A toolset for compressing, deploying and serving LLM

Project description









Latest News 🎉
2026
- [2026/04] PyPI has expanded the storage quota for LMDeploy and wheel uploads have resumed.
v0.12.3is now available on PyPI, so you can install it directly viapip install lmdeploy. - [2026/02] Support Qwen3.5
- [2026/02] Support vllm-project/llm-compressor 4bit symmetric/asymmetric quantization. Refer here for detailed guide
2025
- [2025/09] TurboMind supports MXFP4 on NVIDIA GPUs starting from V100, achieving 1.5x the performmance of vLLM on H800 for openai gpt-oss models!
- [2025/06] Comprehensive inference optimization for FP8 MoE Models
- [2025/06] DeepSeek PD Disaggregation deployment is now supported through integration with DLSlime and Mooncake. Huge thanks to both teams!
- [2025/04] Enhance DeepSeek inference performance by integration deepseek-ai techniques: FlashMLA, DeepGemm, DeepEP, MicroBatch and eplb
- [2025/01] Support DeepSeek V3 and R1
2024
- [2024/11] Support Mono-InternVL with PyTorch engine
- [2024/10] PyTorchEngine supports graph mode on ascend platform, doubling the inference speed
- [2024/09] LMDeploy PyTorchEngine adds support for Huawei Ascend. See supported models here
- [2024/09] LMDeploy PyTorchEngine achieves 1.3x faster on Llama3-8B inference by introducing CUDA graph
- [2024/08] LMDeploy is integrated into modelscope/swift as the default accelerator for VLMs inference
- [2024/07] Support Llama3.1 8B, 70B and its TOOLS CALLING
- [2024/07] Support InternVL2 full-series models, InternLM-XComposer2.5 and function call of InternLM2.5
- [2024/06] PyTorch engine support DeepSeek-V2 and several VLMs, such as CogVLM2, Mini-InternVL, LlaVA-Next
- [2024/05] Balance vision model when deploying VLMs with multiple GPUs
- [2024/05] Support 4-bits weight-only quantization and inference on VLMs, such as InternVL v1.5, LLaVa, InternLMXComposer2
- [2024/04] Support Llama3 and more VLMs, such as InternVL v1.1, v1.2, MiniGemini, InternLMXComposer2.
- [2024/04] TurboMind adds online int8/int4 KV cache quantization and inference for all supported devices. Refer here for detailed guide
- [2024/04] TurboMind latest upgrade boosts GQA, rocketing the internlm2-20b model inference to 16+ RPS, about 1.8x faster than vLLM.
- [2024/04] Support Qwen1.5-MOE and dbrx.
- [2024/03] Support DeepSeek-VL offline inference pipeline and serving.
- [2024/03] Support VLM offline inference pipeline and serving.
- [2024/02] Support Qwen 1.5, Gemma, Mistral, Mixtral, Deepseek-MOE and so on.
- [2024/01] OpenAOE seamless integration with LMDeploy Serving Service.
- [2024/01] Support for multi-model, multi-machine, multi-card inference services. For usage instructions, please refer to here
- [2024/01] Support PyTorch inference engine, developed entirely in Python, helping to lower the barriers for developers and enable rapid experimentation with new features and technologies.
2023
- [2023/12] Turbomind supports multimodal input.
- [2023/11] Turbomind supports loading hf model directly. Click here for details.
- [2023/11] TurboMind major upgrades, including: Paged Attention, faster attention kernels without sequence length limitation, 2x faster KV8 kernels, Split-K decoding (Flash Decoding), and W4A16 inference for sm_75
- [2023/09] TurboMind supports Qwen-14B
- [2023/09] TurboMind supports InternLM-20B
- [2023/09] TurboMind supports all features of Code Llama: code completion, infilling, chat / instruct, and python specialist. Click here for deployment guide
- [2023/09] TurboMind supports Baichuan2-7B
- [2023/08] TurboMind supports flash-attention2.
