Terminal-based circular plasmid map viewer, sequence editor, and Primer3/Golden Braid primer design workbench
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers

Project description
SpliceCraft








Your whole cloning workflow, in the terminal.
SpliceCraft is a plasmid workbench that runs where you already work. Open a map, edit the sequence, design primers, plan a Golden Braid or MoClo assembly, BLAST a hit, check your Sanger reads, and keep a lab notebook — all from the keyboard, all in one place, no browser tab and no cloud account. Circular and linear maps render as crisp Unicode braille graphics in any modern terminal, and nothing leaves your machine unless you ask it to.
It's built by a practicing bioengineer for daily bench work: the bug reports come from real cloning, and so do the fixes. If you live in a terminal and clone for a living, it's meant to feel like home.
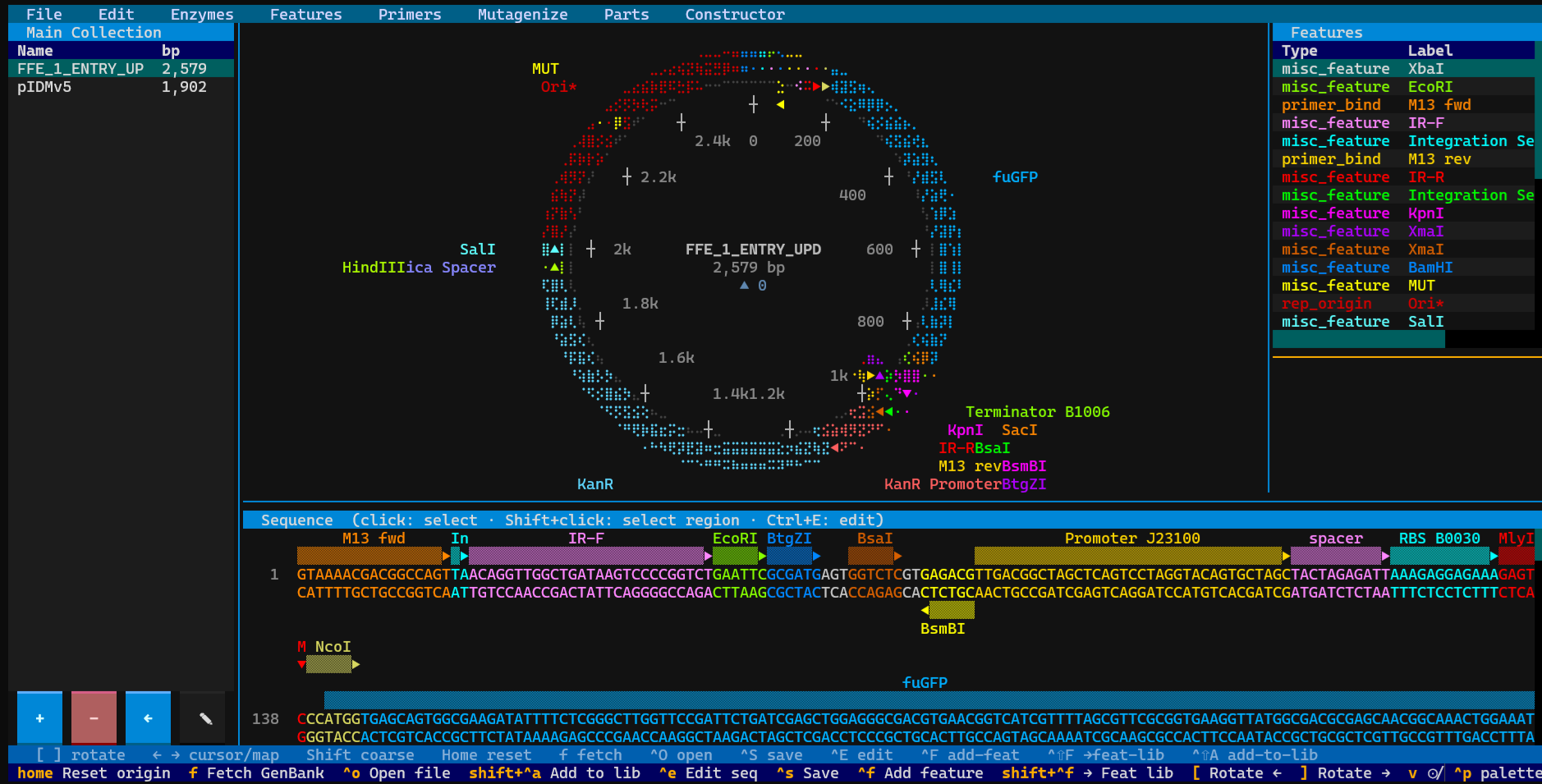
Why give it a try:
- Fast and local. No Electron, no web app, no login.
pipx install splicecraftand you're designing in seconds. - It does the whole job. View → edit → design → clone → simulate → verify → document — one tool that actually understands how those steps connect.
