility, the older tqdb.rag.TurboQuantRetriever wrapper remains available.
Detailed setup, pagination, hybrid wiring, and async patterns: LangChain integration | LlamaIndex integration.
Async API
For FastAPI / Starlette / async RAG services, AsyncDatabase exposes awaitable versions of every long-running operation. The Rust extension releases the GIL inside, so concurrent await db.search(...) calls run in real parallel.
import asyncio
from tqdb.aio import AsyncDatabase
async def main():
db = await AsyncDatabase.open("./db", dimension=1536, bits=4)
await db.insert("doc-1", vec, document="...")
hits = await db.search(query_vec, top_k=5)
await db.close()
asyncio.run(main())
Pass executor= to share a thread pool across multiple databases or to control its size.
Configurations for common goals
rerank=True stores raw INT8 vectors alongside compressed codes for exact second-pass rescoring. fast_mode=True (default) uses MSE-only quantization — optimal for d < 1536.
from tqdb import Database
# Best recall, any dimension — brute-force, default INT8 rerank
db = Database.open("./db", dimension=384, bits=4, rerank=True)
# DBpedia-1536 benchmark: R@1 ≈ 0.997 | ~231 MB disk
# arXiv-768 benchmark: R@1 ≈ 0.98 | ~116 MB disk
# GloVe-200 benchmark: R@1 ≈ 1.00 | ~30 MB disk
# Compression-first rerank — same recall ceiling at ~31% less disk (b=4 only)
db = Database.open("./db", dimension=1536, bits=4,
rerank=True, rerank_precision="residual_int4")
# DBpedia-1536 benchmark: R@1 ≈ 0.985 (vs 0.995 int8) | ~158 MB disk (vs 230 MB int8)
# Note: at b=2 the residual is larger; int8 still preferred for compression-first b=2 setups.
# Best recall, high-d (d ≥ 1536) — also enable QJL residuals
db = Database.open("./db", dimension=1536, bits=4, rerank=True, fast_mode=False)
# Minimum disk — MSE codes only (no rerank file at all)
db = Database.open("./db", dimension=384, bits=4)
# Low latency at N ≥ 100k — HNSW index
db = Database.open("./db", dimension=384, bits=4, rerank=True)
db.create_index()
results = db.search(query, top_k=10, _use_ann=True) # benchmarked p50 < 10 ms at d≥1536
# Tune rerank oversampling at query time (default 10×)
results = db.search(query, top_k=10, rerank_factor=20) # higher recall, higher latency
Full configuration guide: docs/CONFIGURATION.md.
Rerank precision picker (rerank_precision=)
| Value | Disk per vector at d=1536 | Recall vs int8 (b=4) | When to pick |
|---|---|---|---|
"int8" (default) |
1540 B | baseline (R@1 ≈ 0.995) | Best recall; pick when disk isn't the bottleneck |
"residual_int4" |
772 B | −0 to −1pp at b=4 | Compression-first: same effective recall at half the disk |
"f16" |
3076 B | matches int8 | Higher precision needed for non-normalized vectors |
"f32" |
6144 B | exact | Debugging or when storage is free |
"int4" |
772 B | strictly worse than rerank=False |
Deprecated — kept for backward compat with existing dbs only |
Server Mode
For team deployments, the optional Axum server adds REST access, API-key auth, RBAC, quotas, async index/compaction/snapshot jobs, snapshot/restore, and Prometheus metrics. The binary is bundled in the tqdb wheel — no extra install on Linux x86-64, macOS, or Windows.
