xleda is a Microsoft Excel powered EDA tool for Python data
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description






A Microsoft Excel powered EDA tool for Python data.
-
Produces Microsoft Excel workbooks from pandas dataframes that are highly optimized to both perform and document the activity of Exploratory Data Analysis.
-
Visually explore your data, navigate with your keyboard, take field or record notes, create lists of fields/records for editing, round-trip your edits/analysis back into python, share your workbook with other contributors.
-
There are some amazing EDA tools for Python. You shouldn't have to start from scratch to include Microsoft Excel among them.
-
xleda provides a good start to a robust EDA.
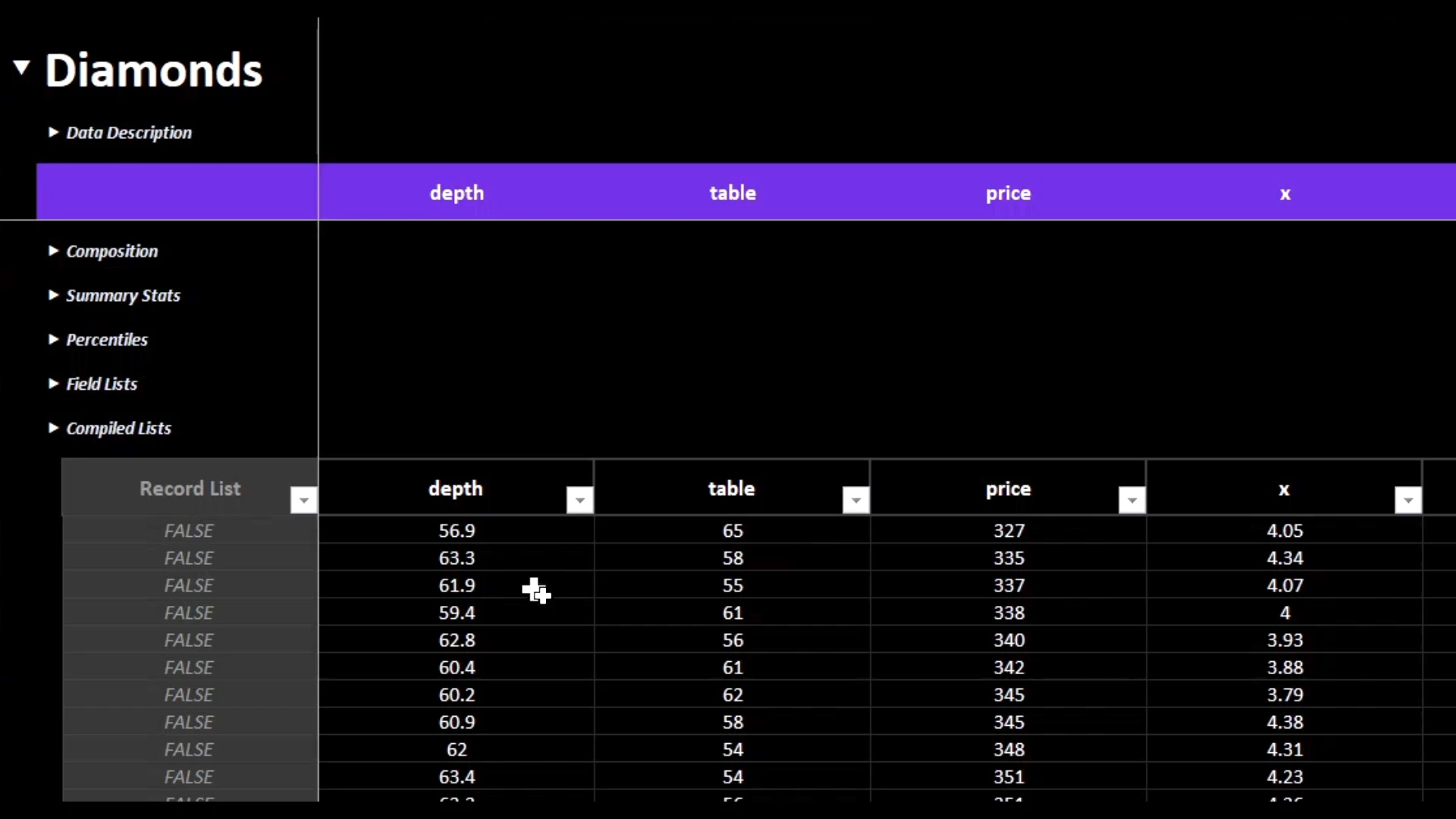
An xleda workbook made with diamond data.
Requirements/Compatibility
-
Requires the full version of Microsoft Excel to create workbooks.
-
Once created, xleda workbooks should work in anything that reads Microsoft Excel workbooks.
-
It has been developed and tested on Windows.
-
It should also work on MacOS though this has not yet been tested and is currently unsupported.
Installation
-
Install with
uv add xleda
or
pip install xleda
Quick Start
-
Use wb() to quickly create an xleda workbook of a dataframe.
-
See the configuration section below for how to name the workbook, set a theme, add additional dataframes/plots etc.
from xleda import wb import seaborn as sns # < your dataframe goes here > df = sns.load_dataset("titanic") # Creates xleda.xlsm in the current directory wb(df)
xleda Components
Field Metadata
Included Field Metadata
Overview
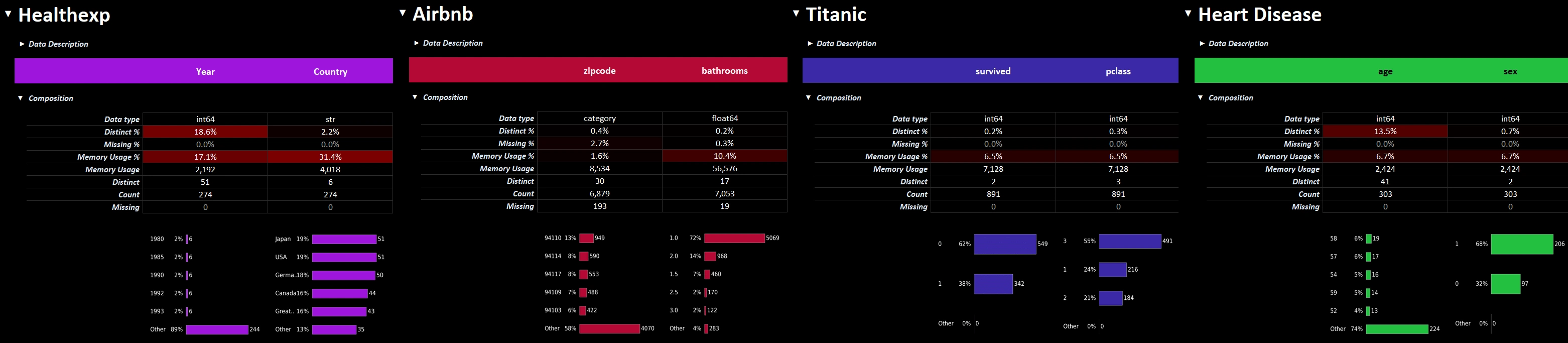
- The
Overviewworksheet rotates the field metadata 90 degrees so that you can sort/filter fields by their name, metadata, or your notes/definitions/etc.

Sorting fields from MLB data by memory usage.
Per Field Charts
Two charts are produced for each column in your dataframe.
- A composition table showing the top 5 values per column and their percentages.
- A histogram/KDE showing min/max, distribution, and mean
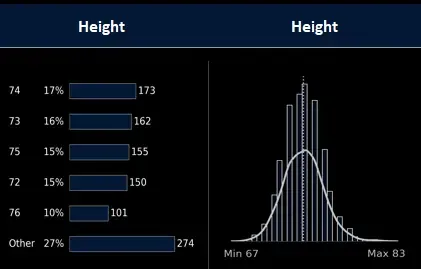
Default charts for MLB player height.
Source Data Table
-
A copy of your source data is included as an Excel table so you can visually inspect it, sort/filter it, etc.
-
Includes a way to make lists of individual records.
-
Includes a
HasBlankfield for isolating incomplete records. -
Includes a way to round-trip your source data back into Python so that you can use Excel to replace values, delete records/columns/etc.
-
More on how to use these features below.

Source Data Table for MLB player data.
Pivot
- A bare-bones pivot table ready to be configured.
- Defaults to include:
- The first 10 fields of the source data
- Measures to to identify blanks/dataset composition.

Bare-bones pivot table for Titanic survivor data.
Debug
- A worksheet that includes details on configuration, environment, and how the time spent to produce an xleda workbook was allocated.
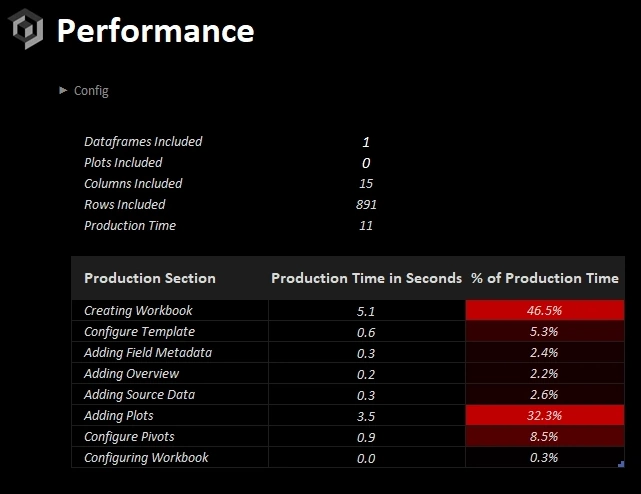
Debug worksheet for troubleshooting.
xleda.wb() Configuration
input_df | Dataframe | Mandatory
- A pandas dataframe of any size
name | str | Optional
-
Name of the dataset/file name of the created workbook.
-
Punctuation will be removed to prevent issues with file name/workbook object names.
-
Defaults to
xleda
theme_color | str | Optional
-
Sets the primary color of the charts and the color of the headings in the workbook to a hex color of your choice.
-
theme_color="random"sets a random theme -
Defaults to a neutral color
theme_color affects the workbooks and default charts.
add_plots | dict | Optional
-
add_plots={'plotname': Figure, ...}will add additional worksheets with plots of your choosing. -
No styling/sizing of additional plots is performed by xleda.
-
The example below adds two additional plot worksheets, one from seaborn and another from missingno. The workbook can be found here.
from xleda import wb import matplotlib.pyplot as plt import seaborn as sns import missingno as msno # < your dataframe goes here > df = penguins = sns.load_dataset("penguins") # Style the additional plots | optional plt.style.use("dark_background") # Create additional plots pair_plots = sns.pairplot(df, hue="species").figure null_matrix = msno.matrix(df).get_figure() # Resize the null matrix | optional null_matrix.set_size_inches(9.35, 4.5) # Creates an xleda workbook named Penguins.xlsm with two extra plot sheets wb(input_df=df, name="Penguins", theme_color="#4C4C4C", add_plots={'Pair Plots': pair_plots, 'Null Matrix': null_matrix})
add_dfs | dict | Optional
-
add_dfs={'dataset_name': dataset_df, ...}will add Field Analysis/Overview worksheets for each additional dataframe provided into the same workbook. -
Useful for grouping related data together.
import seaborn as sns import pandas as pd from xleda import wb og_penguins = pd.read_csv("https://raw.githubusercontent.com/allisonhorst/palmerpenguins/refs/heads/main/inst/extdata/penguins_raw.csv") penguins = sns.load_dataset('penguins') seaice = sns.load_dataset('seaice') # Creates "OG Penguins.xlsm" in the current directory with worksheets included for each of the OG Penguins/Sea Ice/Seaborn Penguins dataframes. wb(input_df=og_penguins, name="OG Penguins", add_dfs={'Sea Ice': seaice, 'Seaborn Penguins': penguins})
wb_path | Path or string | Optional
-
Uses a string or Pathlib path of a directory or file
-
Sets the target folder or workbook name of an xleda workbook.
-
If a directory is provided, the workbook will be created in that directory.
-
If a file name ending in ".xlsm" or ".xlsx" is provided:
- It will either create that file or export from that file depending on whether export=True is also selected.
- It will either create that file or export from that file depending on whether export=True is also selected.
-
Defaults to current working directory
from xleda import wb from pathlib import Path # Creates "c:\my_target_folder\Penguins.xlsm" wb(input_df=df, name="Penguins", wb_path=Path(r"c:\my_target_folder")) # Creates "c:\my_awesome_workbook.xlsx" wb(input_df=df, name="Penguins", wb_path=r"c:\my_awesome_workbook.xlsx")
overwrite | bool | Optional
-
Whether to overwrite existing workbooks of the same name.
-
Existing workbooks are sent to Trash/Recycle Bin
-
Defaults to False
large_report | bool | Optional
-
Raises the default dataframe size limits of 25,000 rows/50 columns to Excel's limits of 1,000,000 rows and 16,000 columns.
-
The closer your are to this limit, the more RAM and patience you'll need to produce a workbook.
-
See additional details in the performance section below.
-
Defaults to False
no_vba | bool | Optional
-
Creates the workbook as an xlsx file without VBA.
-
Defaults to False
from xleda import wb import seaborn as sns df = sns.load_dataset('penguins') # Creates "Penguins.xlsx" in the current directory wb(input_df=df, name="Penguins", no_vba=True)
open_wb | bool | Optional
-
Opens the workbook after creating.
-
Setting this to
Falseis useful when creating multiple workbooks -
Defaults to True.
export | bool | Optional
-
Performs an export from an xleda workbook instead of creating one.
-
Replaces the
export_analysismethod. -
See details below.
-
Defaults to False.
Usage Notes
Performance
-
On an average machine, xleda creates workbooks for most data sets less than 20 seconds.
-
Performance is largely dependent on how powerful of a machine you have and how large/complex your dataframes are.
-
The
debugworksheet will show you how the time spent to produce your workbook was allocated. -
There is a detailed output provided when creating an xleda workbook that does a pretty good job of letting you know what it's doing.
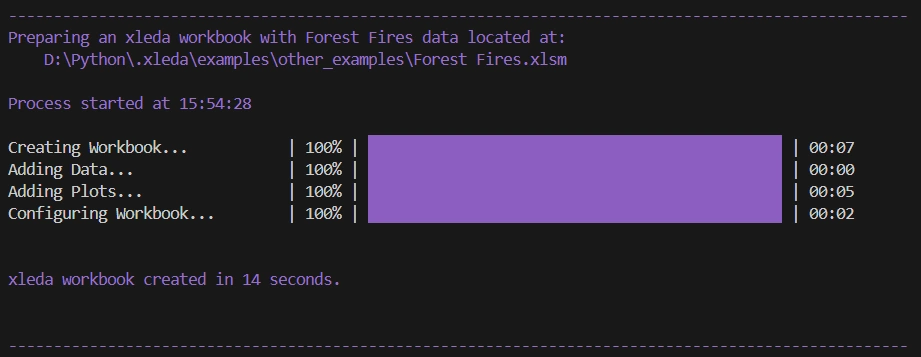
Console output of a Planets workbook
Limits with Large Data Sets
-
To ensure workbooks are created quickly, defaults limit data to the first 50 columns and a random sample of 25,000 records.
-
You can optionally override this to Excel's limits (see
large_report=Trueabove) -
You'll see a warning banner if you hit a limit.

-
One of the more complex data sets tested was a 600 column/1,200 row dataframe.
-
It took ~5 minutes to create, in part because nearly all values are unique for all 600 columns.
-
It is still snappy to use even though it has 1,200 charts on a single worksheet.
-
That example is here.
-
Field/Record Lists
-
The
Field Listssection helps you create lists of the fields in your data.- e.g. lists of fields to rename, delete, standard scale, encode, impute, investigate, etc.
-
Anything not marked as
Falsewill be included in each list. -
You can rename any list to
Anything You Wantand the list will be renamed toanything_you_want. -
The
Record Listfield added to your source data works the same way except it creates a list of records instead of a list of fields. More on that below. -
The Compiled Lists section formats your lists as python lists for easy copy/pasting.
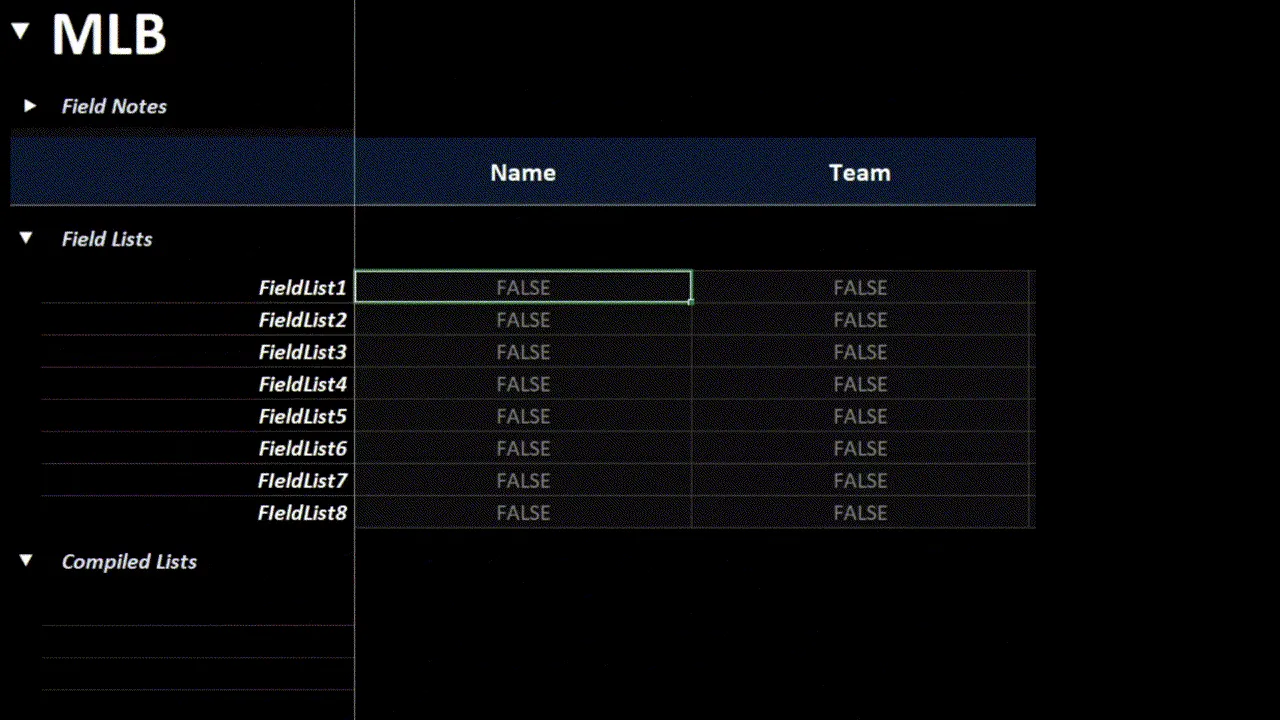
Easily create lists of fields in your data.
Columns Added to Source Data
-
Although the source data is unchanged before it goes into Excel, there are some columns added to support an EDA workflow.
-
HasBlank: If any field in a record has a missing value, this will show 1 otherwise 0 -
Record Hash: Uses a built-in pandas feature hash_pandas_object to uniquely identify records. If two records share all column values they also share aRecord Hash. -
Record List: Used to create a list ofRecord Hashvalues. LikeField Listsabove, anything not marked false gets added to a list. -
index: This is a copy of the index from the provided dataframe as a column.
-
Accessing Metadata in Python
Default Metadata
-
Metadata from all
xleda.wb()objects is collected into a list of dictionary objects, one for each dataframe, accessible throughxleda.wb().export_dicts# Creates "Titanic.xlsm" and exports the metadata dictionaries export_dicts = wb(input_df=df, name="Titanic").export_dicts # Returns the field metadata df from the primary dataframe export_dicts[0]['field_metadata']
-
The following metadata is available without using
export=True-
field_metadata: A basic metadata dataframe, combining information from pandas info/describe/quantile. -
overview_metadata: A transposed copy of the field_metadata. -
source_data: A copy of your unaltered source data that includesRecord Hash/Record List/HasBlank/indexcolumns.
-
Expanded Metadata
-
Using
xleda.wb(export=True)reads an xleda workbook instead of creating one. -
It expands the available metadata within
xleda.wb().export_dictsto include the following for each provided dataframe:-
description: Dataframe description if you've added one -
definitions: Any field definitions you've added. -
notes: Any field notes you've added -
lists: Any lists showing in the compiled lists section -
altered_source_data: Reads the Source Data table named from the workbook and will include any manual edits you've made such as removing records, renaming fields, replacing values, etc. **** Note that data types will likely change in the round-trip translation.
-
Completed Example
-
The xleda workbook pictured here is used in for the export code example below .
-
It can be found here..
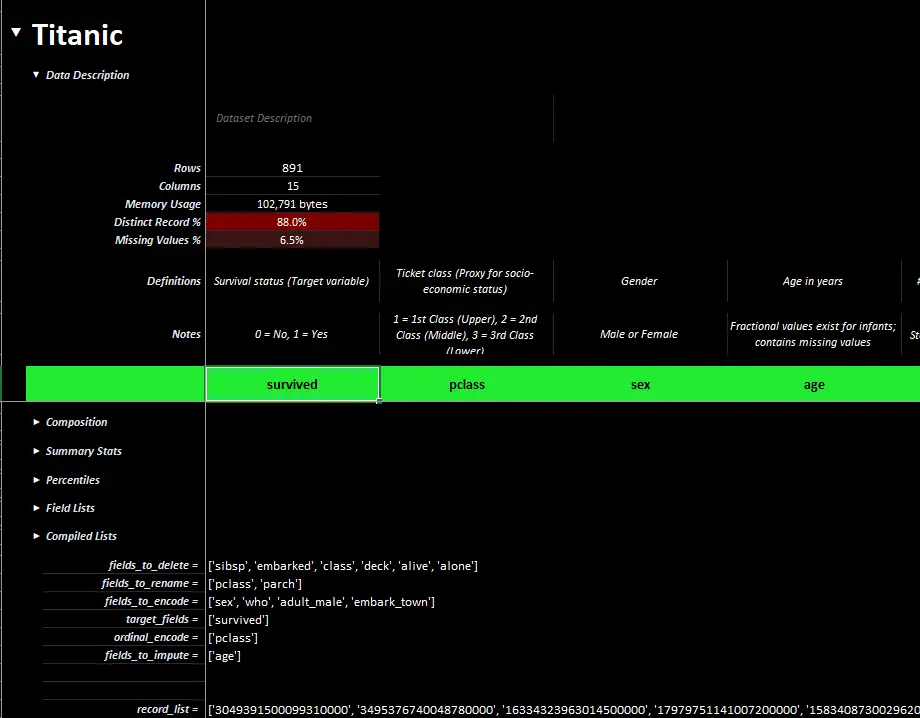
A completed xleda workbook of Titanic passenger showing definitions, notes, lists, etc.
Example Export Dictionary
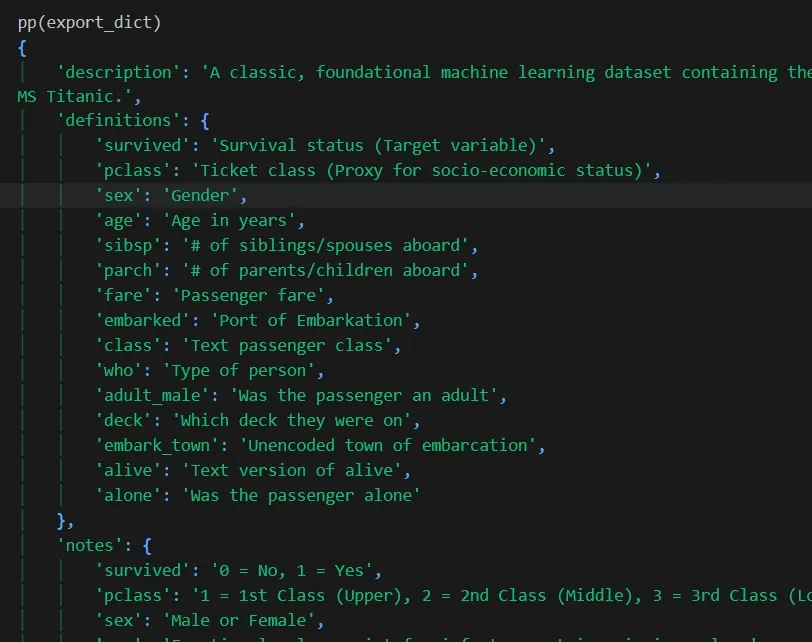
An example export dictionary from a completed field analysis on Titanic passenger data.
Example Export Code
-
This example exports everything from an xleda workbook named "Titanic Completed.xlsm" in the current directory.
-
Either download this one or create your own.
from xleda import wb # Performs a full export from "Titanic Completed.xlsm" export_dicts = wb(input_df=df, path="Titanic Completed.xlsm", export=True).export_dicts # Returns dict_keys(['description', 'definitions', 'notes', # 'lists', 'field_metadata', 'overview_metadata', 'source_data', # 'altered_source_data']) print(export_dicts[0].keys())
VBA Code
-
If you can't or don't want to enable VBA, you may want to use
no_vba=Truewhich creates an xlsx file that contains no VBA. -
The code that is there does two optional things.
- Makes the sections expand/collapse when you select them as pictured above.
- You can use row groupings to navigate without VBA as pictured below.
- You can use row groupings to navigate without VBA as pictured below.
- Adds two UDFs, PythonList and PythonDict, that format cell values as lists/dicts.
- Makes the sections expand/collapse when you select them as pictured above.
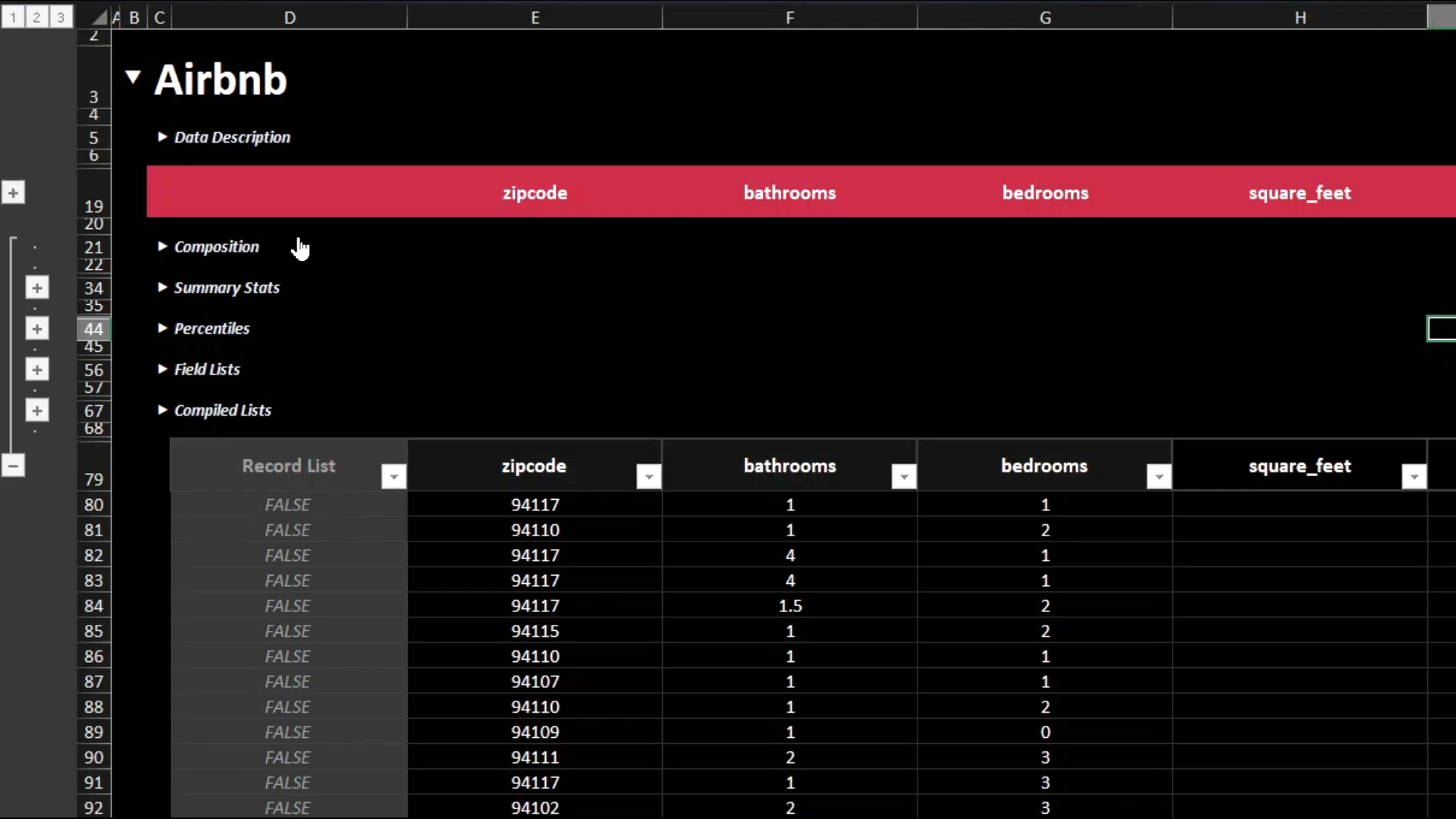
Use row groupings to navigate if you can't use VBA.
Extensibility
-
xleda is only meant to give a good start to EDA.
-
If it accomplishes one thing it will be to give you a way to quickly get data into Excel so that you can see and make sense of it...without making you do everything from scratch.
-
Where you go from there is up to you.
-
Because it's an ordinary workbook, you can use any tool that works with Microsoft Excel workbooks to do more.
-
xlwings, is recommended if you do.
Troubleshooting
-
if xleda is slow:
- Try reducing the amount of data you're sending to it, and let it finish.
- After production, refer to the debug worksheet for how the time to produce your xleda workbook is being spent so that you can reduce your dataframe size more strategically.
-
If you receive the "Error: The workbook cannot be overwritten while open!" and don't see any open workbooks:
-
If you can't get xleda to run at all and are using Windows with a full Office Installation:
- Try getting the following script to run using xlwings (not xlwings-lite).
- All it does is open Excel and create a new workbook.
- You should be able to pip install xlwings and run the script successfully.
- If that doesn't work, see their installation instructions for details on how to get it set up.
- Be aware that xlwings has a ton of functionality and that for xleda to work, it only requires communication with Excel and not the addin, xlwings lite, udfs, or many of the other things xlwings can potentially do.
- If you can get the script to run successfully, xleda has a good chance of working reliably.
import xlwings as xw app = xw.App()
Built With
- This was primarily built with Python, xlwings, Pandas, and of course, Microsoft Excel
Roadmap
- Add a barebones pivot that is ready to configure
- Make xleda even more accessible by simplifying the API and making it easier to remember.
- Create a way to quickly view dataframe data that is editable, shareable, and presentation ready.
- Add a way to include extra plots for a dataset.
- Add a way to include extra supporting dataframe worksheets.
- Add a way to use on desktop files e.g. by right-clicking csv/parquet files/other tabular data files.
- Add a way to include multiple xleda analyses in a single workbook.
- Test on MacOS
- Your idea here.
Changelog
Version 0.8.186 - Create xleda workbooks of multiple dataframes, module refactoring into classes, logging, general polish
Implemented add_dfs
- Adds Field Analysis/Overview reports for each additional dataframe.
- Pivot is only provided for primary dataframe.
- Useful for supporting or related data.
- Worksheet names now include the dataframe name.
- Each dataframe's worksheet set gets a greyscale gradient so they can be visually distinguished among worksheet tabs.
Export adjustments
- Implemented an ExportDict class to add structure to export functionalities
- To support the additional dataframes from
add_dfsfunctionality,export_dicthas been renamed toexport_dictsand now provides a list of ExportDict objects, one for each provided dataframe. - ExportDict allows access to metadata through both dot notation and
dict[key]. - Reinforced handling of modified export workbook.
- If a workbook is found but that the expected worksheets aren't found, i.e. they've been deleted or renamed, it will export what it can and return a list of what wasn't found.
- If a workbook is found but that the expected worksheets aren't found, i.e. they've been deleted or renamed, it will export what it can and return a list of what wasn't found.
Reinforced wb_path/name handling
wb_pathnow accepts strings, or pathlib Path objects.- Also accepts full/partial paths with/without correct extensions
- Providing a path ending in
xlsxor.xlsmwill setno_vbatoTrue/Falserespectively - Illegal characters are now properly stripped from provided names before using in file/object names
Added production logging/debug worksheet
- The
debugworksheet details how the time it took to produce the workbook was allocated on both field and workbook levels. - Also includes configuration and system details
Other Updates
- Tests, examples, readme updated to reflect new functionality
- In the template, the
Field Notessection of theField Analysisworksheet was merged intoData Descriptionsection. - Refactored the primary module into more specialized classes.
- Configuration/environment/plotting/logging/theme all have their own classes
- Also implemented new Blueprint class
- Workbooks are now constructed from config object that includes a list of Blueprints
- Each provided dataframe gets it's own Blueprint
- Improved handling of datatypes that are unsupported in Excel/xlwings such as TimeDelta
- Reinforced system configuration checks with more informative offramps for:
- Unsupported system configurations
- Situations where necessary template components have been removed/renamed.
- Adjusted Github Action script to remove all but last changelog and convert the details/summary to standard markdown.
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file xleda-0.8.190.tar.gz.
File metadata
- Download URL: xleda-0.8.190.tar.gz
- Upload date:
- Size: 104.6 kB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: uv/0.11.19 {"installer":{"name":"uv","version":"0.11.19","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
a758d0d0e5dc653b34ccd68661741ab3c0632cd9015ba0c8bb6623593dbdf30f
|
|
| MD5 |
ccd0f09d24e331140dd91f5df5607d8f
|
|
| BLAKE2b-256 |
340929d3d184937a7c2586ee4314cc7931699544de9ecc64187f19f3c8ba96f4
|
File details
Details for the file xleda-0.8.190-py3-none-any.whl.
File metadata
- Download URL: xleda-0.8.190-py3-none-any.whl
- Upload date:
- Size: 104.0 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: uv/0.11.19 {"installer":{"name":"uv","version":"0.11.19","subcommand":["publish"]},"python":null,"implementation":{"name":null,"version":null},"distro":{"name":"Ubuntu","version":"24.04","id":"noble","libc":null},"system":{"name":null,"release":null},"cpu":null,"openssl_version":null,"setuptools_version":null,"rustc_version":null,"ci":true}
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
45cb1cbe87e709258f7bdd6e1104141ae1c29958342033ecc29ba61ae9c4b3b3
|
|
| MD5 |
fc740638b04c9090a6b3c5157ca51261
|
|
| BLAKE2b-256 |
44609c7755f025973802027024d888f08e884fba1cafe9ed6b3e5a8dc3085dd0
|