- It guards your data like it's irreplaceable (because it is — see below).
- It's scriptable. A 100+ endpoint local API and a stdlib CLI let an agent or a shell script drive every workflow.
Quick start
pipx install splicecraft
splicecraft # empty canvas
splicecraft L09137 # fetch pUC19 from NCBI on launch
splicecraft myplasmid.gb # local GenBank or .dna
Press ? once running for the full keyboard-shortcut reference. See
docs/install.md for pip / uv / conda / source installs.
A workhorse that just works
Your plasmid library is the product of months — sometimes years — of work. SpliceCraft is engineered so it can be your daily driver without ever making you nervous about it. Three promises, and the receipts behind them:
Your data is sacred. Every save runs through a four-layer safety net: an
atomic write (a crash can never leave a half-written file), a .bak plus
rotating timestamped backups, a daily snapshot, and a "suspicious shrink"
guard that flat-out refuses to replace a 156 MB library with an empty file.
Open a file that collides with something you already have and SpliceCraft
asks — skip, keep a copy, or overwrite — it never clobbers your work behind
your back. Before any self-update it snapshots everything to a sibling
directory first, so even a hypothetical bug in a new version can't take your
recovery copy with it.
The biology is correct, and we prove it. Restriction scanning handles
palindromes, Type IIS enzymes, and origin-spanning cut sites the way a bench
scientist expects; features that wrap the origin survive every edit;
translation (including non-standard genetic codes via /transl_table),
reverse-complement, and IUPAC matching are pinned down to the base.
Selection markers are read from the actual entry vector you're using —
no hardcoded antibiotics quietly mislabeling a construct. There are
4,000+ automated tests behind all of it, plus property-based fuzzing on
the biology primitives, crash-injection tests on the save path, and
concurrency fuzzing on the data layer. Every release ships only when the
whole suite is green.
We go looking for trouble. The codebase is governed by a long list of
"sacred invariants" (documented in CLAUDE.md), and each
release is preceded by deep, multi-pass audits hunting for edge cases,
data-loss windows, race conditions, and security gaps — with every finding
verified against the real code before a line is changed. The short version:
it's a workhorse, and it goes to real lengths to keep "it just works" true.
Full data-safety writeup: docs/data-safety.md ·
Security policy: SECURITY.md.
A guided tour
Everything lives behind a menu bar across the top of the screen. Here's the tour — starting with BLAST and working rightward across the bar, with the housekeeping menus (File, Settings) saved for last.
BLAST
Search without leaving the app (Ctrl+B). The Local tab runs BLASTN /
BLASTP / HMMscan against your own library with an in-process engine — powered
by pyhmmer, so there's no external blast+ to install — and a one-click
downloader pulls Pfam-A or NCBIfam (or any HMMER3 .hmm.gz URL) with
automatic update-detection, no wget + hmmpress ritual. On native Windows,
BLASTN/BLASTP run in-process but HMMscan needs WSL2 (pyhmmer/HMMER is
POSIX-only). The Online tab
sends DNA / RNA / protein — or a whole plasmid or a single feature straight
from your library — to NCBI (blastn / blastp / blastx / tblastn / tblastx) or
to Pfam at EMBL-EBI, and drops the hits into a scrollable table just like a
web BLAST. A live spinner and poll counter prove the search is really running,
and Cancel actually stops it.
Enzymes
Drive the restriction overlay: show all sites, unique cutters only, 6+ or 4+ bp recognition, or just the Golden Braid connectors. Build enzyme collections — named subsets of the master catalog (200+ NEB enzymes plus your own customs) — and the active collection scopes every scan. Add a custom enzyme (name, site, cut positions, type, supplier) and it's live in every map from then on.
Features
A workbench for your reusable annotations — promoters, RBSs, tags, CDSs. Capture a region off any plasmid into the feature library, then drop it back onto another construct to either annotate a selection or splice the sequence in. It's the same store the Synthesis editor and Domesticator pull from, so your parts stay consistent everywhere.
Marking things up by hand? Ctrl+F finds a DNA subsequence — fuzzy, so
you can allow a few mismatches, and on both strands — then n / N step
through every hit. Each match lands pre-selected, so Alt+Shift+F tags it
as a feature on the spot: ideal for walking a plasmid and annotating repeat
regions one by one. (Looking for an existing annotation instead? Ctrl+/
searches your features by name.)
Primers
A full-screen Primer3 designer covering detection, cloning, Golden Braid, and generic primers — each with a persistent Designed → Ordered → Validated lifecycle, so you can see at a glance what's been ordered and what came back working, right alongside the plasmid it belongs to.
Mutato
Site-directed mutagenesis, with a hint of whimsy in the name. Point at any
CDS, name the change (say, L54A), and SpliceCraft designs the SOE-PCR
primers for you — with a smart fallback to a 2-primer modified-outer strategy
when a near-the-end mutation can be folded into a single primer. It checks
its own work, too: the shortcut is only offered when the primer genuinely
carries the change, so you never amplify wild-type by accident. It also turns a
pasted protein into a ready-to-order CDS — frequency-matched codon optimization
against your chosen table, with a stops selector (1–3) that also honors a
trailing * run when you want a double or triple stop codon, and an Avoid
sites picker that scrubs your chosen restriction-enzyme cut sites out of the
optimized CDS.
Its second tab, Scrub, cures a whole plasmid of restriction sites without any cloning. Pick the enzymes to remove (Golden Gate / MoClo Type IIS sites by default) and SpliceCraft finds the smallest set of point changes that destroy each site — silent ones inside any coding sequence, checked against every overlapping reading frame so a protein never changes (and biased toward your chosen codon table's frequent synonyms when there's a choice), and minimal swaps elsewhere — without ever spawning a new forbidden site. You get the cured circular plasmid (one click to apply, fully undoable), an improved-QuikChange primer pair per locus designed off the cured sequence so it binds exactly where it's drawn — save it to your primer library or add it straight to the map — with the PCR → DpnI → transform recipe (no ligase, no fragment assembly) shown alongside. Sites it can't remove silently are reported, never forced.
Synthesis
A gene-synthesis composer with two tabs. The DNA tab is a
horizontally-scrolling linear editor with anti-parallel strand markers, live
feature stripes, restriction overlay, and AA translation, plus a feature
library side-pane (Insert to splice, Annotate to overlay). The Protein
tab lets you type or paste amino acids and watch the codons appear underneath
using your chosen codon table — pick a different one or hit Manage to fetch
one from Kazusa, import your own as a TSV, or delete one, all from the dropdown
and reflected live — and a built-in motif library (His6, FLAG, HA, TEV,
P2A, NLS, GS linkers, and ~30 more) inserts pre-colored tags. Hit Optimize →
DNA to codon-optimize the protein (with the same stop-count and Avoid
sites controls as Mutato) and hand the CDS straight to the DNA tab as an
editable fragment. Or hit Open to
load a sequence straight from a single-entry FASTA (or other amino-acid file) — a
file browser highlights the loadable formats in pink. Compose a part,
hit Clone Fragment, and it's handed straight to the Domesticator as an L0
building block. When you save the domesticated part, one dialog names — and independently
files — three things: the cloned plasmid (into any collection), the
linear fragment you'd send for a DNA-synthesis order (its own name,
defaulting to a FRAG-… form, into any collection), and which parts bin
the L0 part files into. The fragment is the primed amplicon — the insert
flanked by the designed domestication primers' enzyme sites + overhangs, exactly
as it would run on the bench — and both the fragment and the clone carry the
domestication primers, drawn with their bound (annealing + overhang) and
unbound (enzyme-tail) regions, so you can see exactly how each was built (and
regenerate the amplicon later for a synthesis order).
Save (and Save As, which forks a copy and only lights up once the
fragment has been saved once) let you pick which collection the fragment lands
in, and keep editing it there.
Parts
Your Parts Bin — the Level-0 building blocks for grammar-based assembly, organized into per-grammar bins. Multiple bins live side by side as Parts Bin collections, so a yeast toolkit and a plant toolkit never get mixed up.
Constructor
Where it all comes together. A multi-tab assembly bench — Traditional cloning, Gibson, Golden Braid, MoClo, or your own custom grammar — driven by a 4-source part picker. Every assembly, at every level, lands as one complete library entry (payload + overhangs + backbone) that carries every parent feature forward, so you can trace a finished L3 construct all the way back to its L0 parts right from the Library panel.
Simulator
In-silico PCR and agarose gels. Pick a template from your library, run the
PCR, then save the amplicon back to the library or send it to a gel lane.
Gels render at 0.5–4% with a real Helling–Goodman–Boyer mobility curve; stack
several amplicons side by side, save the whole gel to reload later, or cite
it as &<gel> in your lab notebook.
Sequencing
Verify your constructs against real reads. Drop in a Plasmidsaurus .zip and
walk three numbered tabs — pick the run, pick the sample, pick the target
plasmid — then Align. The read lands as a colored bar on the plasmid's
linear map (blue match / red mismatch / gray gap) with its name painted
right onto the bar so a multi-read pile-up stays readable. Zoomed all the
way out, each cell is shaded by how much of its span actually binds —
solid blue where it matches, a red shade that deepens with the mismatch
density, gray for gaps — so a partially-binding read reads as a blue/red/
gray patchwork and even a single-base mismatch still shows red in its
region. Click anywhere on a read's bar to jump the sequence panel to
that exact spot — centered and highlighted — so you can land on a
misaligned stretch (or the precise base to re-edit) without scrolling;
the full per-base alignment view is still a keystroke away in the
Alignment Manager. Bulk auto-align
matches a whole results folder against your library in one pass — and its
confirm window shows each read's real identity, mismatched-base, and gap
counts (computed by actually aligning, not just the name/k-mer match
score), ready when the window opens so you can see how clean every read is
before you commit. The
Verification Report grades every construct (✓ verified / ⚠ near-match /
~ partial / ✗ divergent) in one sortable table — click a row to jump to the
first variant. The Alignment Manager lists every stored alignment with
its identity, mismatched-base count, and gap count, so one glance tells you
how clean each read is — and an identity that isn't a true 100% never rounds
up to "100%" (a single off-by-one base reads as e.g. 99.99%, not a false
perfect score). The Library panel even shows a per-plasmid Seq badge so
you can see what's been verified at a glance, alongside a Kind badge
(○ plasmid · / fragment · ≈ amplicon · ρ protein) telling you what
each entry is.
Experiments
A genuine lab notebook, in markdown. A split-pane editor, entries grouped
into projects (the way plasmids group into collections), and live colored
cross-references — type @plasmid, !action, or &gel and double-click (or
Ctrl+G) to jump straight to the source. Attach images, and spellcheck with
F7 against a dictionary you can grow.
History
Every plasmid you build through SpliceCraft remembers how it was made —
whether you cloned it via Golden Braid, traditional digest/ligation, Gibson,
or PCR, or just edited and saved it. History opens with a Protocol
summary — a numbered recipe that reads left → right like the bench ("assemble
pProm + pCDS_GFP + pTerm into pENTR_L1 → TU_GFP ✂ Esp3I", with a symbol
legend) — above a lineage tree that opens collapsed to the finished plasmid
and its direct inputs and lets you drill in as deep as you like. Selecting a
step shows its detail, including the primers used for a PCR. A backbone or
part reused across branches is shown once and then referenced, so even a
multi-part Golden Braid / MoClo build reads at a glance. The same history rides
along when you import or re-export a CommercialSaaS .dna file. "How did I make
this again?" is always one keystroke away.
File & Settings
The housekeeping. File opens local files, fetches from NCBI, saves,
exports (GenBank / FASTA / GFF3), bulk-imports a folder, and restores from
backup — and it's home to Master Delete, a triple-gated full wipe for
when you genuinely want a clean slate (typed YES, a default-No confirm, and
a cool-down on the button; no shortcut, no API). Settings collapses every
toggle (restriction overlay, primer-binding length, and more) into one dialog,
with launchers for the grammar, entry-vector, enzyme-collection, and
codon-table editors.
Want to drive all of this from a script or an agent? There's a 100+ endpoint
localhost JSON API (splicecraft --agent) and a stdlib-only CLI sidecar
(splicecraft-cli) — see docs/agent-api.md and
docs/cli.md.
Full feature reference: docs/features.md.
Documentation
| Topic | Where |
|---|---|
| Install methods | docs/install.md |
| First five seconds with pUC19 | docs/getting-started.md |
| Full feature list | docs/features.md |
| Keybindings + menus | docs/keybindings.md |
| Data safety + backups | docs/data-safety.md |
| Agent API (HTTP) | docs/agent-api.md |
| CLI sidecar | docs/cli.md |
| Architecture | docs/architecture.md |
| Sacred invariants | CLAUDE.md |
| Contributing | CONTRIBUTING.md |
| Security policy | SECURITY.md |
| v1.0.0 acceptance gate | V1_GATE.md |
| Changelog | CHANGELOG.md |
| Release checklist | RELEASE_CHECKLIST.md |
Tests
python3 -m pytest -n auto -q # full suite (~5–6 min on 8 cores)
python3 -m pytest tests/test_dna_sanity.py # biology correctness only (< 2 s)
python3 -m pytest tests/test_perf_regression.py # perf gates (~3 s)
All tests run offline against synthetic SeqRecords and monkeypatched data
paths; the autouse _protect_user_data fixture in tests/conftest.py
guarantees no test can write to real user files.
Maintenance
SpliceCraft is actively maintained. The maintainer is a practicing bioengineer running real cloning workflows in it daily; releases typically go out the same week a problem surfaces at the bench. Issues and PRs welcome at github.com/Binomica-Labs/SpliceCraft/issues.
See CONTRIBUTING.md before opening a non-trivial PR — it
walks through the sacred invariants, the test cadence, and the
security-sensitive code surfaces.
License
MIT
Project details
Verified details
These details have been verified by PyPIProject links
GitHub Statistics
Maintainers
Release history Release notifications | RSS feed


Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages.
Source Distribution
Built Distribution
Filter files by name, interpreter, ABI, and platform.
If you're not sure about the file name format, learn more about wheel file names.
Copy a direct link to the current filters
File details
Details for the file splicecraft-1.0.17.tar.gz.
File metadata
- Download URL: splicecraft-1.0.17.tar.gz
- Upload date:
- Size: 2.9 MB
- Tags: Source
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
ad0c48de8c9eb81c24ac1534aeafb99ab76d94272192029f9fd8a3630d6cf775
|
|
| MD5 |
363b5a5a4eb3dda2f7e0f01c34bf3299
|
|
| BLAKE2b-256 |
789efec683fb60958151e5db70f5912ad04c174b3d16ac6b9c94e5043e57d42f
|
Provenance
The following attestation bundles were made for splicecraft-1.0.17.tar.gz:
Publisher:
publish.yml on Binomica-Labs/SpliceCraft
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
splicecraft-1.0.17.tar.gz -
Subject digest:
ad0c48de8c9eb81c24ac1534aeafb99ab76d94272192029f9fd8a3630d6cf775 - Sigstore transparency entry: 1707834430
- Sigstore integration time:
-
Permalink:
Binomica-Labs/SpliceCraft@b8447fe51ed755031699f33ab1b6779cb5e6350a -
Branch / Tag:
refs/tags/v1.0.17 - Owner: https://github.com/Binomica-Labs
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@b8447fe51ed755031699f33ab1b6779cb5e6350a -
Trigger Event:
push
-
Statement type:
File details
Details for the file splicecraft-1.0.17-py3-none-any.whl.
File metadata
- Download URL: splicecraft-1.0.17-py3-none-any.whl
- Upload date:
- Size: 1.6 MB
- Tags: Python 3
- Uploaded using Trusted Publishing? Yes
- Uploaded via: twine/6.1.0 CPython/3.13.12
File hashes
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 |
f7aa720feb5fdf5201b95fd438c3d2670596c1d36c766d00167ff2789ee55257
|
|
| MD5 |
6fb383591a103c63f38c30e7cd92d7d4
|
|
| BLAKE2b-256 |
bafff11ab946a0e0a4381710ddb3c54004de8b6bb3f35262357b8f7d4eebf7e8
|
Provenance
The following attestation bundles were made for splicecraft-1.0.17-py3-none-any.whl:
Publisher:
publish.yml on Binomica-Labs/SpliceCraft
-
Statement:
-
Statement type:
https://in-toto.io/Statement/v1 -
Predicate type:
https://docs.pypi.org/attestations/publish/v1 -
Subject name:
splicecraft-1.0.17-py3-none-any.whl -
Subject digest:
f7aa720feb5fdf5201b95fd438c3d2670596c1d36c766d00167ff2789ee55257 - Sigstore transparency entry: 1707834477
- Sigstore integration time:
-
Permalink:
Binomica-Labs/SpliceCraft@b8447fe51ed755031699f33ab1b6779cb5e6350a -
Branch / Tag:
refs/tags/v1.0.17 - Owner: https://github.com/Binomica-Labs
-
Access:
public
-
Token Issuer:
https://token.actions.githubusercontent.com -
Runner Environment:
github-hosted -
Publication workflow:
publish.yml@b8447fe51ed755031699f33ab1b6779cb5e6350a -
Trigger Event:
push
-
Statement type:







