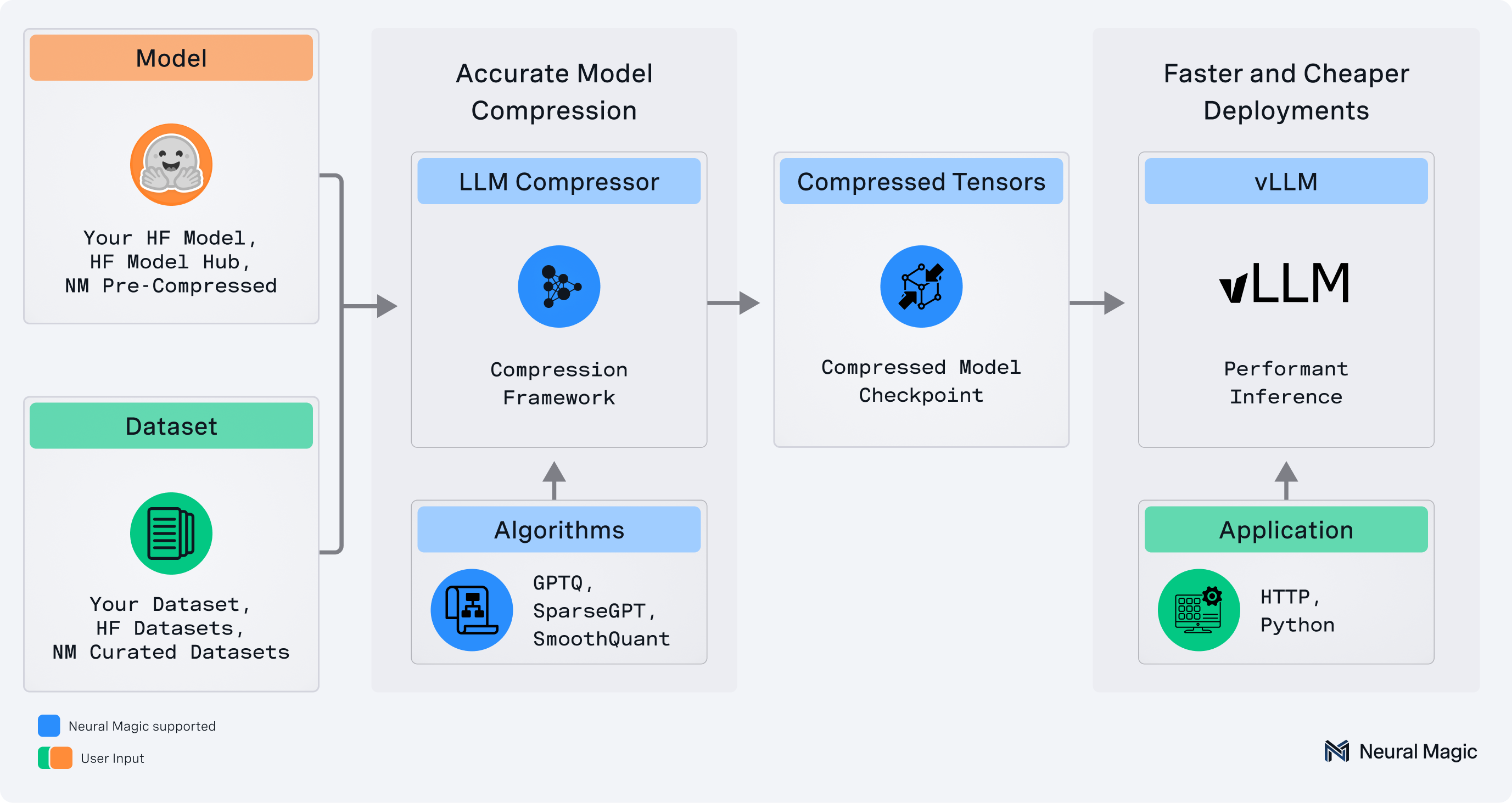
A library for compressing large language models utilizing the latest techniques and research in the field for both training aware and post training techniques. The library is designed to be flexible and easy to use on top of PyTorch and HuggingFace Transformers, allowing for quick experimentation.

Project description
 LLM Compressor
LLM Compressor


llmcompressor is an easy-to-use library for optimizing models for deployment with vLLM, including:
- Comprehensive set of quantization algorithms and transforms for weight, activation, KV Cache, and attention quantization
- Seamless integration with Hugging Face models and repositories
- Models saved in the
compressed-tensorsformat, compatible with vLLM - DDP and disk offloading support for compressing very large models
✨ Read the announcement blog here! ✨
📊 Help us improve by taking our 1-minute user survey
💬 Join us on the vLLM Community Slack and share your questions, thoughts, or ideas in:
#sig-quantization#llm-compressor
🚀 What's New!