pip install tqdb
tqdb-server # listens on 127.0.0.1:8080
In the default local setup, the server can bootstrap an auth_store.json with a development API key (dev-key) under tenant dev. Replace it before production use. Three minimal curl examples — create a collection, insert vectors, query:
AUTH='Authorization: ApiKey dev-key'
# 1. Create a 3-dim collection (dimension is fixed at creation; production uses 384/768/1536)
curl -X POST http://127.0.0.1:8080/v1/tenants/dev/databases/main/collections \
-H "$AUTH" -H 'Content-Type: application/json' \
-d '{"name": "docs", "dimension": 3, "bits": 4}'
# 2. Insert two vectors (length must equal the collection dimension)
curl -X POST http://127.0.0.1:8080/v1/tenants/dev/databases/main/collections/docs/add \
-H "$AUTH" -H 'Content-Type: application/json' \
-d '{
"ids": ["doc-1", "doc-2"],
"embeddings": [[0.10, 0.20, 0.30], [0.40, 0.50, 0.60]],
"metadatas": [{"source": "faq"}, {"source": "blog"}],
"documents": ["FAQ entry", "Blog post"]
}'
# 3. Query for the top 5 nearest neighbours
curl -X POST http://127.0.0.1:8080/v1/tenants/dev/databases/main/collections/docs/query \
-H "$AUTH" -H 'Content-Type: application/json' \
-d '{"query_embeddings": [[0.10, 0.20, 0.30]], "n_results": 5}'
Full endpoint reference, environment variables, and the Server Recovery Runbook: docs/SERVER_API.md.
Advanced features
- Two quantizer modes —
dense(default, best recall) andsrht(faster ingest at high d). Seedocs/QUANTIZER_MODES.md. - Optional ANN index — HNSW graph for low-latency search at n ≥ 100k; auto-fallback to brute-force when N is small.
- IVF coarse routing —
db.create_coarse_index(n_clusters=256)+nprobe=Nto score ~6% of the corpus at very large N. - MongoDB-style metadata filters —
$eq $ne $gt $gte $lt $lte $in $nin $exists $and $or $contains;$in / $nin / $oruse O(1) indexed fast-paths. - Per-query rerank tuning —
rerank_factor=exchanges recall and latency at query time, no rebuild required.
Preview: Multi-vector / ColBERT-style retrieval
MultiVectorStore lets each document hold N token vectors and scores queries with MaxSim (Σ_i max_j <q_i, d_j>), useful for late-interaction retrieval experiments.
This is currently a Python-layer wrapper over the single-vector engine; native engine-level support is planned for a future v0.9 release. The public API is designed to stay stable across that move. See docs/MULTI_VECTOR.md.
Python API at a glance
db = Database.open("./db", dimension=1536, bits=4, metric="ip", rerank=True)
db.insert("id", vector, metadata={"source": "docs"}, document="...")
hits = db.search(query, top_k=10, filter={"source": "docs"})
Supported operations:
insert/insert_batch/upsert/update/update_metadatadelete/delete_batch/get/get_many/list_all/list_ids/count/statssearch(brute /_use_ann=True/nprobe=N/hybrid={...}) and batchedquerycreate_index(HNSW),create_coarse_index(IVF)checkpoint(WAL flush + segment compaction)- container protocol:
len(db)/"id" in db
Full reference with every parameter and shape: docs/PYTHON_API.md.
Dataset Recovery (WAL)
TurboQuantDB replays wal.log automatically on reopen. For a local crash/power-loss recovery:
- Stop all writers to the DB directory.
- Make a copy of the DB folder (
manifest.json,live_codes.bin,live_ids.bin,wal.log, etc.). - Reopen the DB normally:
db = Database.open("./my_db")
- Validate state:
db.stats()["vector_count"]- sample
db.get(...)/db.search(...)
- Persist a clean post-recovery state:
db.checkpoint() # flush WAL + compact db.close()
If files are corrupted beyond WAL replay, restore from a snapshot/backup copy (server mode also supports snapshot/restore jobs; see docs/SERVER_API.md).
Troubleshooting
Database.open requires dimension — how do I find mine?
Embed one document and read the array shape:
vec = model.encode("hello") # sentence-transformers
print(vec.shape) # (384,) → dimension=384
# Or: model.get_sentence_embedding_dimension()
For OpenAI text-embedding-3-small it's 1536; text-embedding-3-large is 3072. The dimension is fixed for the lifetime of the DB — it's persisted in manifest.json.
ImportError: DLL load failed / symbol not found on macOS Apple Silicon
You likely have an Intel-built wheel installed. Reinstall with the right architecture:
pip uninstall tqdb && pip install --no-cache-dir tqdb
If you still see the error, check python -c "import platform; print(platform.machine())" — should report arm64 on Apple Silicon.
WAL replay is slow on reopen for a large DB
Replay is O(uncheckpointed-writes). Run db.checkpoint() before close to flush the WAL into a segment so subsequent reopens skip the replay. Schedule this after big batch ingests.
Search returns scores near 0 or in unexpected ranges Two common causes:
- Forgot to L2-normalize embeddings before insert — for
metric="ip"(default), most embedding models expect normalized inputs to make IP scores meaningful (<a, b> = cos(a, b)only for unit vectors). Usemodel.encode(..., normalize_embeddings=True)or normalize manually. - Mixed
metric=between insert and query — the metric is fixed atDatabase.opentime and cannot be changed without rebuilding.
Multi-query batch returned wrong scores under metric="cosine" (pre-v0.8.3)
Fixed in v0.8.3 — score_batch_brute was applying doc_norm on the cosine path. Upgrade to tqdb >= 0.8.3 or pass single queries through db.search(...) instead of db.query(...).
For more, see the closed GitHub issues and docs/CONFIGURATION.md.
Research Basis
This is an independent implementation of ideas from the TurboQuant paper. The algorithm itself was authored by the original researchers.
Zandieh, A., Daliri, M., Hadian, M., & Mirrokni, V. (2025). TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate. arXiv:2504.19874
@article{zandieh2025turboquant,
title={TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate},
author={Zandieh, Amir and Daliri, Majid and Hadian, Majid and Mirrokni, Vahab},
journal={arXiv preprint arXiv:2504.19874},
year={2025}
}
License
Apache License 2.0 — see LICENSE.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file tqdb-0.8.3.tar.gz.
File metadata
- Download URL: tqdb-0.8.3.tar.gz
- Upload date:
- Size: 1.3 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a01c54dd06fba5eb04990a411fcda60e9cba16281e12bc9871dd5c611c047e90
|
|
| MD5 |
fe76c33e80bdc23ef209ec8ae728bb44
|
|
| BLAKE2b-256 |
c02a4f13d0da910094fc9af1c63237223be1be9c51a3774050a3168160f6ee2e
|
File details
Details for the file tqdb-0.8.3-cp313-cp313-win_amd64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp313-cp313-win_amd64.whl
- Upload date:
- Size: 4.4 MB
- Tags: CPython 3.13, Windows x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
cd4239de492608651d7c8fa09dc719048b74595a3345ea50d8021158b7e25e83
|
|
| MD5 |
851a9c63d44ff85069aeba3b7f504f77
|
|
| BLAKE2b-256 |
99abbd52ca47b7fd7d1e05aff1a51a1bd235a8fb3def5e665312c568d3cb8c4c
|
File details
Details for the file tqdb-0.8.3-cp313-cp313-manylinux_2_28_aarch64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp313-cp313-manylinux_2_28_aarch64.whl
- Upload date:
- Size: 1.6 MB
- Tags: CPython 3.13, manylinux: glibc 2.28+ ARM64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
72026c9c65d8b9a08cc9ca1ad8f2b2cc48d882cdaaa6dd07d5df5ceb19390fb1
|
|
| MD5 |
976d85585c1cafe14a5a98d1c058ceff
|
|
| BLAKE2b-256 |
97718a5db496767689a51c98ab94aed91ac5854000515c84748bf7e7806dc4b6
|
File details
Details for the file tqdb-0.8.3-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp313-cp313-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 4.8 MB
- Tags: CPython 3.13, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c23ca2b0b44101c609e1ccb710485268473871aa4006e80138d38cbe043138c3
|
|
| MD5 |
939ef568f92f73123cb3e0f1f9738adb
|
|
| BLAKE2b-256 |
6ac20ef8b2275b3f80bddf54c15c521c67d009fd49b655f910fdbf1421101c7c
|
File details
Details for the file tqdb-0.8.3-cp313-cp313-macosx_10_12_x86_64.macosx_11_0_arm64.macosx_10_12_universal2.whl.
File metadata
- Download URL: tqdb-0.8.3-cp313-cp313-macosx_10_12_x86_64.macosx_11_0_arm64.macosx_10_12_universal2.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.13, macOS 10.12+ universal2 (ARM64, x86-64), macOS 10.12+ x86-64, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
39a915bde52b343581d50a03c358894f3fb47533e0d7ac419909b9cecc3d52bc
|
|
| MD5 |
dae2a4263ed34e5019d6770c2acff9db
|
|
| BLAKE2b-256 |
9c737e2791d02c9c75a3af8e773658806f81f8a6949b0790b5aba4fe55ed097c
|
File details
Details for the file tqdb-0.8.3-cp312-cp312-win_amd64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp312-cp312-win_amd64.whl
- Upload date:
- Size: 4.4 MB
- Tags: CPython 3.12, Windows x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
49383e960598b644be4926e366fcd38a62dc0288daa5e451f032f7750eca37ac
|
|
| MD5 |
a9f7932aae4515497746bb746aa25d3f
|
|
| BLAKE2b-256 |
f4a6be1954ae57db603e7bbcc0c7ee393ace619ee6a6ba6f7ee61500266aad4f
|
File details
Details for the file tqdb-0.8.3-cp312-cp312-manylinux_2_28_aarch64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp312-cp312-manylinux_2_28_aarch64.whl
- Upload date:
- Size: 1.6 MB
- Tags: CPython 3.12, manylinux: glibc 2.28+ ARM64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
88992904309008d8a92566c7b864b624fccd25a86f6c62bf90e19e8d99988de5
|
|
| MD5 |
e05d3436819fe64c3ea49eabe8801a26
|
|
| BLAKE2b-256 |
74a1d1977a0c353547316d9db5d68e4fed5f7ce59015bf47eebce8cf76a52640
|
File details
Details for the file tqdb-0.8.3-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 4.8 MB
- Tags: CPython 3.12, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a2d4f71bd21b37ff59b8b35ba8ba3204c320effb2f24726ba353b71ddf5e5695
|
|
| MD5 |
d74ff3471b227cf33d688172aa99af78
|
|
| BLAKE2b-256 |
ba05a9b5271c77f1abcb7f3c5389472e1c9f2b7812b5cbfffdfa1a8e8cd609d7
|
File details
Details for the file tqdb-0.8.3-cp312-cp312-macosx_10_12_x86_64.macosx_11_0_arm64.macosx_10_12_universal2.whl.
File metadata
- Download URL: tqdb-0.8.3-cp312-cp312-macosx_10_12_x86_64.macosx_11_0_arm64.macosx_10_12_universal2.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.12, macOS 10.12+ universal2 (ARM64, x86-64), macOS 10.12+ x86-64, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e2566ee0e2b88fafa29344693f8845e4cc4280ba605877f23a8121c08ac4d5ce
|
|
| MD5 |
501004b74619d28f1ab7819867d3847f
|
|
| BLAKE2b-256 |
eb2165e8bf358cd87a0ffdbc797a21f3cbc7105ee1440352f7ef9bb67a77b9bd
|
File details
Details for the file tqdb-0.8.3-cp311-cp311-win_amd64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp311-cp311-win_amd64.whl
- Upload date:
- Size: 4.4 MB
- Tags: CPython 3.11, Windows x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
d5e735c4d0ffbf74a8d8fec1f92d1903117cccc53152561797e9bc3b824feeb8
|
|
| MD5 |
a5ec9b1b3fab7105e1eef6b2eee75a53
|
|
| BLAKE2b-256 |
4e024a67576b95d968abe69aa43fb5197deecf040b9b929853e2487dba9e4222
|
File details
Details for the file tqdb-0.8.3-cp311-cp311-manylinux_2_28_aarch64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp311-cp311-manylinux_2_28_aarch64.whl
- Upload date:
- Size: 1.6 MB
- Tags: CPython 3.11, manylinux: glibc 2.28+ ARM64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
7c2e7b7f00a349839826aafb8ded69feb0b9afea583ce90be2b397afd9a74a85
|
|
| MD5 |
cbe45ee3afae27b29338a4e81216ab7e
|
|
| BLAKE2b-256 |
322a8c2c37b566794b48d131b45fa90545f3487b567a4d41cfb4b16141116b0c
|
File details
Details for the file tqdb-0.8.3-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 4.8 MB
- Tags: CPython 3.11, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
74e2becd6f1897f9e6aff264e5d6994232f2a66441bfe68d6ccd738ac09a1c6c
|
|
| MD5 |
36060a97836f3985394bb431b7ba17e9
|
|
| BLAKE2b-256 |
641557438d979eb8fe878c81a280b062f817bc227ca1aa0f2e4a5ac18661a5fd
|
File details
Details for the file tqdb-0.8.3-cp311-cp311-macosx_10_12_x86_64.macosx_11_0_arm64.macosx_10_12_universal2.whl.
File metadata
- Download URL: tqdb-0.8.3-cp311-cp311-macosx_10_12_x86_64.macosx_11_0_arm64.macosx_10_12_universal2.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.11, macOS 10.12+ universal2 (ARM64, x86-64), macOS 10.12+ x86-64, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ba5ac0368003ad8de4fca62168e1fb17578006c51a0020fd654d8baf331a0d14
|
|
| MD5 |
1af1a23870bb82cf949f32a520fbeba9
|
|
| BLAKE2b-256 |
07862ee1e1519135ac183921348f3aa28f1e4479ef634b1c882e4b4265001e3e
|
File details
Details for the file tqdb-0.8.3-cp310-cp310-win_amd64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp310-cp310-win_amd64.whl
- Upload date:
- Size: 4.4 MB
- Tags: CPython 3.10, Windows x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
fa7c358b4c57994f2a9acfe242ca776f5b6301155f1b9563d09cb479b38929fe
|
|
| MD5 |
6ef340807a069f80aba8e8b72f620fe4
|
|
| BLAKE2b-256 |
e402e9730c5a63753ec7e7219181002a5627c9a356fc773de855b6943b84bf41
|
File details
Details for the file tqdb-0.8.3-cp310-cp310-manylinux_2_28_aarch64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp310-cp310-manylinux_2_28_aarch64.whl
- Upload date:
- Size: 1.6 MB
- Tags: CPython 3.10, manylinux: glibc 2.28+ ARM64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
b4442e801d512fcbd70c5f41f13e67619a269893ddee9d62ee57f7ea706e1fde
|
|
| MD5 |
d727836439fd7f505055b6bba39f9943
|
|
| BLAKE2b-256 |
789f5b721f26ce029807f8f5784a0e4c38626ac6825b8d5af0b3b729eed68be6
|
File details
Details for the file tqdb-0.8.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl.
File metadata
- Download URL: tqdb-0.8.3-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
- Upload date:
- Size: 4.8 MB
- Tags: CPython 3.10, manylinux: glibc 2.17+ x86-64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e62dffe8f528157ee679a723beceb78349137d449a844844d45cbd9b06d53ec6
|
|
| MD5 |
28ff67c3731c06ba39e39cabd3d39345
|
|
| BLAKE2b-256 |
76e02b0232735b8be11cfeedb62138beb4bd8ed40f668f6e34a64f1009b65c5e
|
File details
Details for the file tqdb-0.8.3-cp310-cp310-macosx_10_12_x86_64.macosx_11_0_arm64.macosx_10_12_universal2.whl.
File metadata
- Download URL: tqdb-0.8.3-cp310-cp310-macosx_10_12_x86_64.macosx_11_0_arm64.macosx_10_12_universal2.whl
- Upload date:
- Size: 5.8 MB
- Tags: CPython 3.10, macOS 10.12+ universal2 (ARM64, x86-64), macOS 10.12+ x86-64, macOS 11.0+ ARM64
- Uploaded using Trusted Publishing? Yes
- Uploaded via: maturin/1.13.1
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
593179b8ddee78aa11e7ae8b83eea0947367572f04f37527292f285c4aa8da30
|
|
| MD5 |
a632b1f366be651b4cd493ced2d972df
|
|
| BLAKE2b-256 |
d22c490d2eabe79319f62217537debce21941238860cf6b8cf3ad8edc5729e5b
|