- [2023/08] TurboMind supports Qwen-7B, dynamic NTK-RoPE scaling and dynamic logN scaling
- [2023/08] TurboMind supports Windows (tp=1)
- [2023/08] TurboMind supports 4-bit inference, 2.4x faster than FP16, the fastest open-source implementation. Check this guide for detailed info
- [2023/08] LMDeploy has launched on the HuggingFace Hub, providing ready-to-use 4-bit models.
- [2023/08] LMDeploy supports 4-bit quantization using the AWQ algorithm.
- [2023/07] TurboMind supports Llama-2 70B with GQA.
- [2023/07] TurboMind supports Llama-2 7B/13B.
- [2023/07] TurboMind supports tensor-parallel inference of InternLM.
Introduction
LMDeploy is a toolkit for compressing, deploying, and serving LLM, developed by the MMRazor and MMDeploy teams. It has the following core features:
-
Efficient Inference: LMDeploy delivers up to 1.8x higher request throughput than vLLM, by introducing key features like persistent batch(a.k.a. continuous batching), blocked KV cache, dynamic split&fuse, tensor parallelism, high-performance CUDA kernels and so on.
-
Effective Quantization: LMDeploy supports weight-only and k/v quantization, and the 4-bit inference performance is 2.4x higher than FP16. The quantization quality has been confirmed via OpenCompass evaluation.
-
Effortless Distribution Server: Leveraging the request distribution service, LMDeploy facilitates an easy and efficient deployment of multi-model services across multiple machines and cards.
-
Excellent Compatibility: LMDeploy supports KV Cache Quant, AWQ and Automatic Prefix Caching to be used simultaneously.
Performance
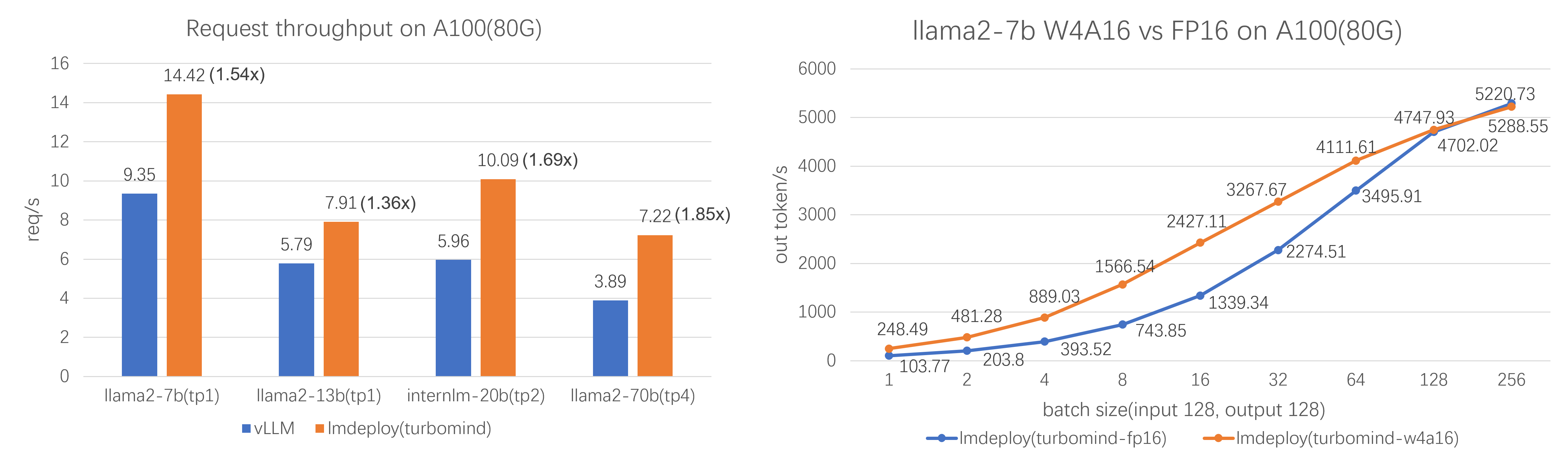
Supported Models
| LLMs | VLMs |
|
|
LMDeploy has developed two inference engines - TurboMind and PyTorch, each with a different focus. The former strives for ultimate optimization of inference performance, while the latter, developed purely in Python, aims to decrease the barriers for developers.
They differ in the types of supported models and the inference data type. Please refer to this table for each engine's capability and choose the proper one that best fits your actual needs.
Quick Start 
Installation
It is recommended installing lmdeploy using pip in a conda environment (python 3.10 - 3.13):
conda create -n lmdeploy python=3.12 -y
conda activate lmdeploy
pip install lmdeploy
Starting from v0.13.0, the default prebuilt wheels published on PyPI are built against CUDA 12.8, so pip install lmdeploy is sufficient for typical setups including GeForce RTX 50 series.
Offline Batch Inference
import lmdeploy
with lmdeploy.pipeline("internlm/internlm3-8b-instruct") as pipe:
response = pipe(["Hi, pls intro yourself", "Shanghai is"])
print(response)
[!NOTE] By default, LMDeploy downloads model from HuggingFace. If you would like to use models from ModelScope, please install ModelScope by
pip install modelscopeand set the environment variable:
export LMDEPLOY_USE_MODELSCOPE=TrueIf you would like to use models from openMind Hub, please install openMind Hub by
pip install openmind_huband set the environment variable:
export LMDEPLOY_USE_OPENMIND_HUB=True
For more information about inference pipeline, please refer to here.
Tutorials
Please review getting_started section for the basic usage of LMDeploy.
For detailed user guides and advanced guides, please refer to our tutorials:
- User Guide
- Advance Guide
Third-party projects
-
Deploying LLMs offline on the NVIDIA Jetson platform by LMDeploy: LMDeploy-Jetson
-
Example project for deploying LLMs using LMDeploy and BentoML: BentoLMDeploy
Contributing
We appreciate all contributions to LMDeploy. Please refer to CONTRIBUTING.md for the contributing guideline.
Acknowledgement
Citation
@misc{2023lmdeploy,
title={LMDeploy: A Toolkit for Compressing, Deploying, and Serving LLM},
author={LMDeploy Contributors},
howpublished = {\url{https://github.com/InternLM/lmdeploy}},
year={2023}
}
@article{zhang2025efficient,
title={Efficient Mixed-Precision Large Language Model Inference with TurboMind},
author={Zhang, Li and Jiang, Youhe and He, Guoliang and Chen, Xin and Lv, Han and Yao, Qian and Fu, Fangcheng and Chen, Kai},
journal={arXiv preprint arXiv:2508.15601},
year={2025}
}
License
This project is released under the Apache 2.0 license.
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distributions
Built Distributions
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file lmdeploy-0.13.0-cp313-cp313-win_amd64.whl.
File metadata
- Download URL: lmdeploy-0.13.0-cp313-cp313-win_amd64.whl
- Upload date:
- Size: 49.5 MB
- Tags: CPython 3.13, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4ab14a90e33489f26a9e93f24ef6894e4b7f00464a110ffed82cc0e78cab7f39
|
|
| MD5 |
562c271b84b9a9659652c9e4e79a8894
|
|
| BLAKE2b-256 |
f99386f64a4b29265d8b88c0cbc410cf2c220cc132aecdfa201ebdcb348be366
|
File details
Details for the file lmdeploy-0.13.0-cp313-cp313-manylinux2014_x86_64.whl.
File metadata
- Download URL: lmdeploy-0.13.0-cp313-cp313-manylinux2014_x86_64.whl
- Upload date:
- Size: 82.1 MB
- Tags: CPython 3.13
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
33c334f29063e7742e4545590f9b158c28f0dd2e428502c909cda43d03a2f20d
|
|
| MD5 |
d8988bb7cc80a990e17034733b848bf3
|
|
| BLAKE2b-256 |
7f70f2d330884e9cc453af40d945987f34747cc5fb5086f86e13b6fc48bc0652
|
File details
Details for the file lmdeploy-0.13.0-cp312-cp312-win_amd64.whl.
File metadata
- Download URL: lmdeploy-0.13.0-cp312-cp312-win_amd64.whl
- Upload date:
- Size: 49.5 MB
- Tags: CPython 3.12, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9887e92751f42925590de60a95a8a17ac564e2ebe82bc568ce9b2313346fc221
|
|
| MD5 |
f8c8ed2e9e2910ccf8296449dc4ba6dc
|
|
| BLAKE2b-256 |
a1ea4be141e5be79ad09b2152a6624c6479f2d78cd116512f9c6e573cca06971
|
File details
Details for the file lmdeploy-0.13.0-cp312-cp312-manylinux2014_x86_64.whl.
File metadata
- Download URL: lmdeploy-0.13.0-cp312-cp312-manylinux2014_x86_64.whl
- Upload date:
- Size: 82.1 MB
- Tags: CPython 3.12
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
c52fb6263dfc88dc0bea9e65619d7d4201b96d8eff39e6214fb484e4d151402c
|
|
| MD5 |
fee1babc74fdae9a0afcf18fb8bd472b
|
|
| BLAKE2b-256 |
53f1ef4f118e8ac7ae1f2e93499d01e79d17d6fe8c25894d92d550611dd57257
|
File details
Details for the file lmdeploy-0.13.0-cp311-cp311-win_amd64.whl.
File metadata
- Download URL: lmdeploy-0.13.0-cp311-cp311-win_amd64.whl
- Upload date:
- Size: 49.5 MB
- Tags: CPython 3.11, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
4af15b37d5bdcbff91694b4041d4e1d36966d4dd4fcfc703fc2163504f52f44f
|
|
| MD5 |
8aa4d5f0935e6d26704400d1ce91abed
|
|
| BLAKE2b-256 |
4cc71aa5f20b97c2015f9e96a5ec311cb34f99259e9235fd96757132291cd217
|
File details
Details for the file lmdeploy-0.13.0-cp311-cp311-manylinux2014_x86_64.whl.
File metadata
- Download URL: lmdeploy-0.13.0-cp311-cp311-manylinux2014_x86_64.whl
- Upload date:
- Size: 82.1 MB
- Tags: CPython 3.11
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
5fc8ea79252725a3f44d311c7e81e4d65db2c3f5b33f6fbcf745c18ff06a11f4
|
|
| MD5 |
2c96046ef568d29653f0ce597b7604b9
|
|
| BLAKE2b-256 |
a80ec9b07c9af5811a7c74d2001a09858d0ca801a7e363bea8bf3e2eaf7336b6
|
File details
Details for the file lmdeploy-0.13.0-cp310-cp310-win_amd64.whl.
File metadata
- Download URL: lmdeploy-0.13.0-cp310-cp310-win_amd64.whl
- Upload date:
- Size: 49.5 MB
- Tags: CPython 3.10, Windows x86-64
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
39efded52e1c690a27310e9f009d9205182197e6076e71f23e3da246b7ae2171
|
|
| MD5 |
75b7d0954f98c09e9fe420c662f6afad
|
|
| BLAKE2b-256 |
ebc1377d52593abe7d405e1dd10e3136e3d4f2dbdb85d119bf79330800ef5820
|
File details
Details for the file lmdeploy-0.13.0-cp310-cp310-manylinux2014_x86_64.whl.
File metadata
- Download URL: lmdeploy-0.13.0-cp310-cp310-manylinux2014_x86_64.whl
- Upload date:
- Size: 82.1 MB
- Tags: CPython 3.10
- Uploaded using Trusted Publishing? No
- Uploaded via: twine/6.2.0 CPython/3.10.20
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
9639f1fbd5b915790bf329439251de36252d08b9faecb4f41f11db8a8157a9af
|
|
| MD5 |
3ef2ee9fd42c26e4a1dc1517813cf5e8
|
|
| BLAKE2b-256 |
e9ec55b1a7b6c96e4b2930d7c2d750f4b0d9452ee709f204c4385f52e60ba4fb
|