Big updates have landed in LLM Compressor! To get a more in-depth look, check out the LLM Compressor overview.
Some of the exciting new features include:
- Nemotron 3 Ultra Quantized Checkpoints: Quantized FP8 and Int4 checkpoints for Nemotron 3 Ultra have been created by the Red Hat team and posted to the HF Hub using a model_free_ptq example. Consider using:
- DeepSeek-V4-Flash and Kimi-K2.6 Quantized Checkpoints: Quantized checkpoints for DeepSeek-V4-Flash and Kimi-K2.6 have been generated by the Red Hat team and posted to the HF hub. Consider using:
- DeepSeek-V4-Flash-NVFP4-FP8 — 163B DeepSeek-V4-Flash quantized to NVFP4 weights with FP8 KV cache
- Kimi-K2.6-NVFP4 — Kimi-K2.6 quantized to NVFP4 (weights and activations), targeting NVIDIA Blackwell GPUs
- Kimi-K2.6-FP8-BLOCK — 1T parameter Kimi-K2.6 quantized to FP8 block format (weights and activations), compatible with DeepGEMM FP8 kernels
- Qwen3.6 NVFP4 Generated Checkpoint: An NVFP4 quantized checkpoint has been generated by the RedHat team and posted to the HF hub. Qwen3.6 follows the same architecture as Qwen3.5, so existing LLM Compressor examples can be used for this model by swapping out the target model string.
- Gemma4 Support: Gemma 4 can now be quantized using LLM Compressor. Support is available through main and will require updating to transformers 5.5 (
uv pip install transformers>=5.5). For models quantized and published by the RedHat team, consider using:
Supported Precisions and Types
- Activation Quantization: W8A8 (int8 and fp8), W4AFP8, Microscale (NVFP4, MXFP4, MXFP8)
- Mixed Precision: W4A16, W8A16, MXFP8A16, MXFP4A16, NVFP4A16
- Attention and KV Cache Quantization: FP8, NVFP4
Supported Algorithms
- Simple PTQ
- GPTQ
- AWQ
- SmoothQuant
- AutoRound
- Rotation-based (SpinQuant, QuIP)
Quantizing your model, step-by-step
Please refer to our step-by-step compression guide for detailed information about selecting quantization schemes, algorithms, and their use cases.
Additional information about LLM Compressor functionality is also available in our User Guides
Installation
pip install llmcompressor
Get Started
End-to-End Examples
Applying quantization with llmcompressor:
Weight and Activation Quantization
- Activation quantization to
int8 - Activation quantization to
fp8 - Activation quantization to MXFP8
- Activation quantization to
fp4(NVFP4) - Activation quantization to
fp4(MXFP4) - Activation quantization to
fp4using AutoRound - Activation quantization to
fp8and weight quantization toint4
Weight Only Quantization
- Weight only quantization to
fp4(NVFP4 format) - Weight only quantization to
fp4(MXFP4 format) - Weight only quantization to
int4using GPTQ - Weight only quantization to
int4using AWQ - Weight only quantization to
int4using AutoRound
Attention and KV Cache Quantization
- KV Cache quantization to
fp8 - KV Cache quantization to
fp8using per-head - Attention quantization to
fp8 - Attention quantization to
NVFP4with SpinQuant (experimental)
Architecture-Specific Quantization
Non-Uniform Quantization
Big Model Quantization Support
Model-Free Definition Quantization
DDP Quantization
Quick Tour
Let's quantize Qwen3-30B-A3B with FP8 weights and activations using the Round-to-Nearest algorithm.
Note that the model can be swapped for a local or remote HF-compatible checkpoint and the recipe may be changed to target different quantization algorithms or formats.
Apply Quantization
Quantization is applied by selecting an algorithm and calling the oneshot API.
from compressed_tensors.offload import dispatch_model
from transformers import AutoModelForCausalLM, AutoTokenizer
from llmcompressor import oneshot
from llmcompressor.modifiers.quantization import QuantizationModifier
MODEL_ID = "Qwen/Qwen3-30B-A3B"
# Load model.
model = AutoModelForCausalLM.from_pretrained(MODEL_ID)
tokenizer = AutoTokenizer.from_pretrained(MODEL_ID)
# Configure the quantization algorithm and scheme.
# In this case, we:
# * quantize the weights to FP8 using RTN with block_size 128
# * quantize the activations dynamically to FP8 during inference
recipe = QuantizationModifier(
targets="Linear",
scheme="FP8_BLOCK",
ignore=["lm_head", "re:.*mlp.gate$"],
)
# Apply quantization.
oneshot(model=model, recipe=recipe)
# Confirm generations of the quantized model look sane.
print("========== SAMPLE GENERATION ==============")
dispatch_model(model)
input_ids = tokenizer("Hello my name is", return_tensors="pt").input_ids.to(
model.device
)
output = model.generate(input_ids, max_new_tokens=20)
print(tokenizer.decode(output[0]))
print("==========================================")
# Save to disk in compressed-tensors format.
SAVE_DIR = MODEL_ID.split("/")[1] + "-FP8-BLOCK"
model.save_pretrained(SAVE_DIR)
tokenizer.save_pretrained(SAVE_DIR)
Inference with vLLM
The checkpoints created by llmcompressor can be loaded and run in vllm:
Install:
pip install vllm
Run:
from vllm import LLM
model = LLM("Qwen/Qwen3-30B-A3B-FP8-BLOCK")
output = model.generate("My name is")
Questions / Contribution
- If you have any questions or requests open an issue and we will add an example or documentation.
- We appreciate contributions to the code, examples, integrations, and documentation as well as bug reports and feature requests! Learn how here.
Citation
If you find LLM Compressor useful in your research or projects, please consider citing it:
@software{llmcompressor2024,
title={{LLM Compressor}},
author={Red Hat AI and vLLM Project},
year={2024},
month={8},
url={https://github.com/vllm-project/llm-compressor},
}
!!! warning Sparse compression (24 sparsity) is no longer supported by LLM Compressor due to lack of hardware support and usage
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file llmcompressor-0.12.0.tar.gz.
File metadata
- Download URL: llmcompressor-0.12.0.tar.gz
- Upload date:
- Size: 2.4 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
2aa2afaa56f12b3f3e69ad9bf5e22903adbfe9e94020884c97b0d2fbac1bedef
|
|
| MD5 |
f0218887dab1453cd70b9b7f1c22b53a
|
|
| BLAKE2b-256 |
940c704137314232a35ba4fc6d4d9aaeb4721bfeeb6a51b8325ef3838151e7ec
|
Provenance
The following attestation bundles were made for llmcompressor-0.12.0.tar.gz:
Publisher:
upload.yml on neuralmagic/llm-compressor-testing
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
llmcompressor-0.12.0.tar.gz -
Subject digest:
2aa2afaa56f12b3f3e69ad9bf5e22903adbfe9e94020884c97b0d2fbac1bedef - Sigstore transparency entry: 1824835514
- Sigstore integration time:
-
Permalink:
neuralmagic/llm-compressor-testing@88cf7c90f4b27035cf6f6a9ba5316a14252614e1 -
Branch / Tag:
refs/tags/0.12.0 - Owner: https://github.com/neuralmagic
-
Access:
private
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
upload.yml@88cf7c90f4b27035cf6f6a9ba5316a14252614e1 -
Trigger Event:
workflow_dispatch
-
Statement type:
File details
Details for the file llmcompressor-0.12.0-py3-none-any.whl.
File metadata
- Download URL: llmcompressor-0.12.0-py3-none-any.whl
- Upload date:
- Size: 298.2 kB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.7
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
e17675737f41861391ee833265e3b96785feace4b96cf099df61119829a00f4d
|
|
| MD5 |
19ef47e1dd21aeeb1d40bb83a4691d0d
|
|
| BLAKE2b-256 |
f960c727d652b9ff6ceed5880ecbe707cdedce728bca961f1ebb664f500e2407
|
Provenance
The following attestation bundles were made for llmcompressor-0.12.0-py3-none-any.whl:
Publisher:
upload.yml on neuralmagic/llm-compressor-testing
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
llmcompressor-0.12.0-py3-none-any.whl -
Subject digest:
e17675737f41861391ee833265e3b96785feace4b96cf099df61119829a00f4d - Sigstore transparency entry: 1824835630
- Sigstore integration time:
-
Permalink:
neuralmagic/llm-compressor-testing@88cf7c90f4b27035cf6f6a9ba5316a14252614e1 -
Branch / Tag:
refs/tags/0.12.0 - Owner: https://github.com/neuralmagic
-
Access:
private
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
upload.yml@88cf7c90f4b27035cf6f6a9ba5316a14252614e1 -
Trigger Event:
workflow_dispatch
-
Statement type:







